Download to read offline






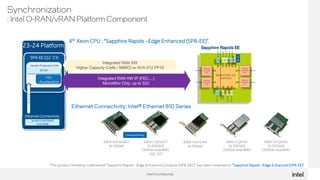
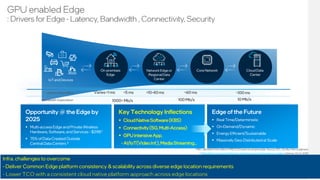
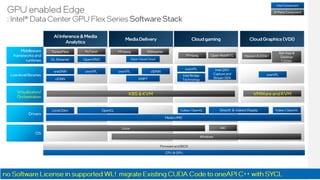




This document discusses network timing synchronization solutions and the Intel Ethernet 810 network interface card. It compares GPS, SyncE, and PTP timing synchronization methods. It then describes the Intel Ethernet 810 NIC's hardware and software features for high accuracy timing, including an OCXO oscillator and GNSS support. Product codes and specifications are provided for the 810 series cards. The document also outlines the Intel edge computing strategy and software stack for edge applications.



![[Cloud OnAir] Google Cloud でセキュアにアプリケーションを開発しよう 2019年3月7日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/0307-190307093545-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[Cloud OnAir] GCP で誰でも始められる HPC 2019年5月9日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/0509-190509090637-thumbnail.jpg?width=640&height=640&fit=bounds)