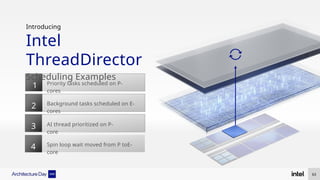
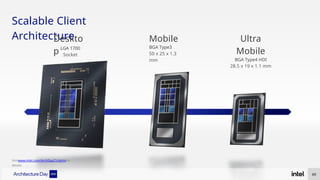
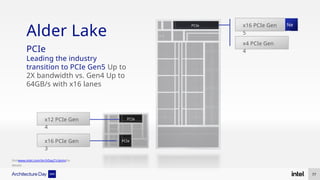
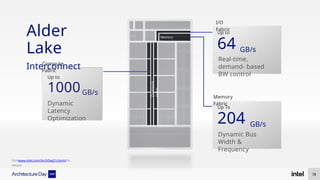
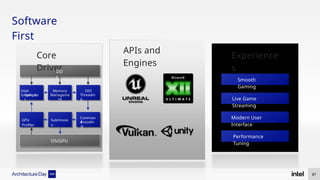
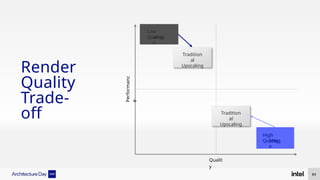
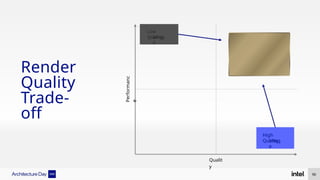
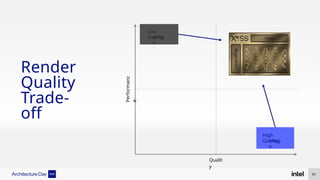
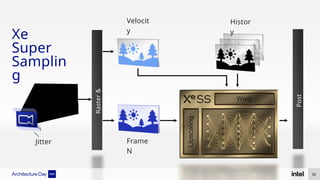
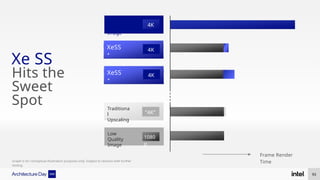
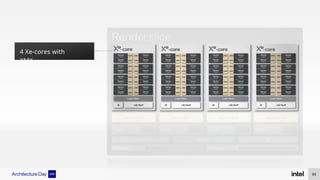
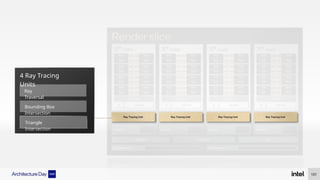
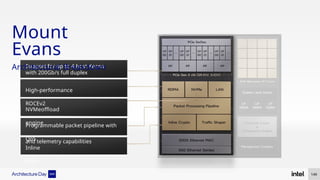
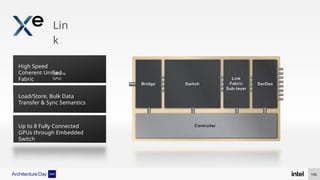
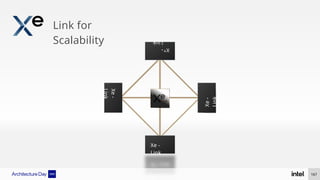
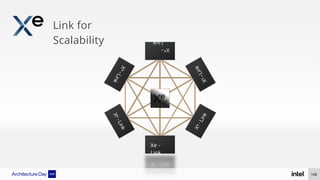
The document discusses Intel's advancements in CPU architecture, focusing on performance and efficiency improvements, particularly in AI and hybrid computing technologies. Key features include new instruction sets, dynamic power management, and enhanced connectivity options like DDR5 and PCIe 5.0. It highlights Intel's innovative designs aimed at optimizing throughput performance and supporting modern workloads across various platforms.













![Inte
l
Coprocessor
2
TMUL Engine
Coprocessor 1
Tmm0 += Tmm1 *
Tmm2
Coheren
t
Memory
Interface
Architectur
eHos
t
TILES and
coprocesso
r
command
s
tmm[n-
1]
TILECONFIG
tmm0 tmm1
Intel® Advanced Matrix Extensions (Intel®
AMX)
Architecture
49](https://image.slidesharecdn.com/77777777777-241207093554-95e5fee2/85/intel-business-presentation-77777777777-pptx-16-320.jpg)










































































![[IGC2018] AMD Don Woligroski - WHY Ryzen](https://cdn.slidesharecdn.com/ss_thumbnails/igc2018amddonwoligroski-whyryzen-181023014303-thumbnail.jpg?width=640&height=640&fit=bounds)




























































