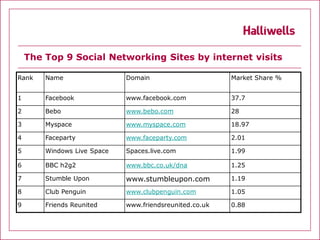
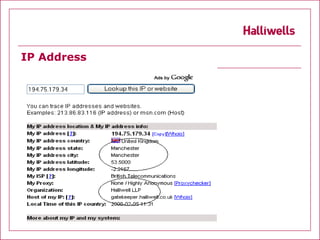
The document discusses various aspects of internet intelligence such as open source searching, deep web searching, social networking sites, investigator footprints, and tracing emails and IP addresses. It provides details on how search engines work and highlights that less than half of the searchable web is fully searchable on any single search engine. The document aims to educate on techniques for online research and investigation.






































![[Workshop] Best-Practice Tech Sourcing, Susanna Frazier - Recruiters’ Hub New...](https://cdn.slidesharecdn.com/ss_thumbnails/rhubnzworkshop-best-practicetechtalentsourcingsusannafrazier-191128135613-thumbnail.jpg?width=640&height=640&fit=bounds)




































