Download to read offline














![21
+ Sctool
+ Cluster
+ Repair
+ Task
+ POSIX compliant
+ BASH completion
+ Prints tables :)
$ sctool repair -h
Manage repairs
Usage:
sctool repair [command]
Available Commands:
progress Shows repair progress
schedule Schedule repair of a unit
unit Manage repair units
Flags:
-h, --help help for repair
Global Flags:
--api-url URL URL of Scylla Manager server (defau
-c, --cluster name target cluster name or ID
Use "sctool repair [command] --help" for more information](https://image.slidesharecdn.com/scyllamanagerwebinar1-180426184430/75/Introducing-Scylla-Manager-Cluster-Management-and-Task-Automation-21-2048.jpg)
![Register a cluster to Scylla Manager
$ sctool repair unit list
╭──────────────────────────────────────┬──────────────────────┬──────────────────────┬────────╮
│ unit id │ name │ keyspace │ tables │
├──────────────────────────────────────┼──────────────────────┼──────────────────────┼────────┤
│ 27b75126-605e-4238-9e6c-a2cec097d2c4 │ super_important_data │ super_important_data │ [] │
│ 40f9a7f3-4c63-4abb-8044-5397e36e1960 │ important_data │ important_data │ [] │
│ 4a694d40-4e50-4b05-9a45-3f0fe2c0f00a │ very_important_data │ very_important_data │ [] │
╰──────────────────────────────────────┴──────────────────────┴──────────────────────┴────────╯](https://image.slidesharecdn.com/scyllamanagerwebinar1-180426184430/75/Introducing-Scylla-Manager-Cluster-Management-and-Task-Automation-23-2048.jpg)




The document discusses Scylla Manager, a tool for managing Scylla clusters and automating tasks such as data repair to ensure data consistency across nodes. It highlights the importance of a recurrent repair solution and provides an overview of the features, including user-friendly CLI tools (sctool), centralized control, and integration with Prometheus for monitoring. The document also outlines the development team behind Scylla Manager, including Michal Matczuk and Tzach Livyatan, and their backgrounds in software engineering and product management.
Presenters Michał Matczuk (Scylla Manager Lead Developer) and Tzach Livyatan (Product Manager) introduced the webinar on Scylla's Cluster Management and Task Automation.
Discussion on the need for recurrent repair solutions in Scylla Manager, its status, roadmap, features like 24/7 support, and enterprise functionalities.
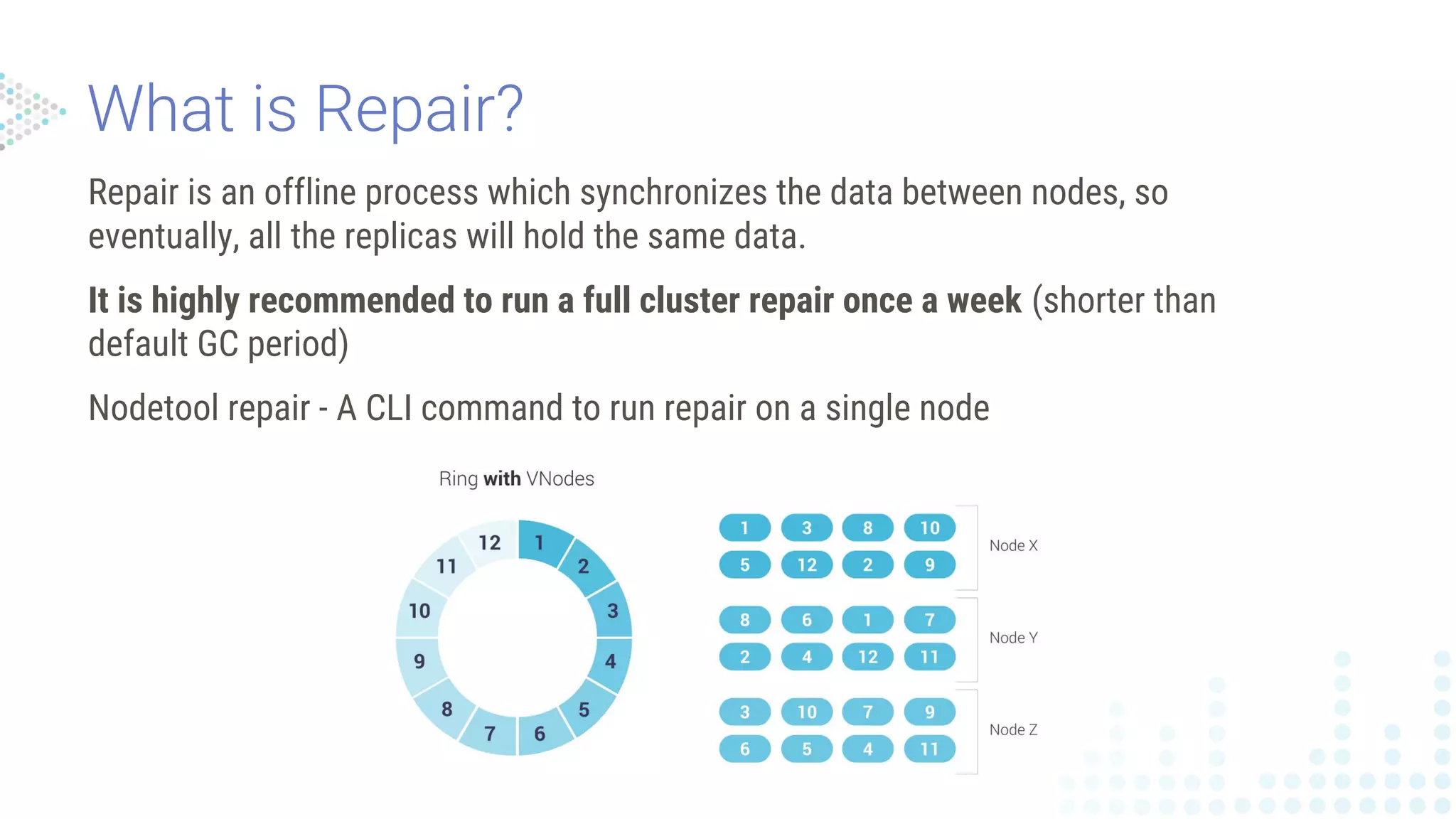
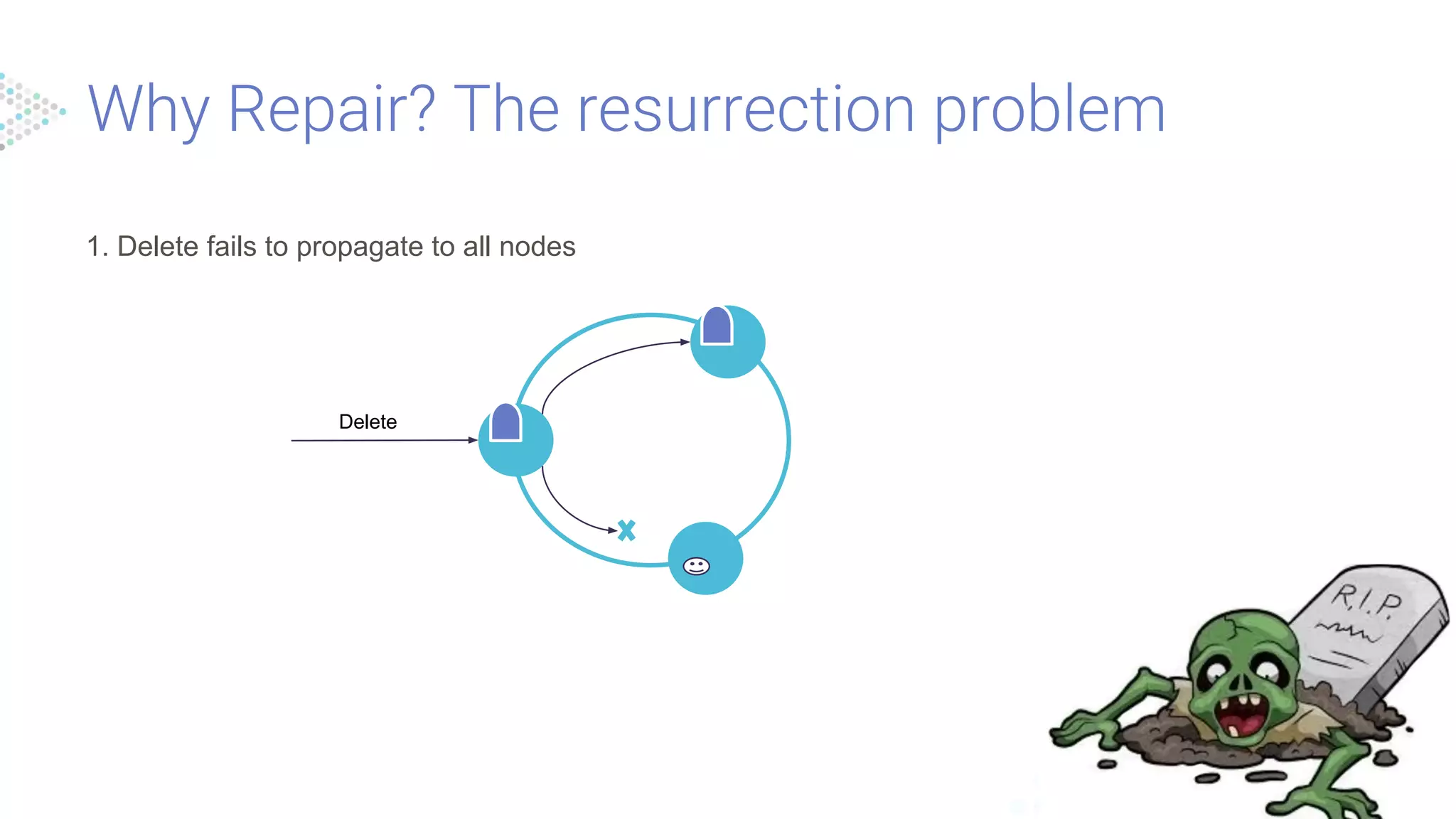
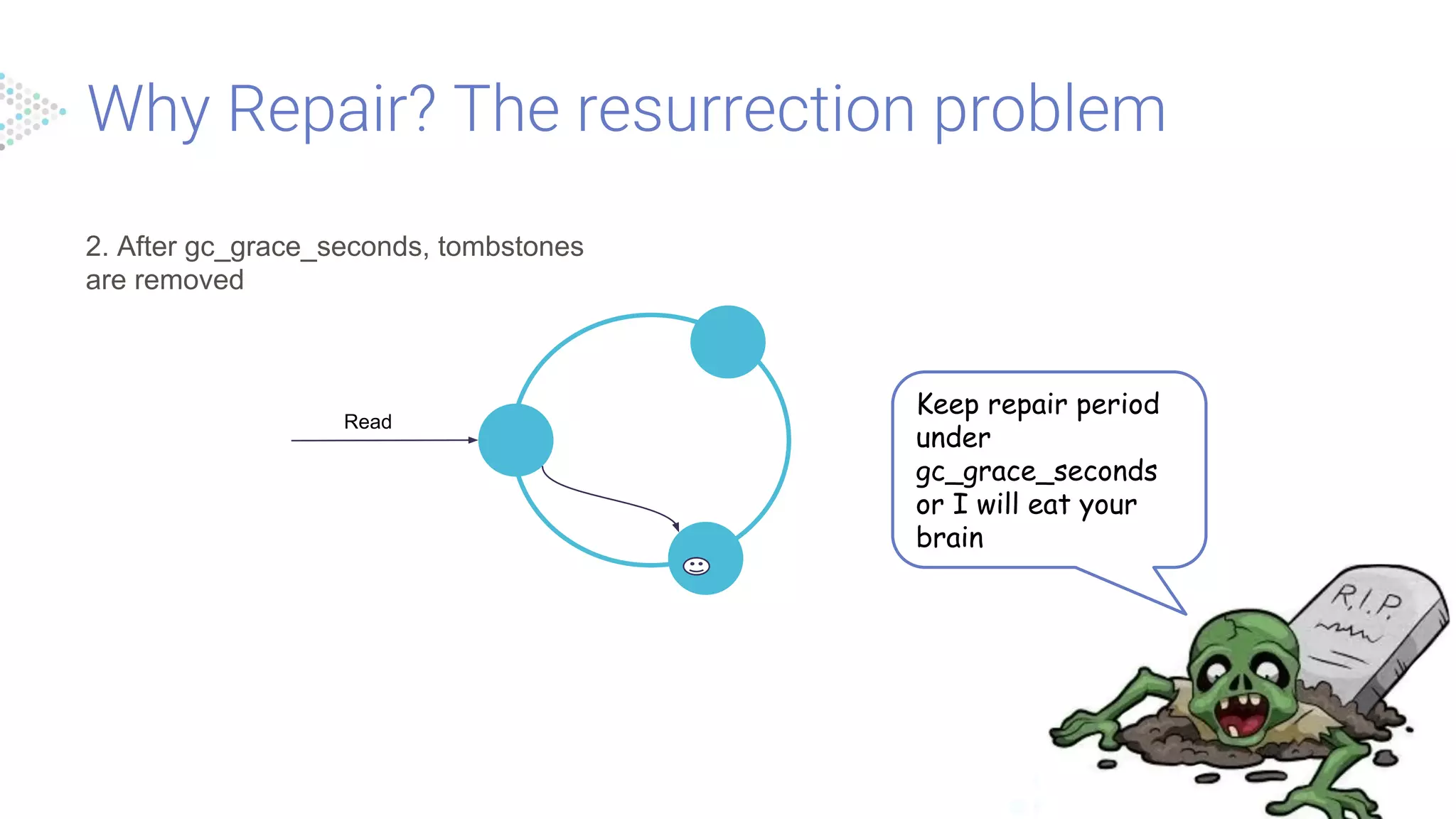
Challenges in data consistency due to node sync issues, with solutions like periodic repairs recommended to maintain data integrity in Scylla clusters.
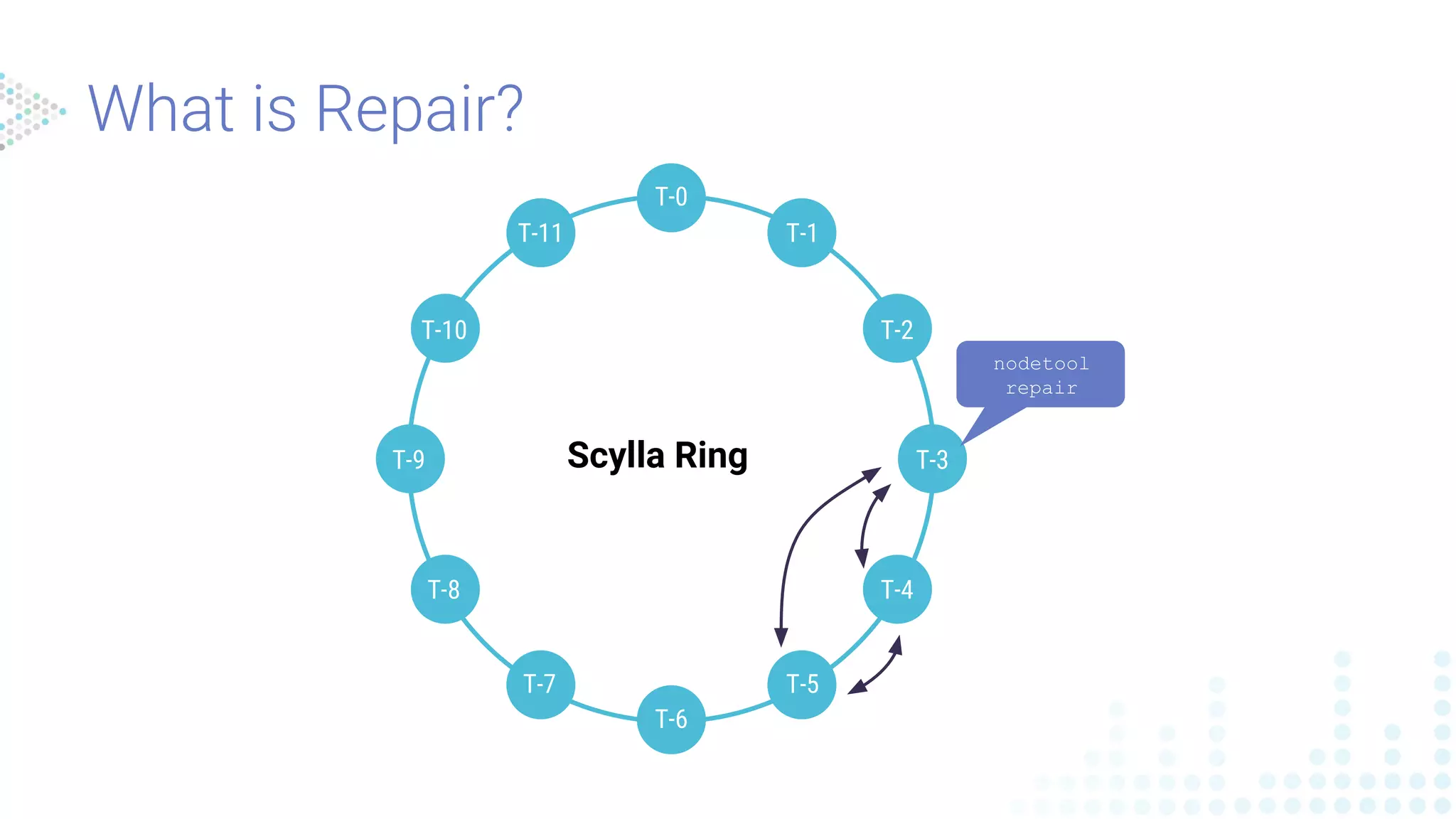
Explains the offline repair process for data synchronization across nodes, including important commands and reminders on data propagation.
Different strategies for running repairs: from automated solutions to manual interventions, highlighting limitations of current solutions.
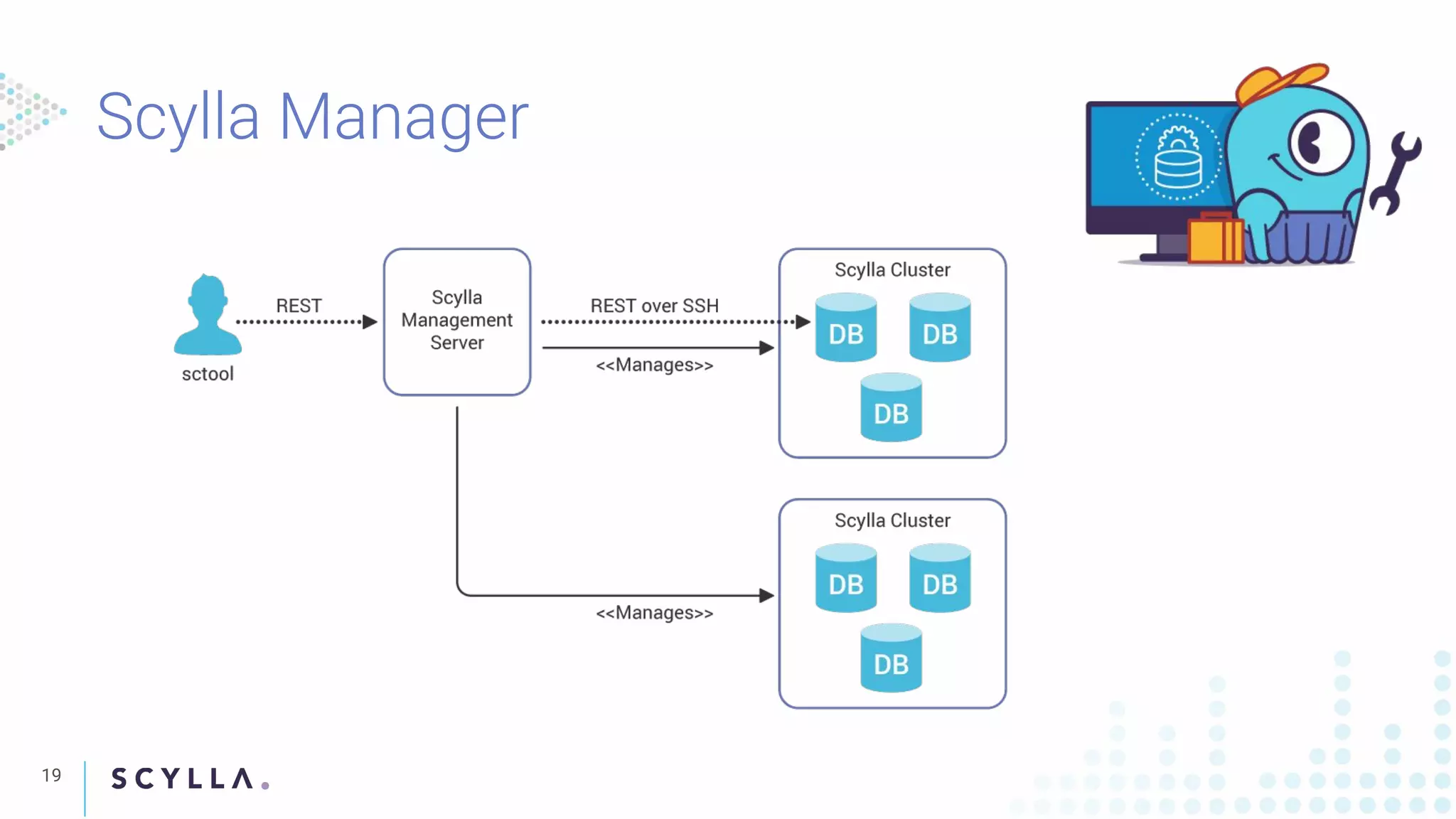
Introducing Scylla Manager as a centralized tool for managing multiple clusters with features like automated repairs, user-friendly CLI, and high availability.
Overview of 'sctool', its functionalities, including REST APIs, Grafana integration, and metrics exporting capabilities.
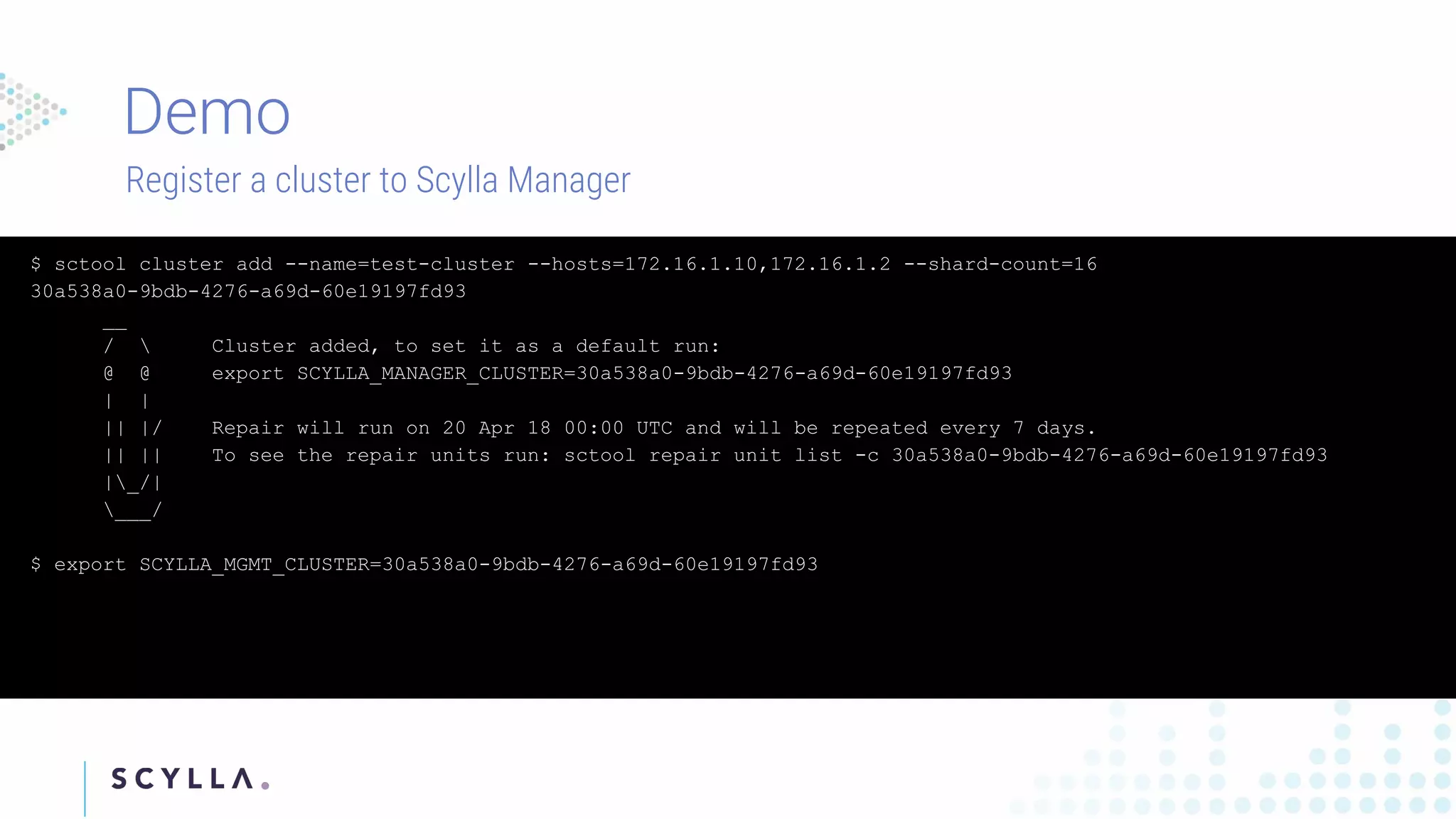
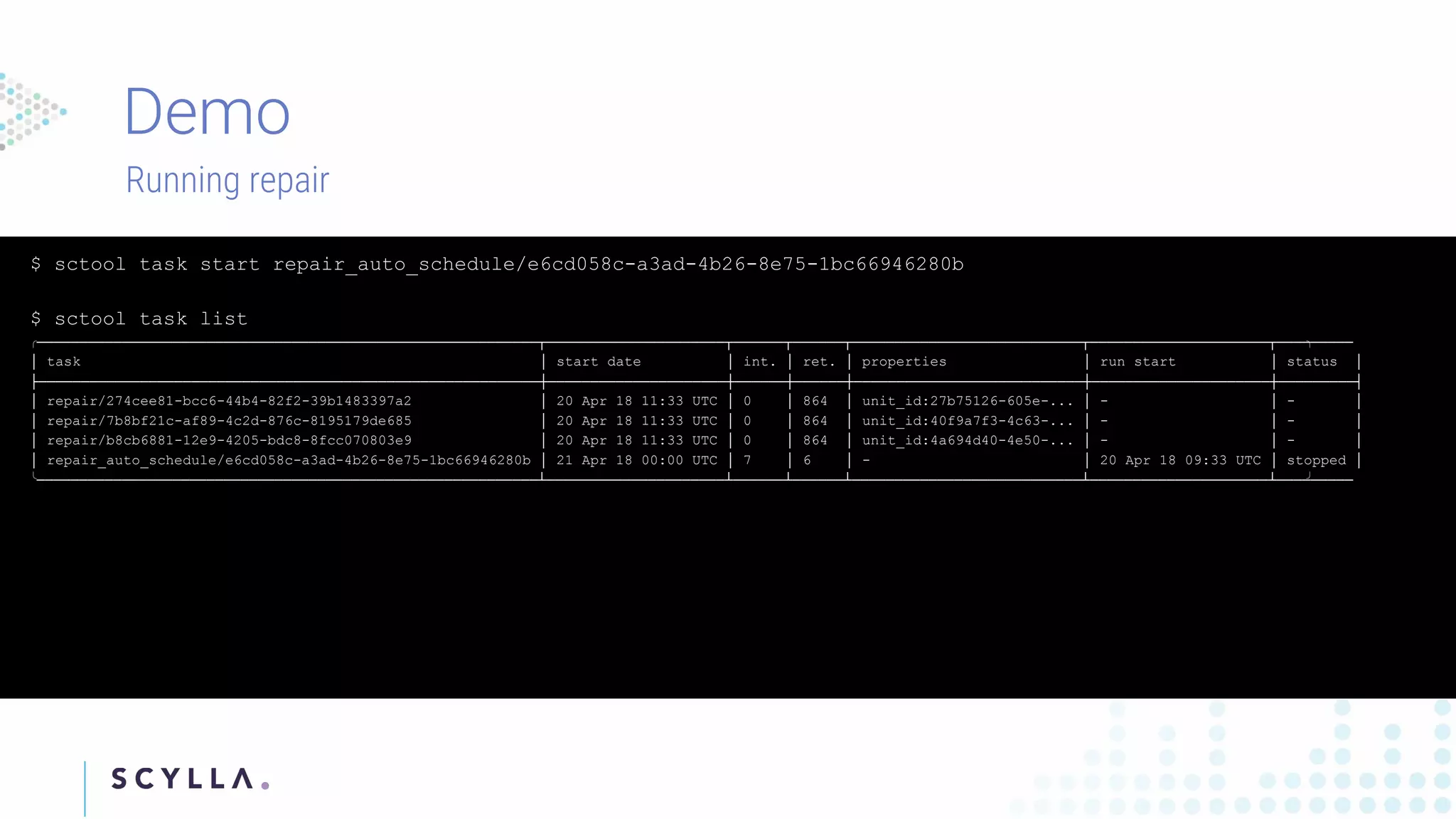
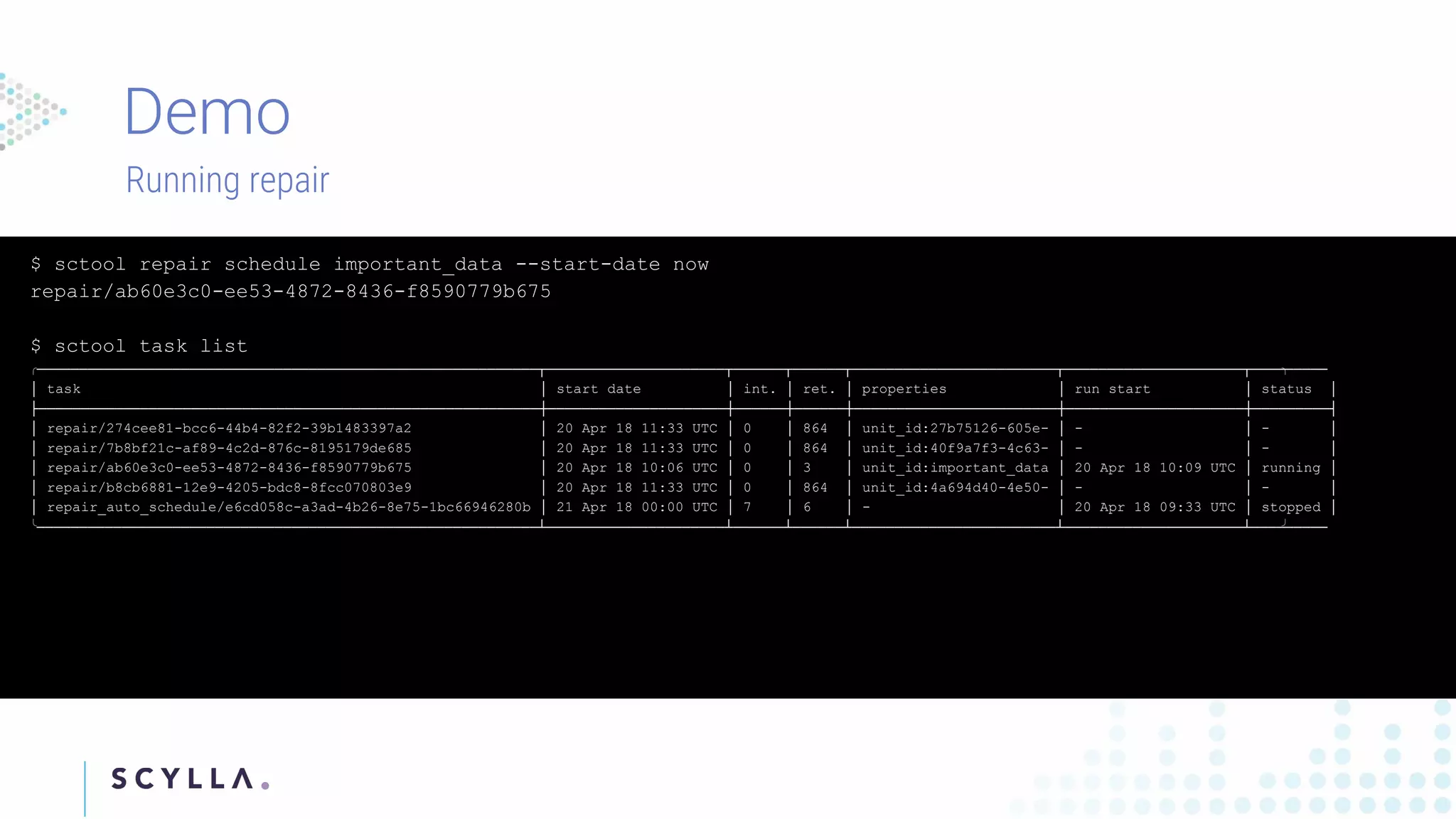
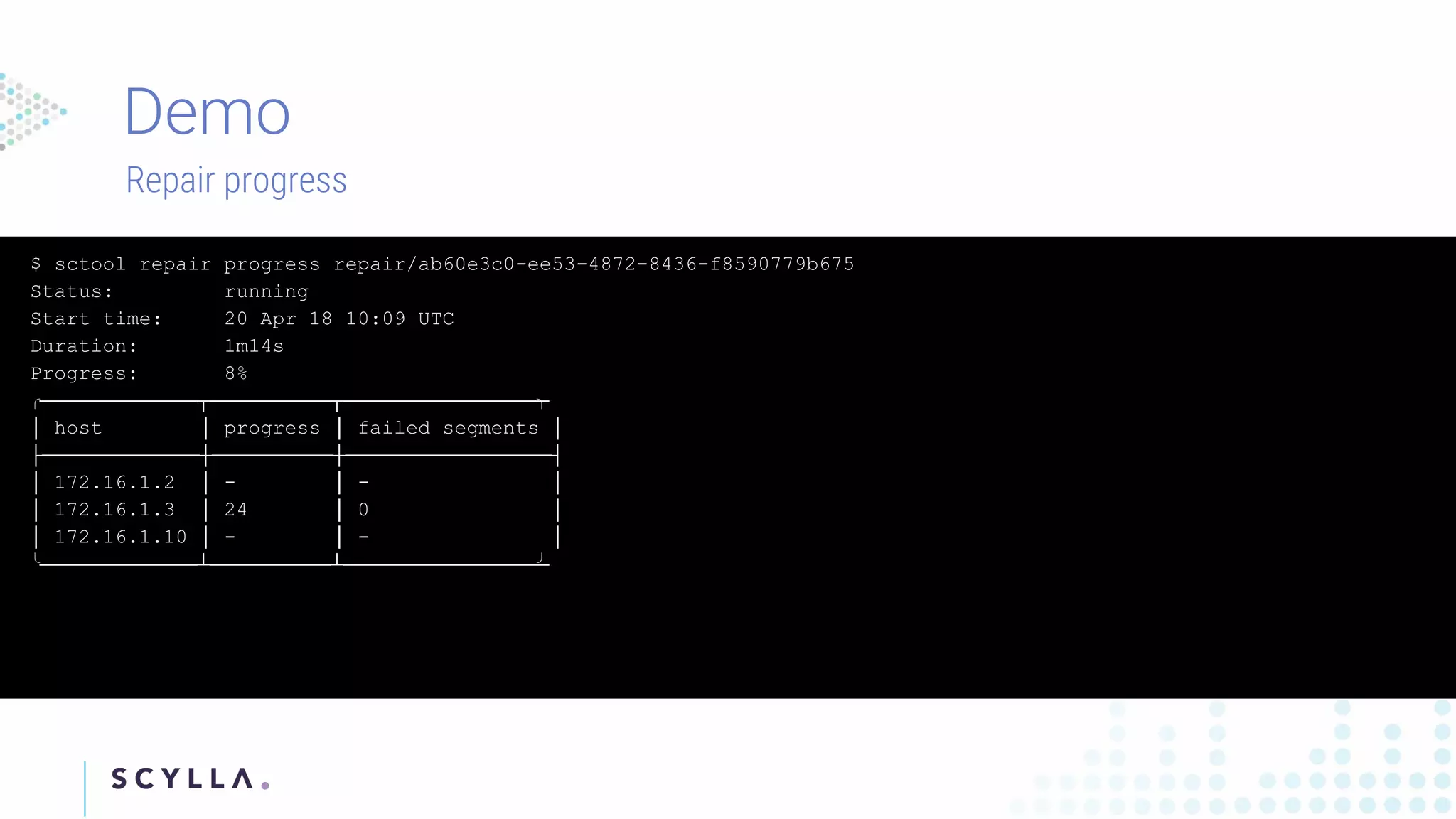
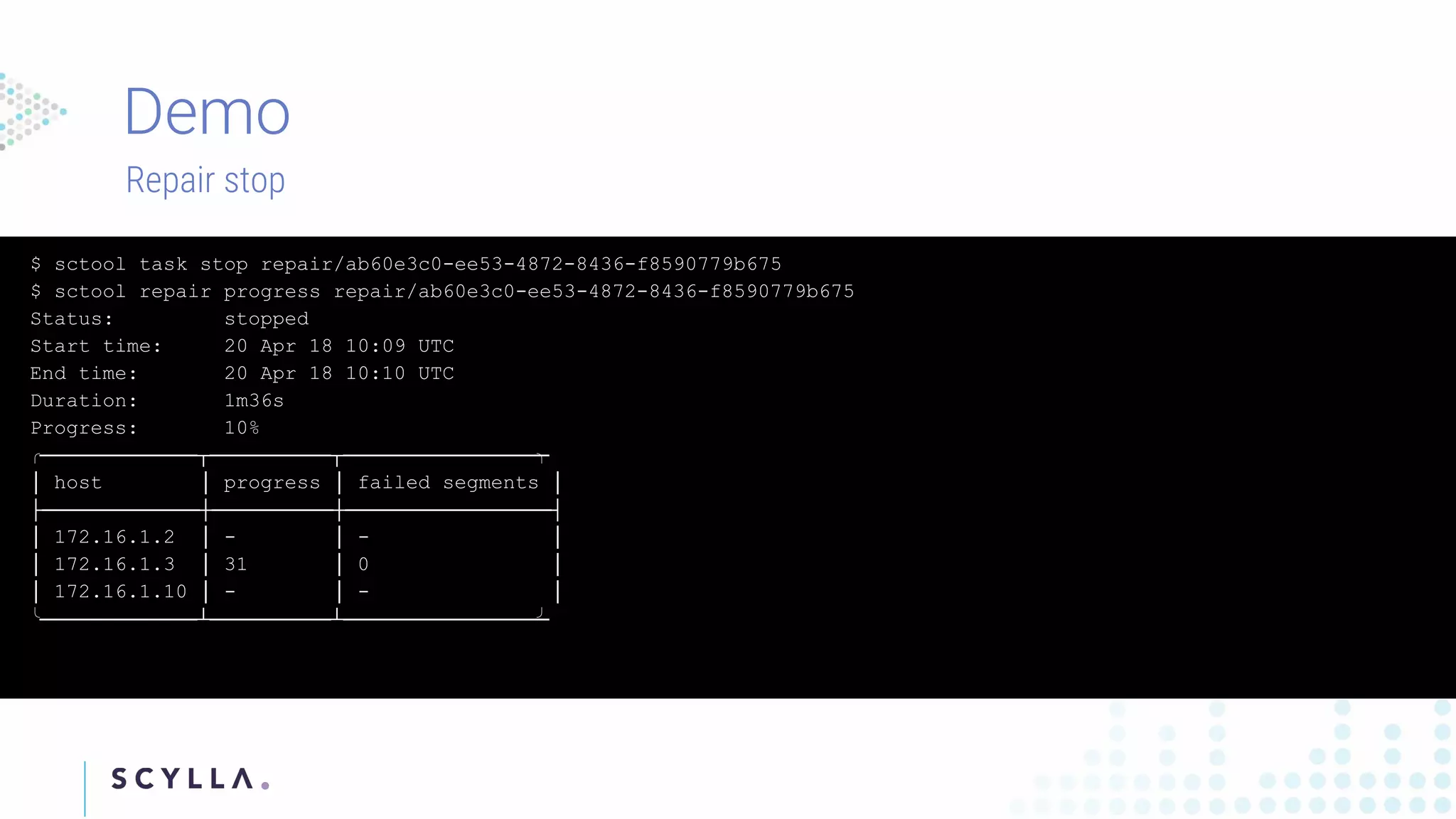
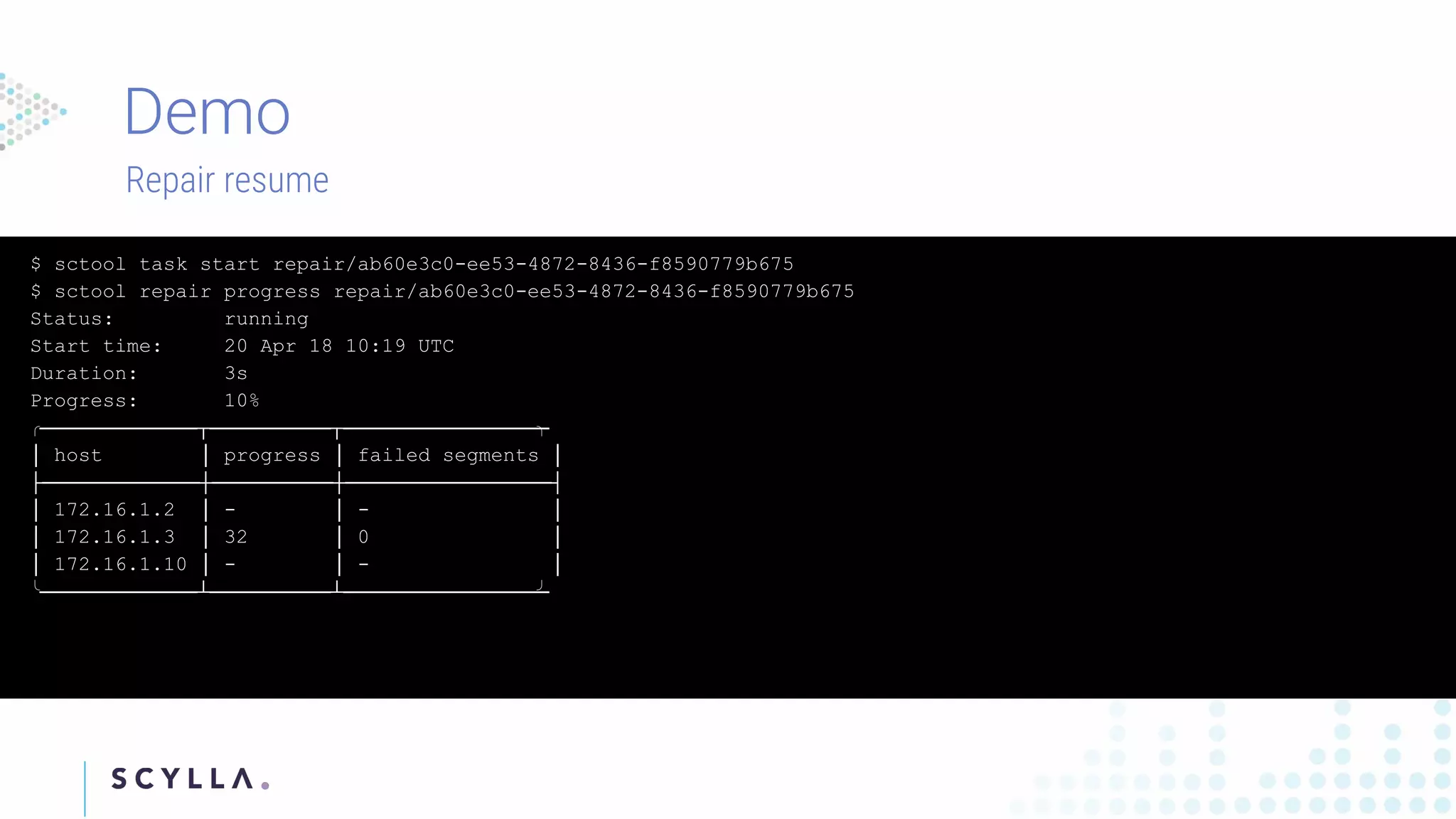
Instructions on registering clusters to Scylla Manager and how to manage repair tasks with status updates and progress tracking. Commands to check diagnostics on repair tasks, including start, stop, and resume functionalities, ensuring efficient management.
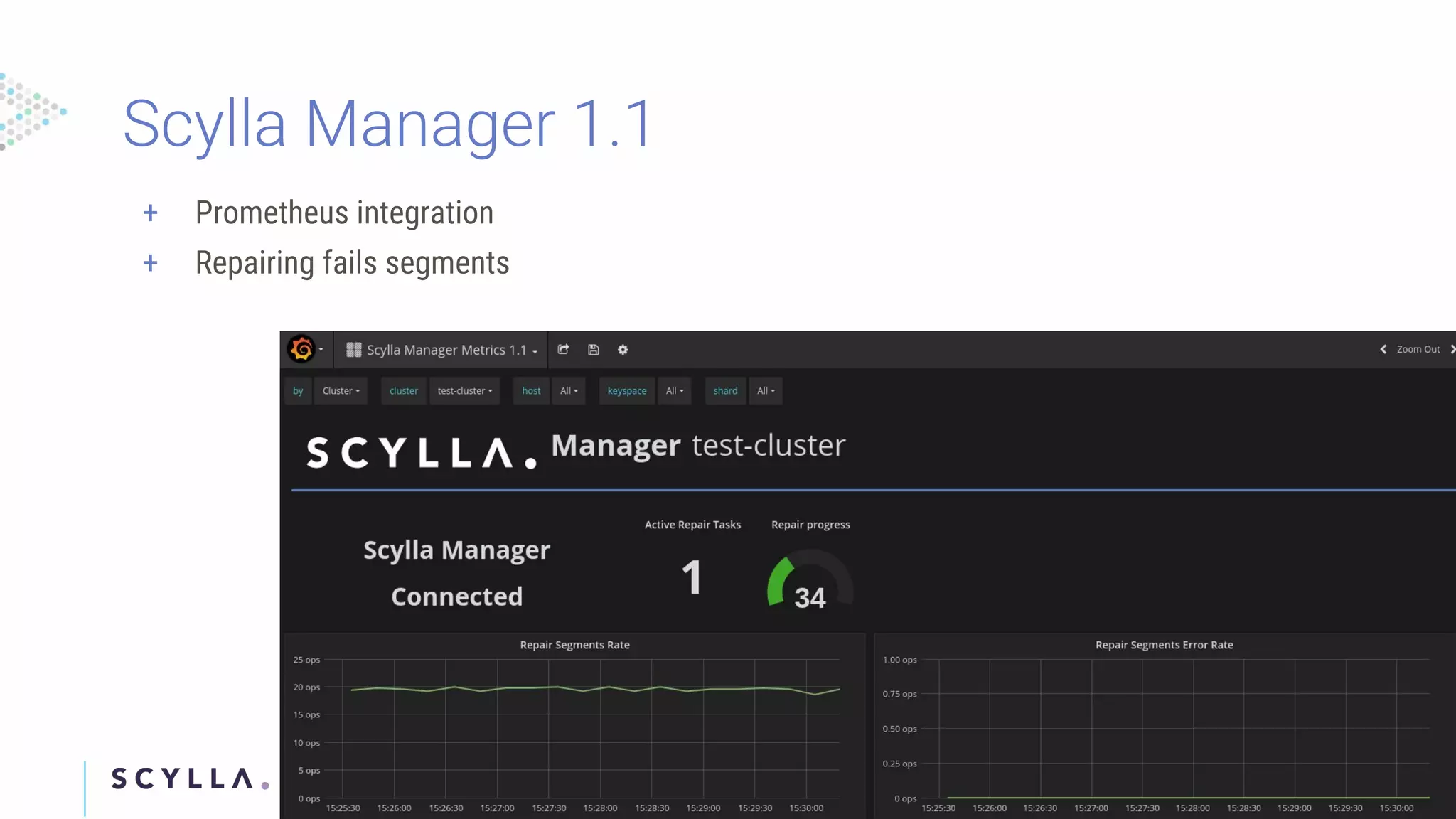
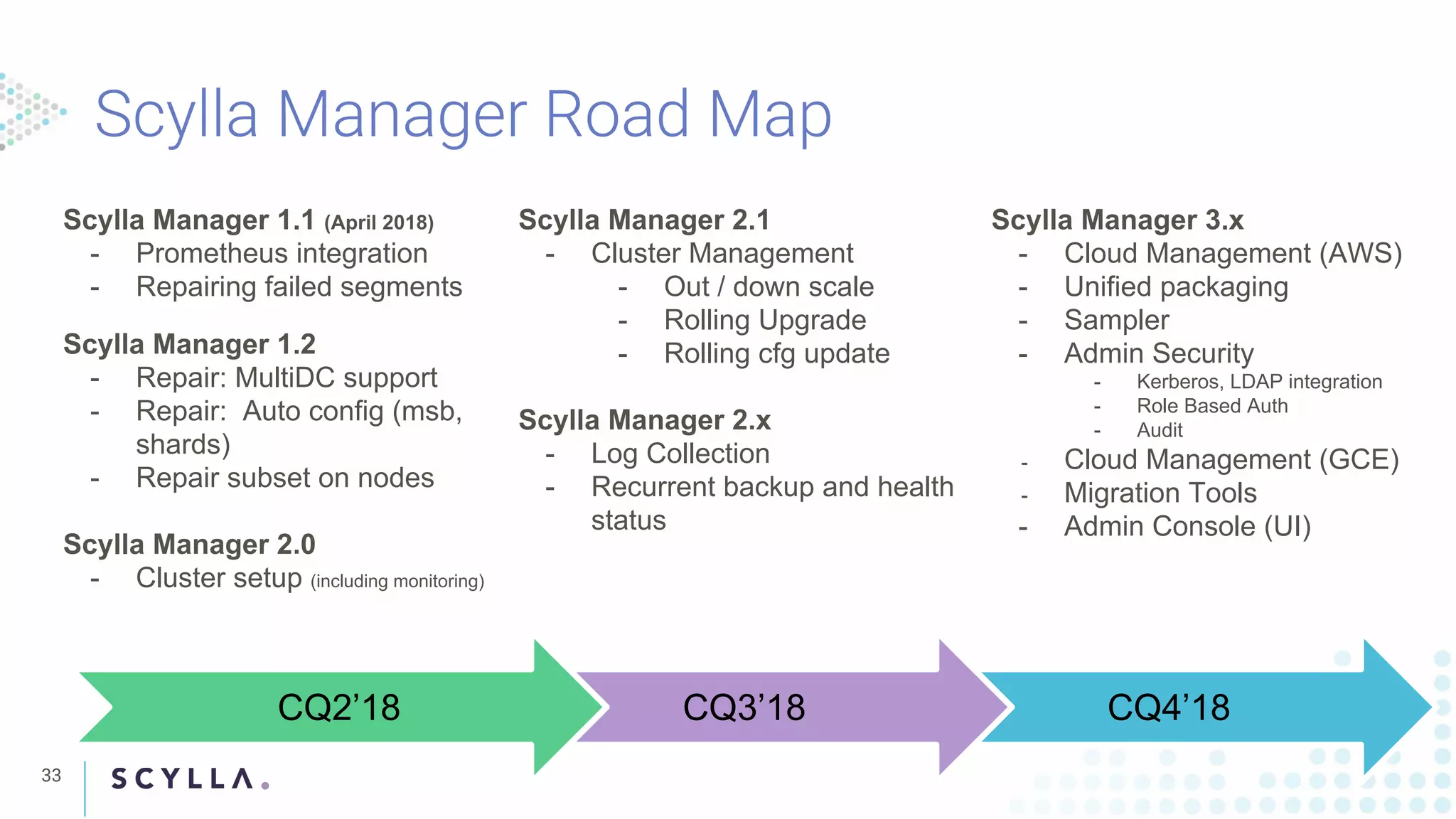
Highlighting Scylla Manager updates, features, and enhancements across versions, including cloud management tools and security integrations.
Concludes the presentation with contact details for ScyllaDB, including website and social media channels.























































































