Download as PDF, PPTX



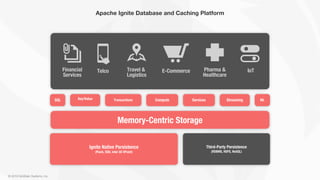


![© 2018 GridGain Systems, Inc.
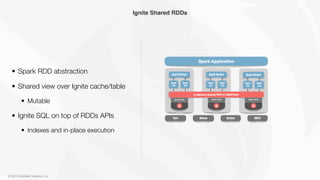
• Standard RDD APIs + Ignite SQL
• No rip-and-replace
• Switch to Ignite as a storage
Write to and Read from Ignite
val sharedRDD: IgniteRDD[int, int] = ic.fromCache(”sharedRDD")
val greaterThanFiftyThousand = sharedRDD.filter(_._2 > 50000)
val df = sharedRDD.sql(”select _val from Integer where _key > 50000”)
val sharedRDD: IgniteRDD[int, int] = ic.fromCache(”sharedRDD")
sharedRDD.savePairs(sc.parallelize(1 to 100000, 10).map(i => (i, i)))](https://image.slidesharecdn.com/improvingapachesparkin-memorycomputingwithapacheignite-180518050513/85/Improving-Apache-Spark-In-Memory-Computing-with-Apache-Ignite-8-320.jpg)
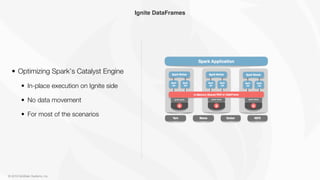
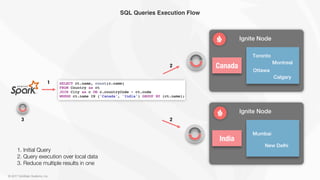




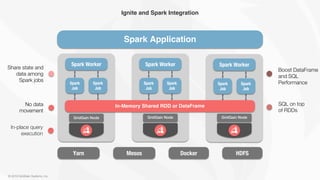
The document outlines the integration of Apache Ignite with Apache Spark to enhance in-memory computing capabilities. It describes Ignite as a memory-centric data storage and processing platform that allows for efficient data ingestion, processing, and analytics without data movement between Ignite and Spark. Key features include in-place query execution, support for various workloads, and the ability to optimize Spark's performance using Ignite-based dataframes.















































































