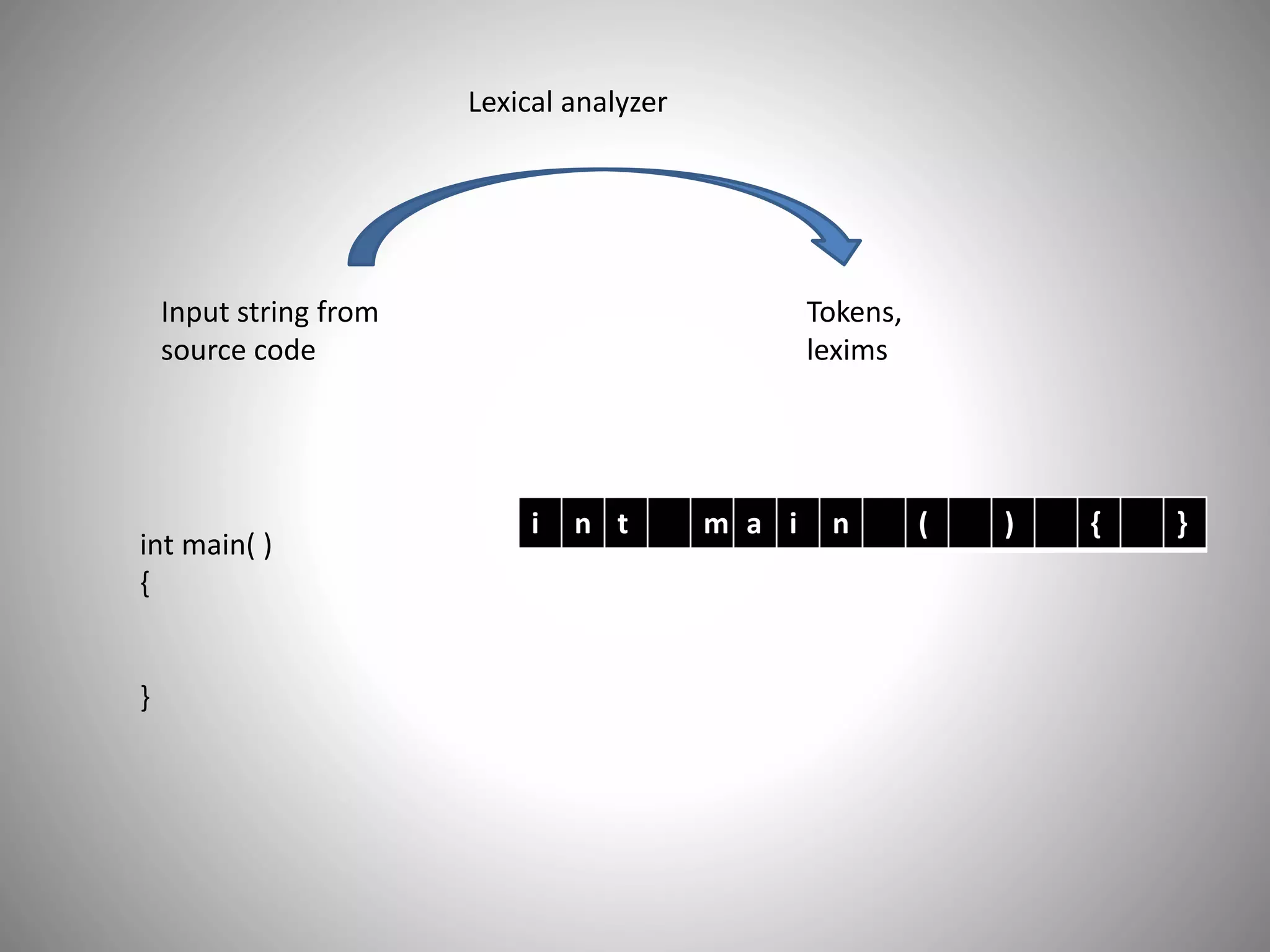
The document discusses the process of lexical analysis in compiler design. It explains that a lexical analyzer takes source code as input and outputs tokens. It uses two pointers - a begin pointer that points to the start of each token, and a forward pointer that moves through the input string character by character. The document then describes two approaches for buffering input - a single buffer scheme that has issues if a token spans the buffer, and a two buffer scheme that avoids this issue by using two buffers and switching between them.
i n tm a i n ( ) { }
• Lexim begin pointer
• points to the beginning of every token
• Forward pointer
• Points every next character in the input string
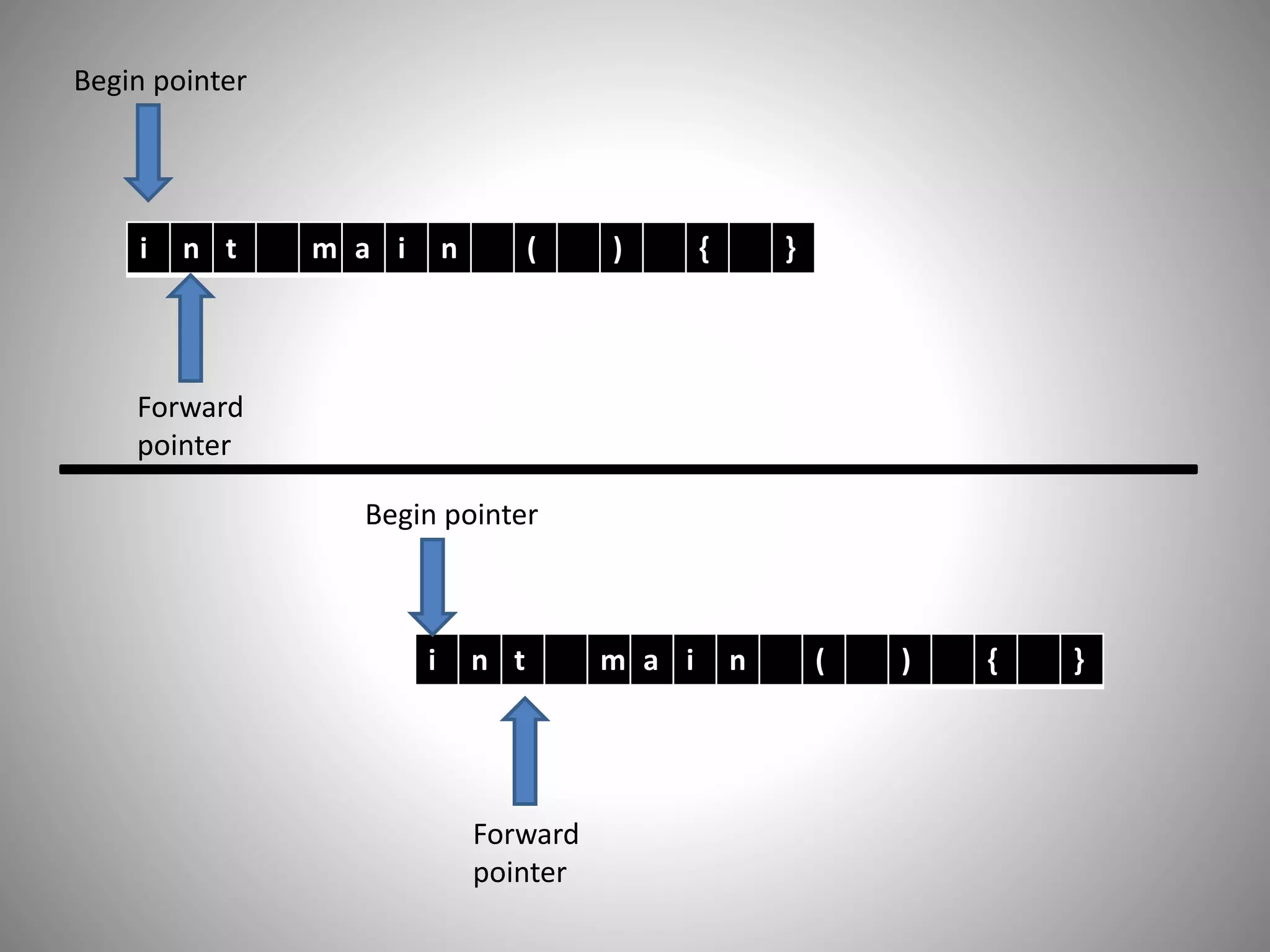
Begin pointer
Forward
pointer
intially
4.
i n tm a i n ( ) { }
Begin pointer
Forward
pointer
i n t m a i n ( ) { }
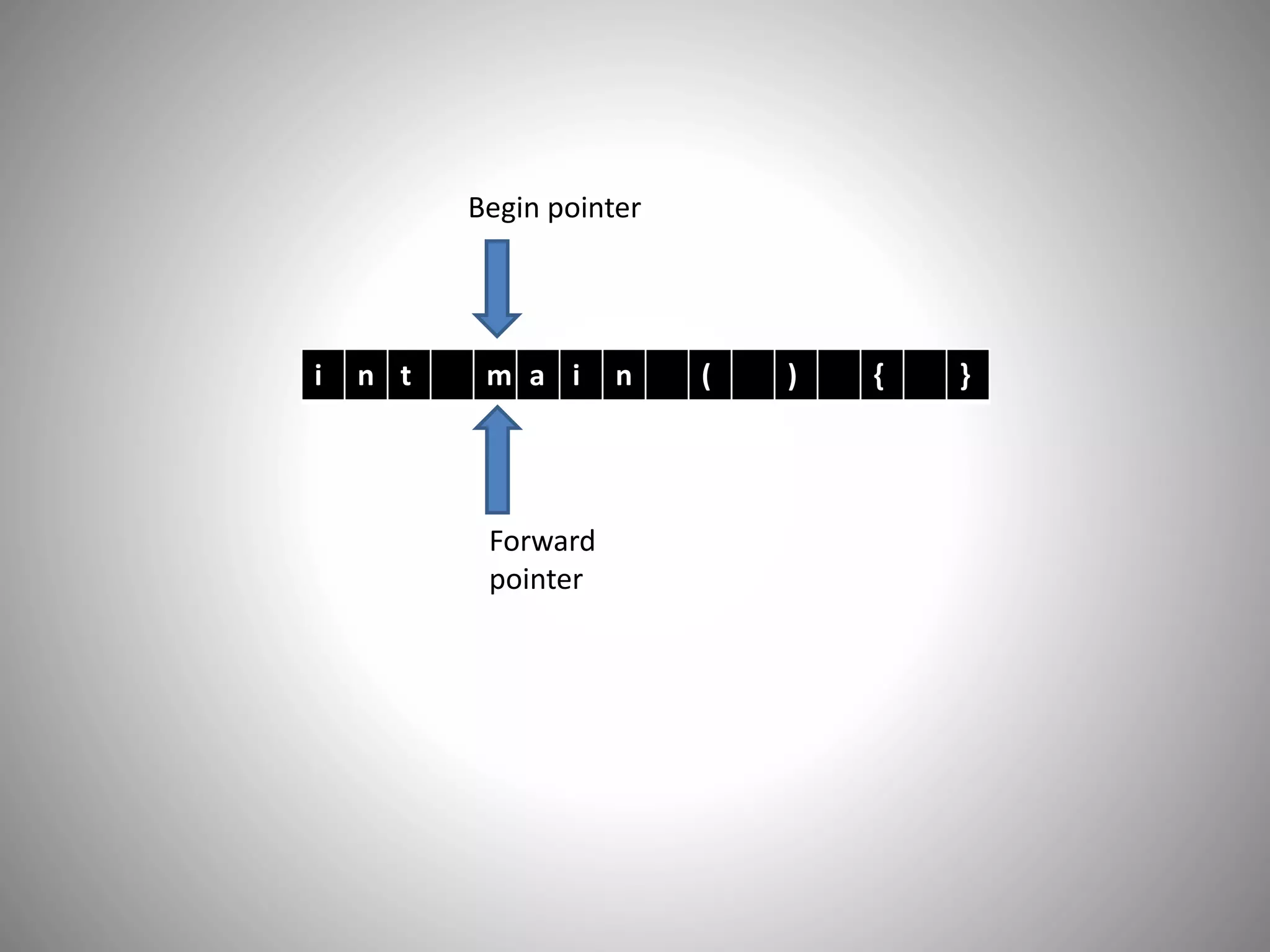
Begin pointer
Forward
pointer
5.
i n tm a i n ( ) { }
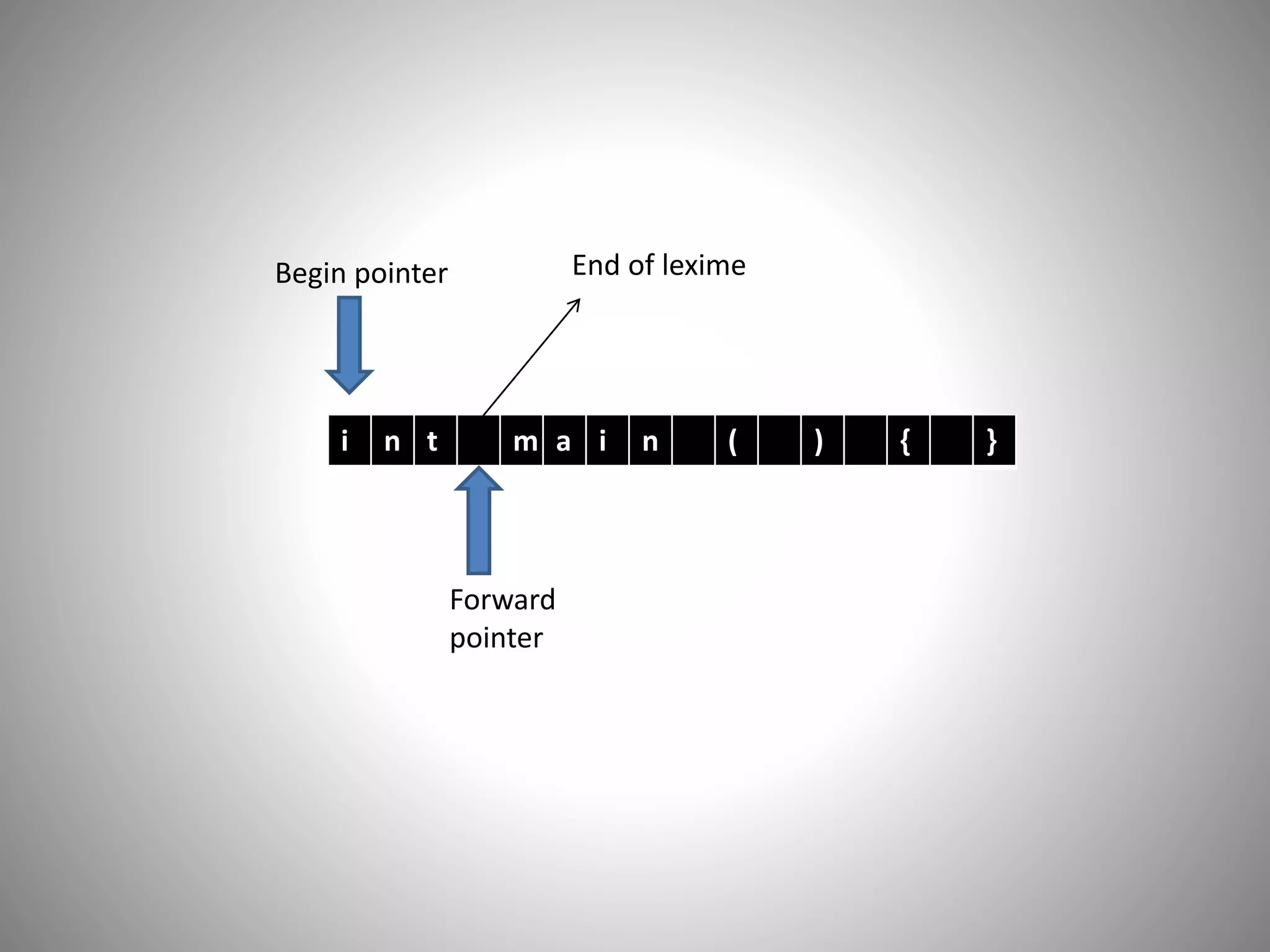
Begin pointer
Forward
pointer
End of lexime
6.
i n tm a i n ( ) { }
Begin pointer
Forward
pointer
7.
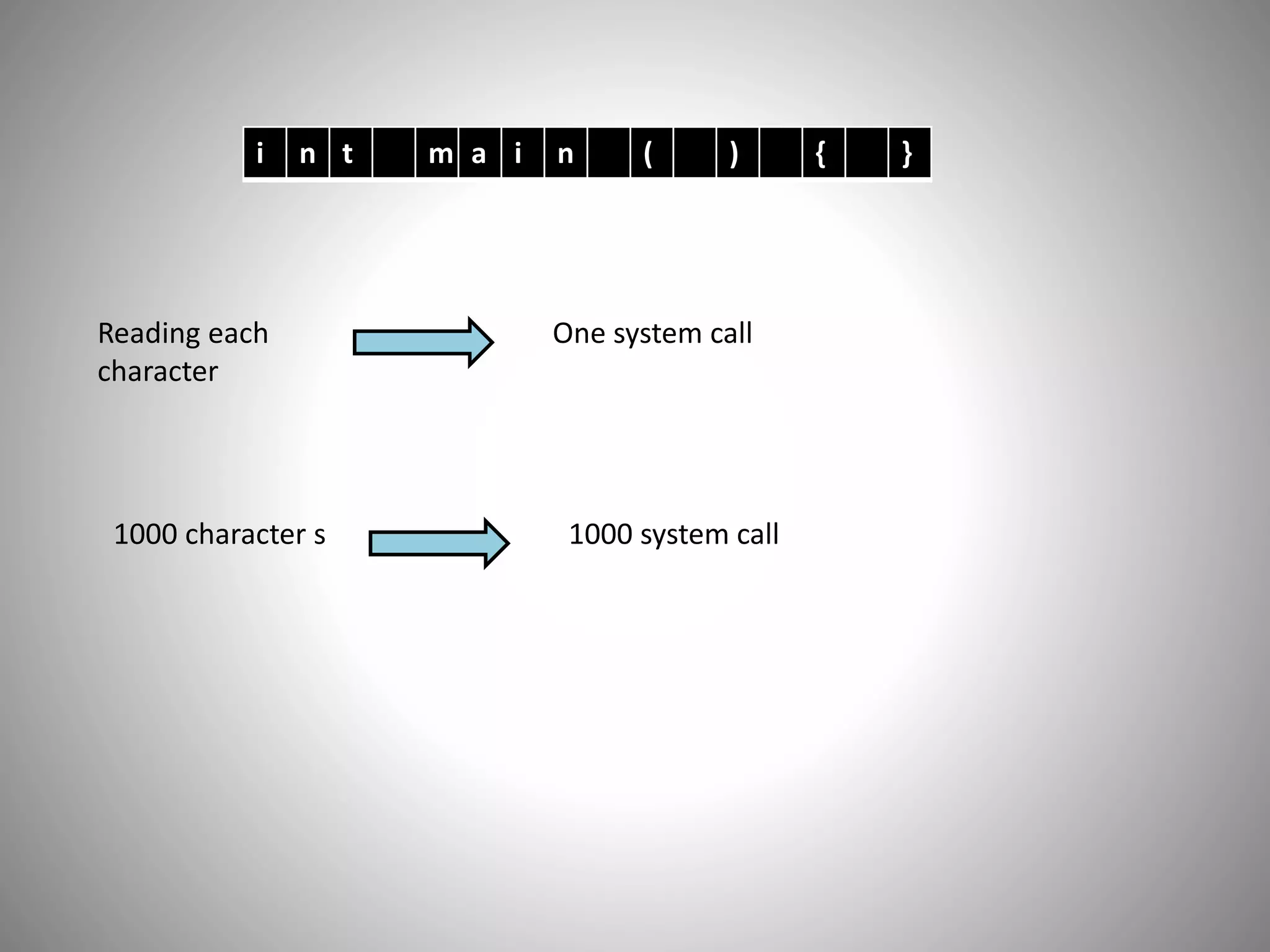
i n tm a i n ( ) { }
Reading each
character
One system call
1000 character s 1000 system call
8.
Buffering
• One BufferScheme
int i,j ;
A block of data is first read into a buffer, and then
second by lexical analyzer.
i n t i , j ;
In this scheme, only one buffer is used to store the input
string but the problem with this scheme is that if lexeme is
very long then it crosses the buffer boundary, to scan rest of
the lexeme the buffer has to be refilled, that makes
overwriting the first of lexeme.
9.
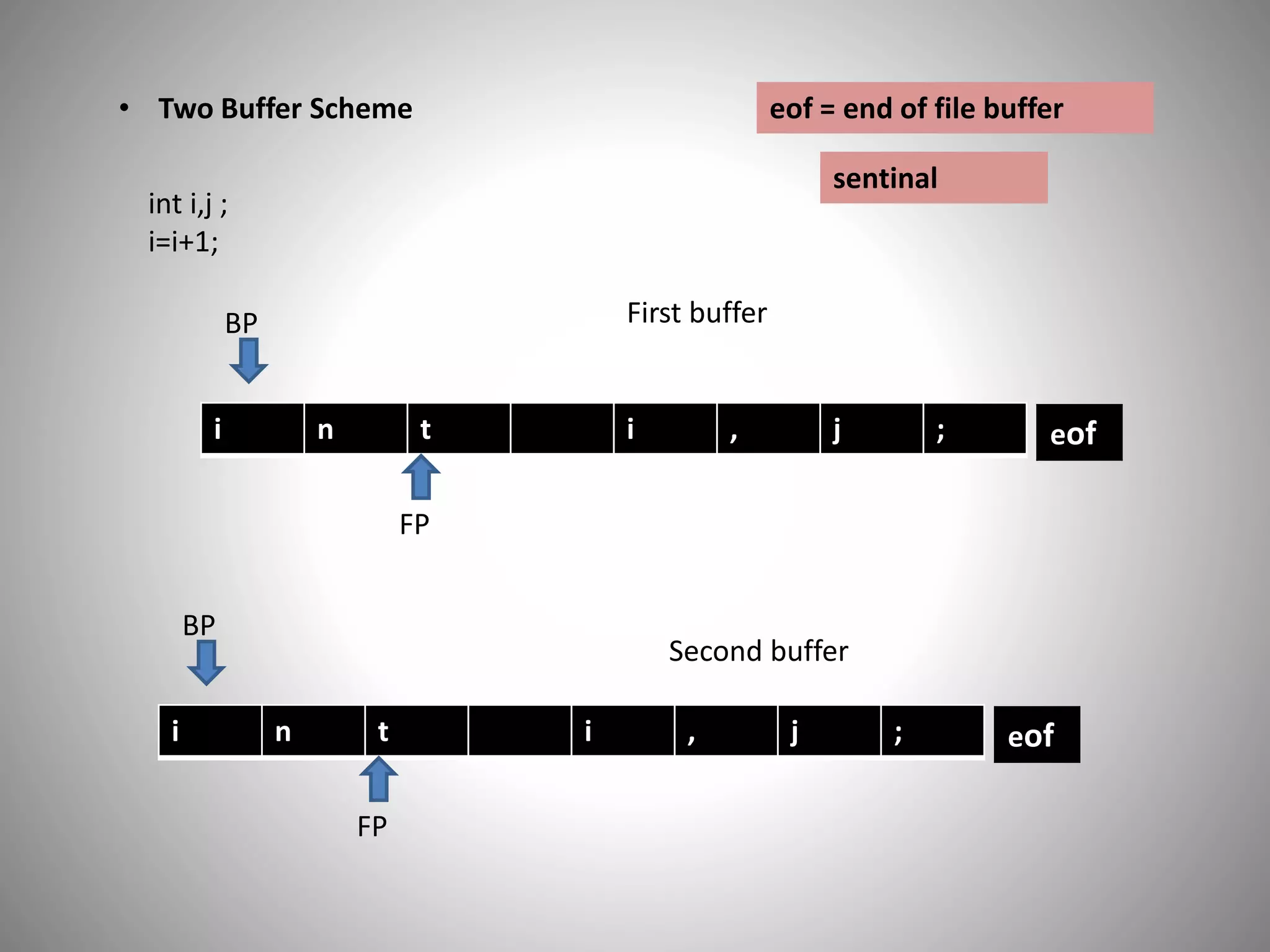
• Two BufferScheme
int i,j ;
i=i+1;
i n t i , j ;
BP
FP
eof
Second buffer
i n t i , j ;
BP
FP
eof
First buffer
eof = end of file buffer
sentinal
10.
• Algorithm
switch(*forward++)
{
}
case ‘eof’:
if (forward is at the end of 1st buffer)
{
forward= beginning of 2nd buffer;
refill 2nd buffer;
}
else if (forward is at the end of 2nd buffer)
{
forward= beginning of 1st buffer;
refill 1st buffer;
}
else break;
case for other charcters :





















































![[DSC Europe 25] Jim Sterne - Adopting Generative AI Capabilities Into the Ent...](https://cdn.slidesharecdn.com/ss_thumbnails/sxhpofuorcagxsaulkmt-3-251204082258-7e66bc48-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Vid Stimac - Policy Parsimony: Between Oversimplifying and Ov...](https://cdn.slidesharecdn.com/ss_thumbnails/eqlepagzqp2rhg3gbluh-dsc-stimac-251120-251205090438-059e7f54-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)





