Downloaded 32 times
![Session 1783 – Part II Achieving High Availability with WebSphere on z/OS - user experience Presented by Elena Nanos IBM Certified Advanced System Administrator - WebSphere Application Server ND V6.1 IBM Certified Solution Expert - CICS Web Enablement IBM Certified System Specialist - WebSphere MQSeries Email - [email_address] Health Care Service Corporation WebSphere Engineering and Support services Session 1783 – Part II Achieving High Availability with WebSphere on z/OS - user experience 1](https://image.slidesharecdn.com/impact20091783achievingavailabilitywithwasz-userexperience-091122200250-phpapp02/75/Impact-2009-1783-Achieving-Availability-With-W-A-Sz-User-Experience-1-2048.jpg)





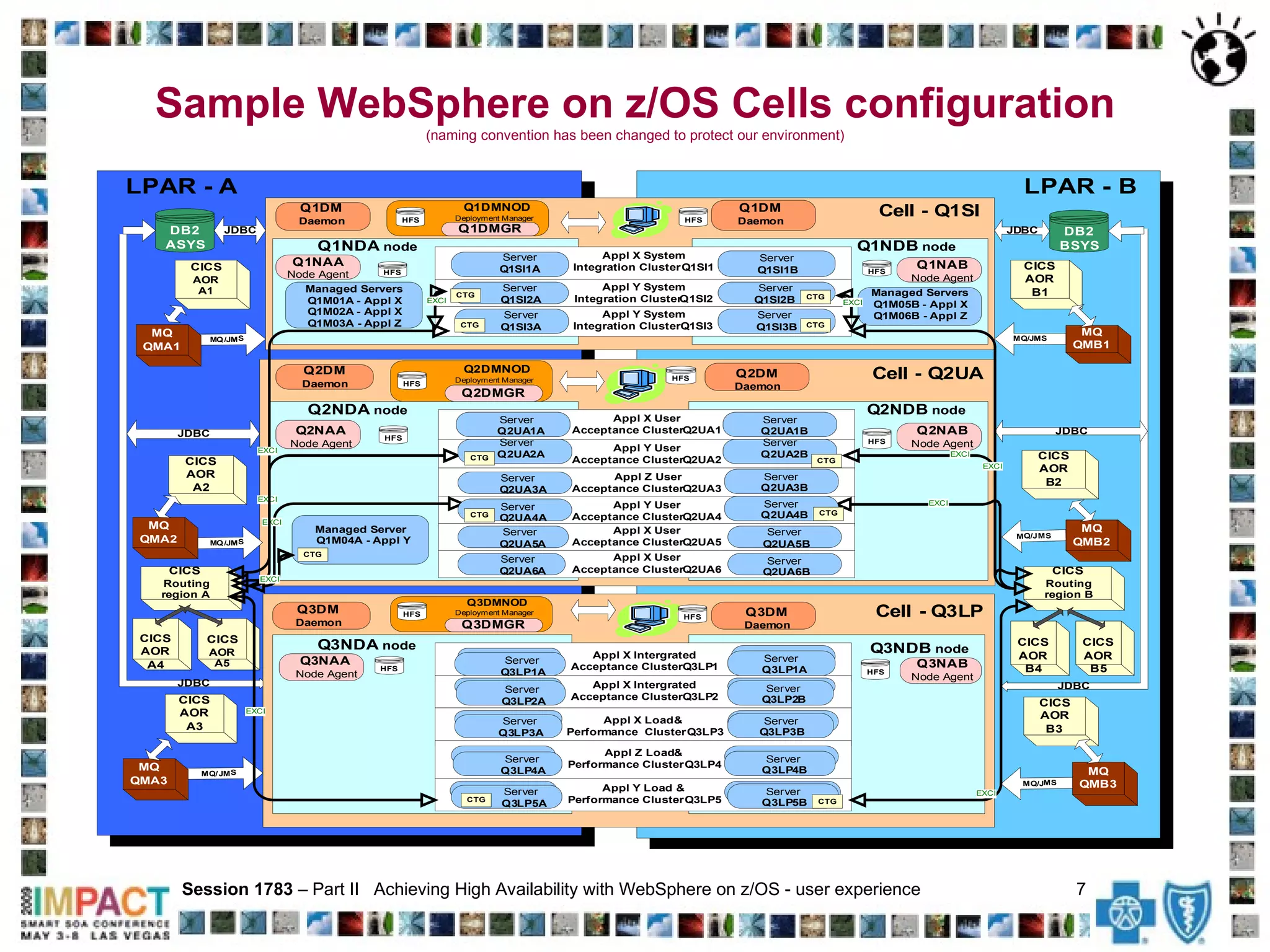
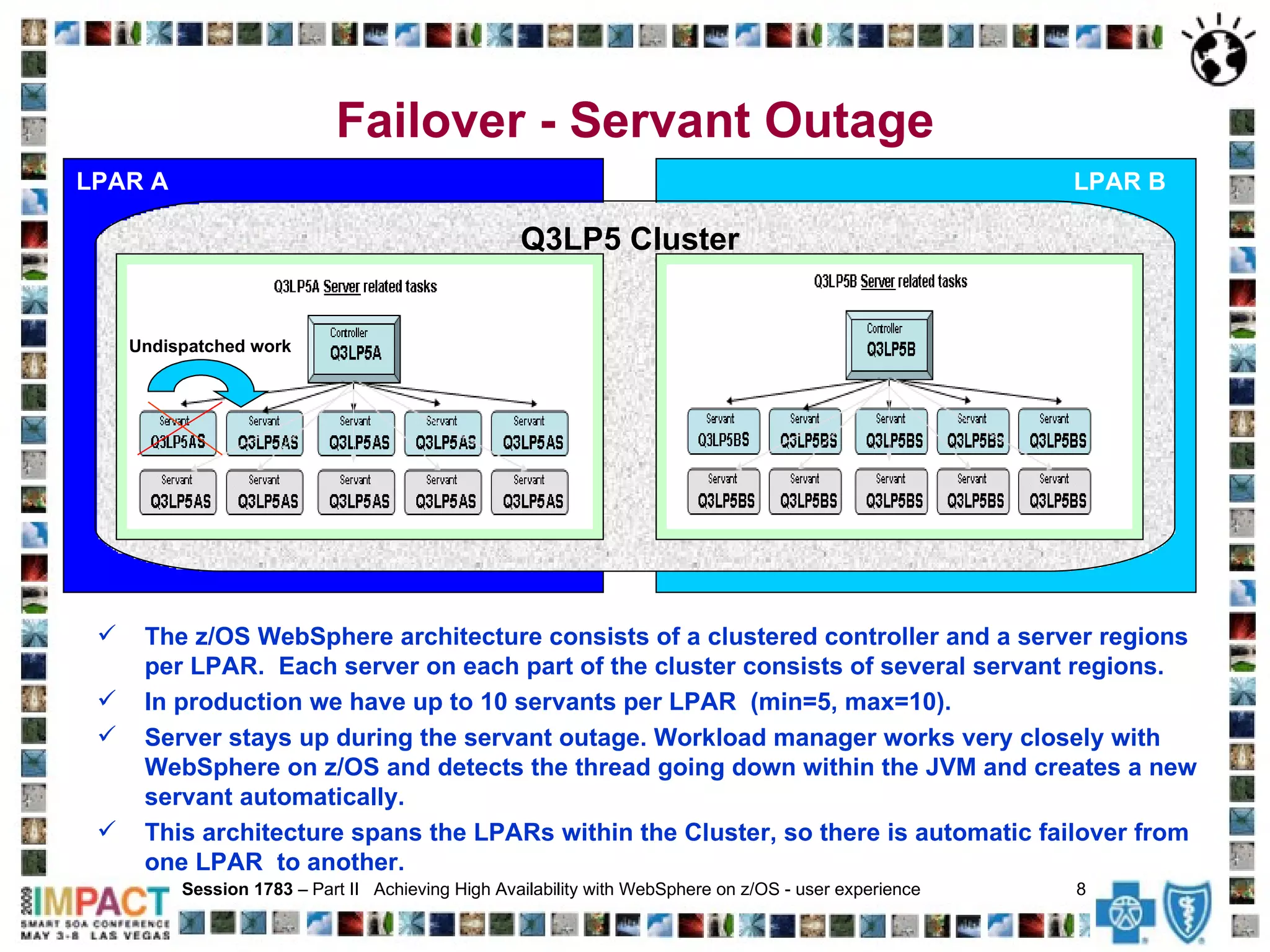







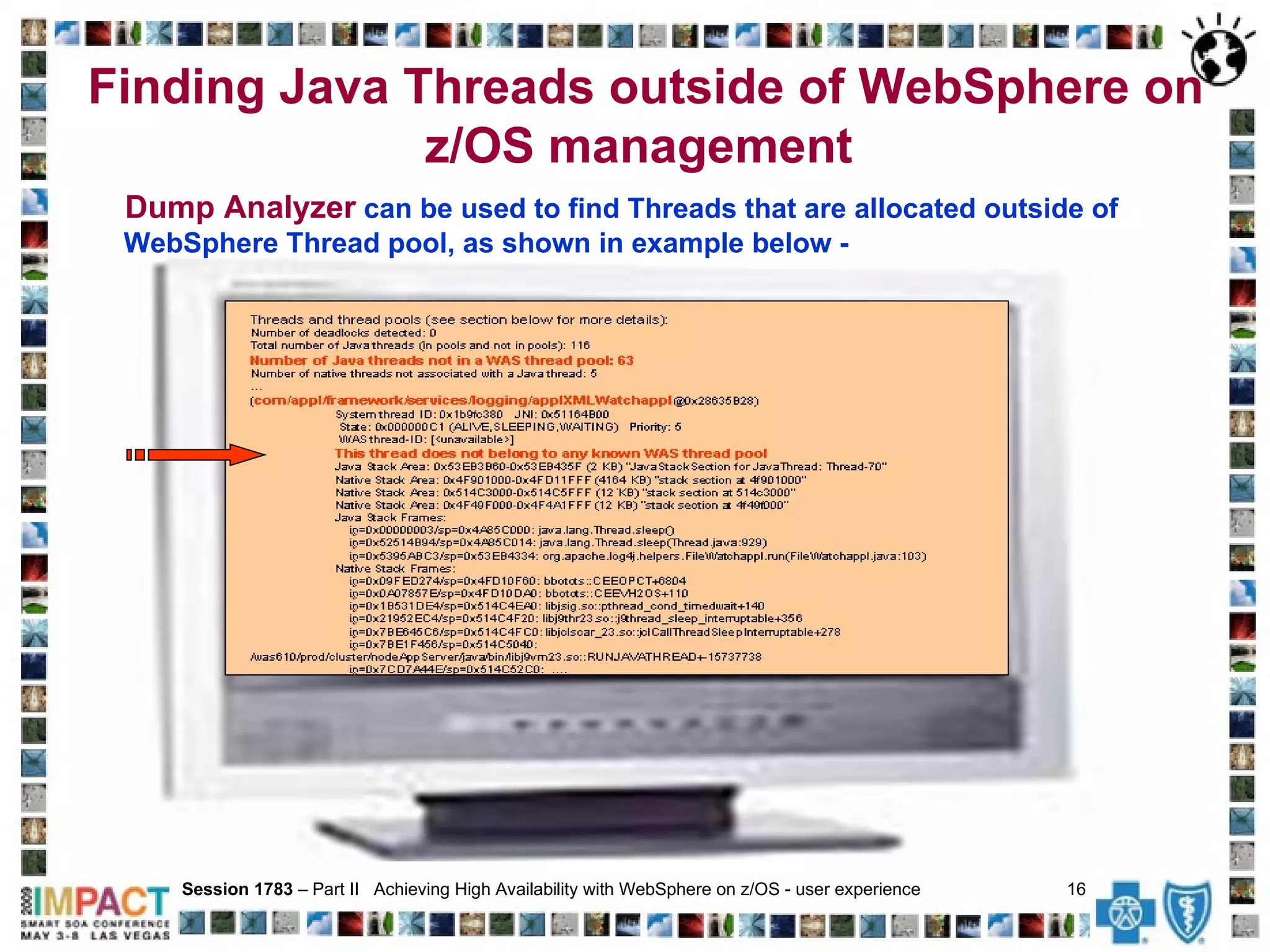


The document discusses achieving high availability for WebSphere Application Server on z/OS. It describes the clustered architecture with control/servant regions that allows for automatic failover. It provides recommendations for minimizing the effects of timeouts, including setting timeout values and delaying servant termination. It also discusses health check procedures, alerts, avoiding memory leaks with ThreadLocals, and tools for monitoring and debugging the environment.














































































