Downloaded 65 times








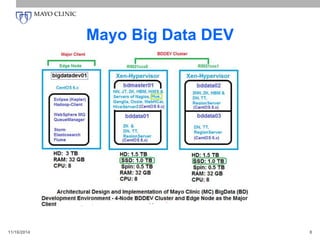




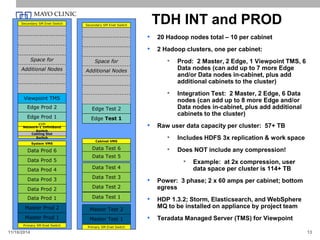









The document discusses the Mayo Clinic's initiatives and experiences in leveraging big data technologies, particularly focusing on Hadoop and its ecosystem, to enhance patient care and operational efficiency. It outlines the components and setup of their big data environment, including the use of various tools and methodologies like agile development, and highlights the importance of big data in making informed decisions based on comprehensive patient information. The conclusion emphasizes that big data solutions like Hadoop are valuable in specific problem areas and can significantly aid the healthcare sector.























































































