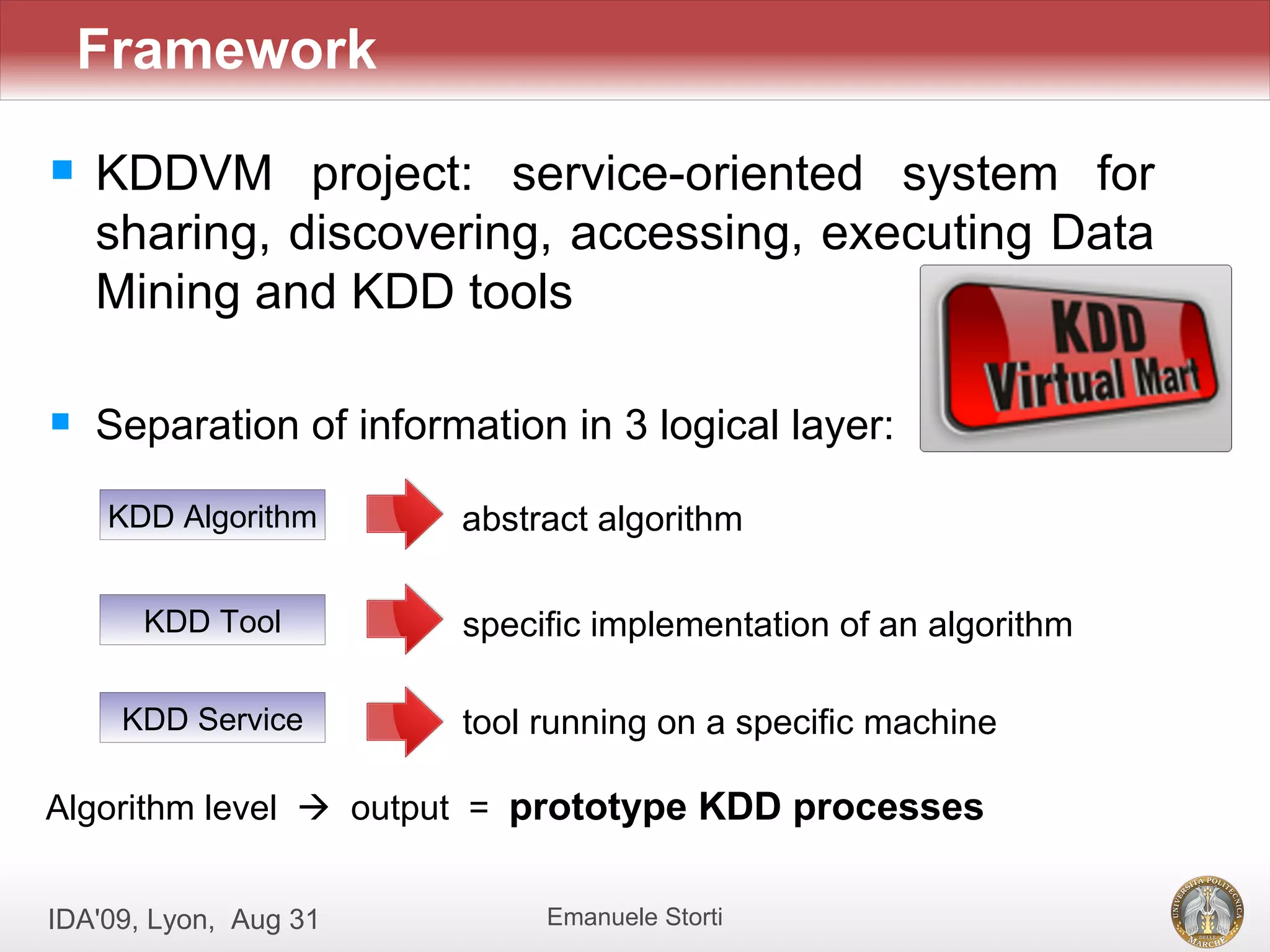
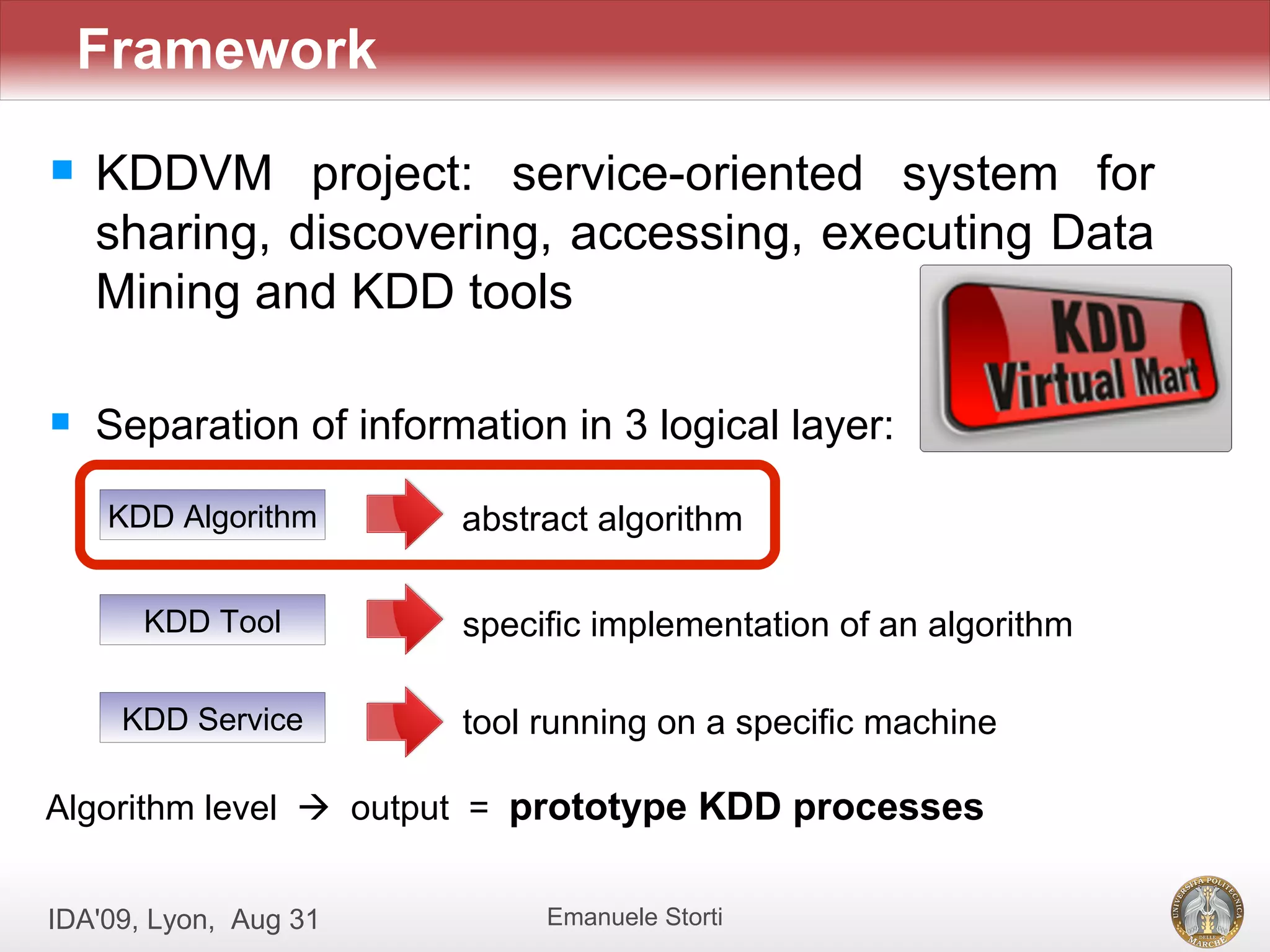
The document discusses the development of an ontology-driven approach to automate the composition of knowledge discovery in databases (KDD) processes. It emphasizes the need for formalizing KDD algorithms into ontologies to facilitate algorithm compatibility and create goal-oriented compositions based on user requests. The proposed framework, KDDVM, aims to enhance the efficiency of generating valid KDD processes through a structured methodology and semantic representation.

![Introduction
Knowledge Discovery in Databases is the non-trivial
process of identifying valid, novel, potentially useful, and
ultimately understandable patterns in data. [Fayyad et al., 1996]
Many sources of complexity:
iterative/interactive process
many tasks and phases
several algorithms available for each
phase, with specific:
characteristics, interfaces
preconditions/postconditions
performances
IDA'09, Lyon, Aug 31 Emanuele Storti](https://image.slidesharecdn.com/ida2009presentation-121007084424-phpapp02/75/Ontology-driven-KDD-Process-Composition-2-2048.jpg)
![Introduction
Knowledge Discovery in Databases is the non-trivial
process of identifying valid, novel, potentially useful, and
ultimately understandable patterns in data. [Fayyad et al., 1996]
Many sources of complexity:
iterative/interactive process
many tasks and phases
several algorithms available for each
phase, with specific:
characteristics, interfaces
preconditions/postconditions
performances
Need of systems for supporting users in composing algorithm for producing valid
and useful KDD processes
IDA'09, Lyon, Aug 31 Emanuele Storti](https://image.slidesharecdn.com/ida2009presentation-121007084424-phpapp02/75/Ontology-driven-KDD-Process-Composition-3-2048.jpg)






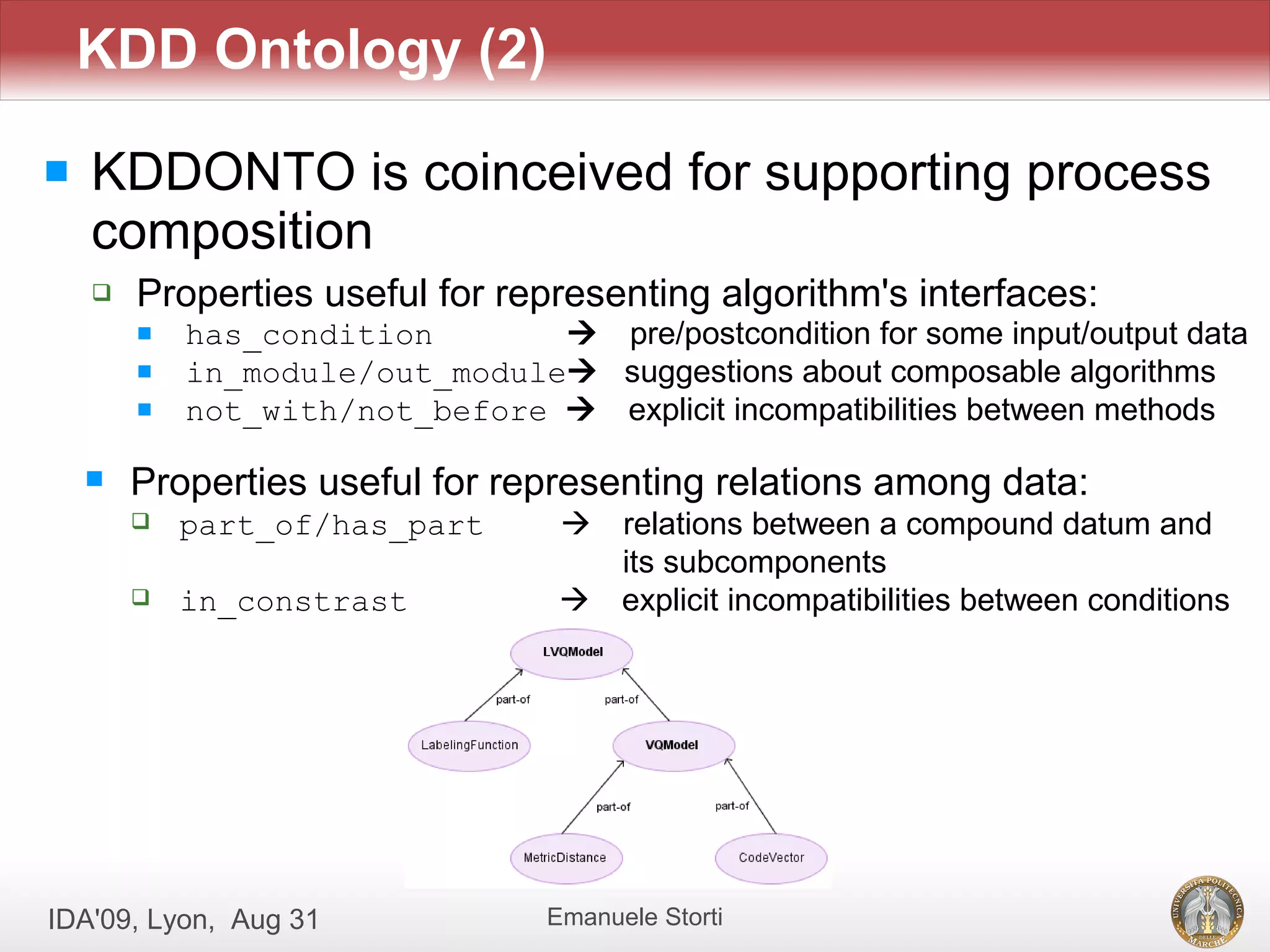
![KDD Ontology (1)
KDDONTO is an ontology formalizing the
domain of KDD algorithms:
developed following a formal methodology [Noy, 2002]
(concept definition logic modeling translation in OWL evaluation)
taking into account quality requirements [Gruber, 1995]
Main classes and relations:
Algorithm, Method
Task, Phase
Data, DataFeature
Performance
has_input/has_output
...
IDA'09, Lyon, Aug 31 Emanuele Storti](https://image.slidesharecdn.com/ida2009presentation-121007084424-phpapp02/75/Ontology-driven-KDD-Process-Composition-12-2048.jpg)
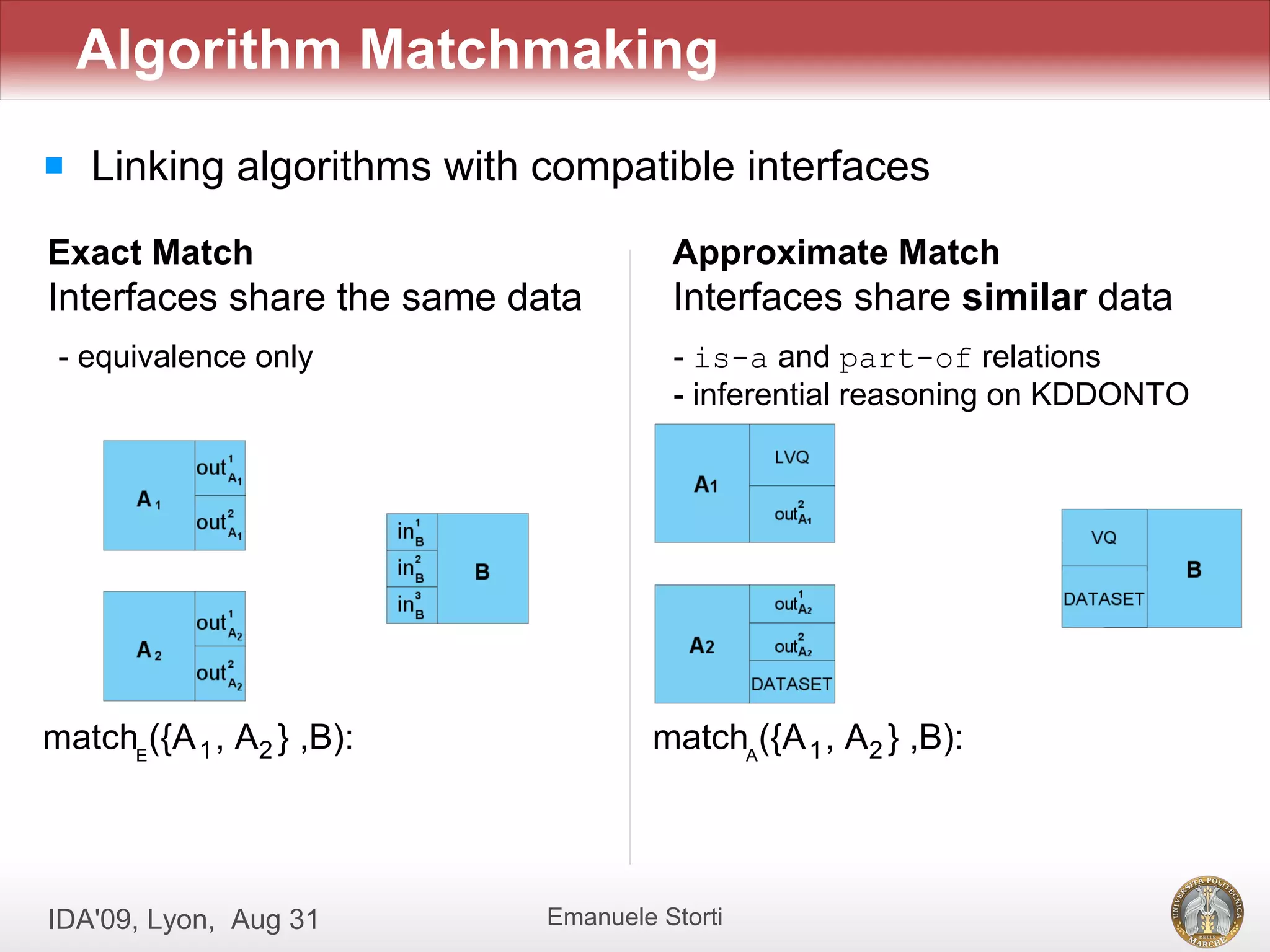
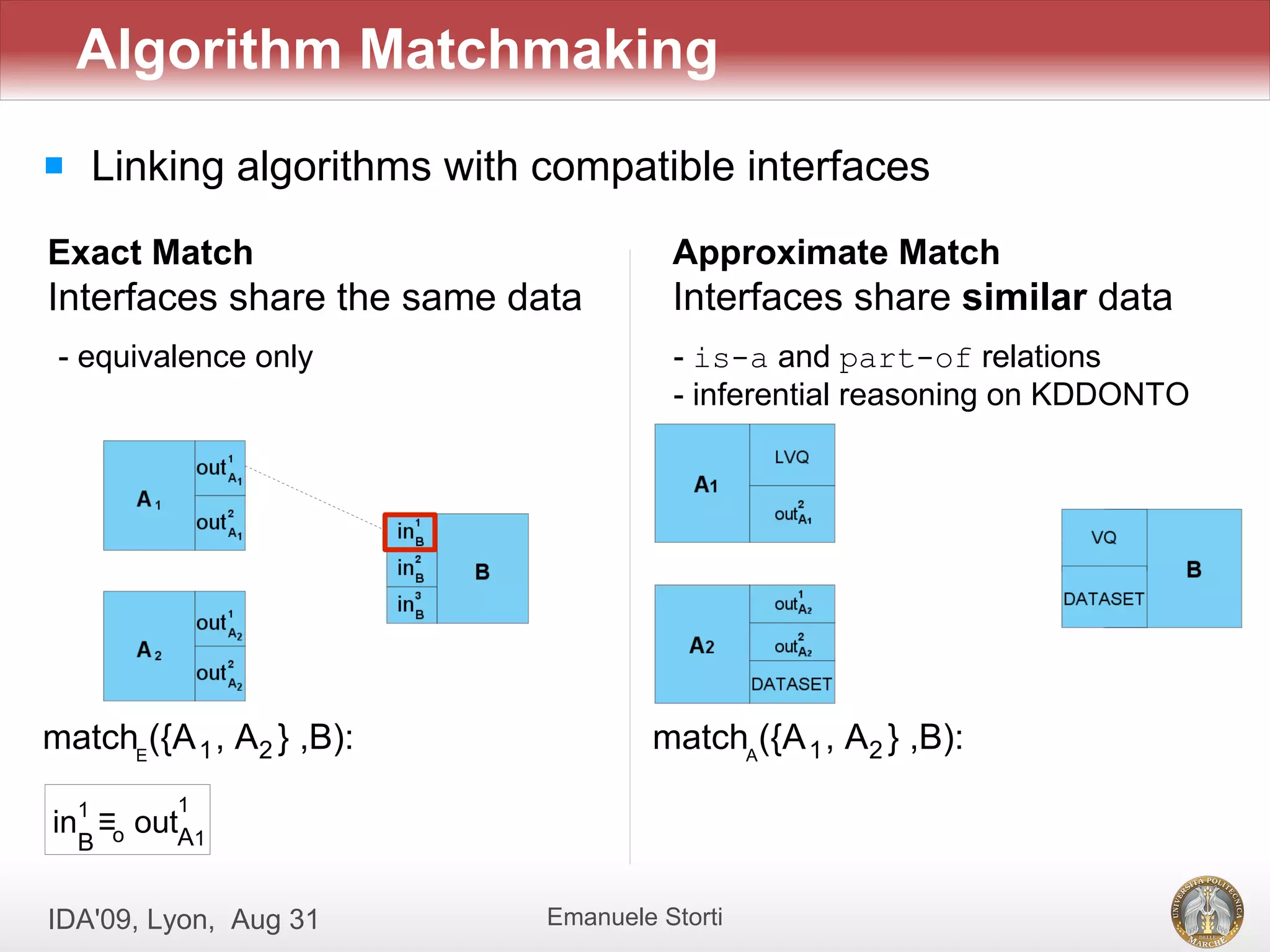
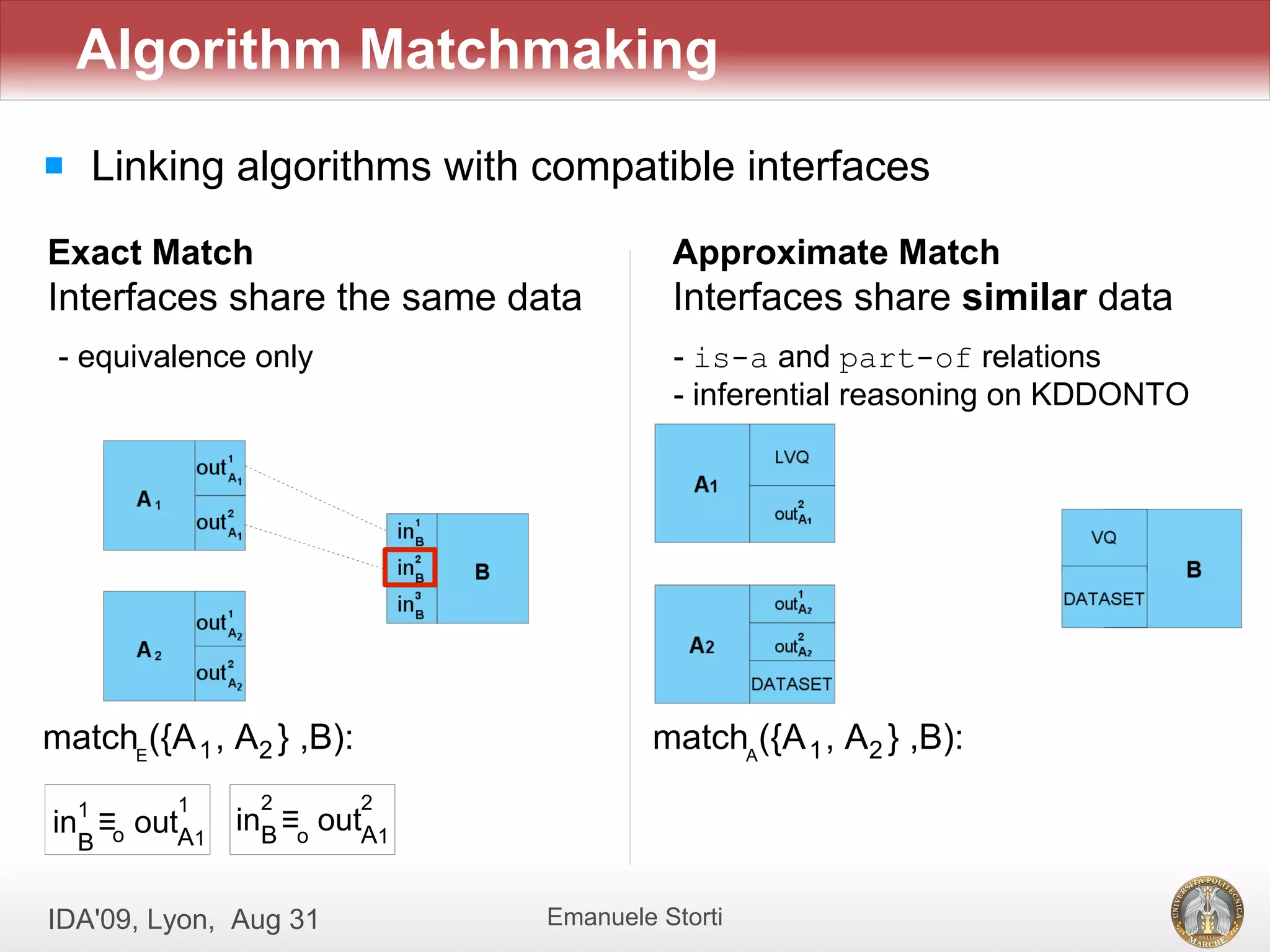
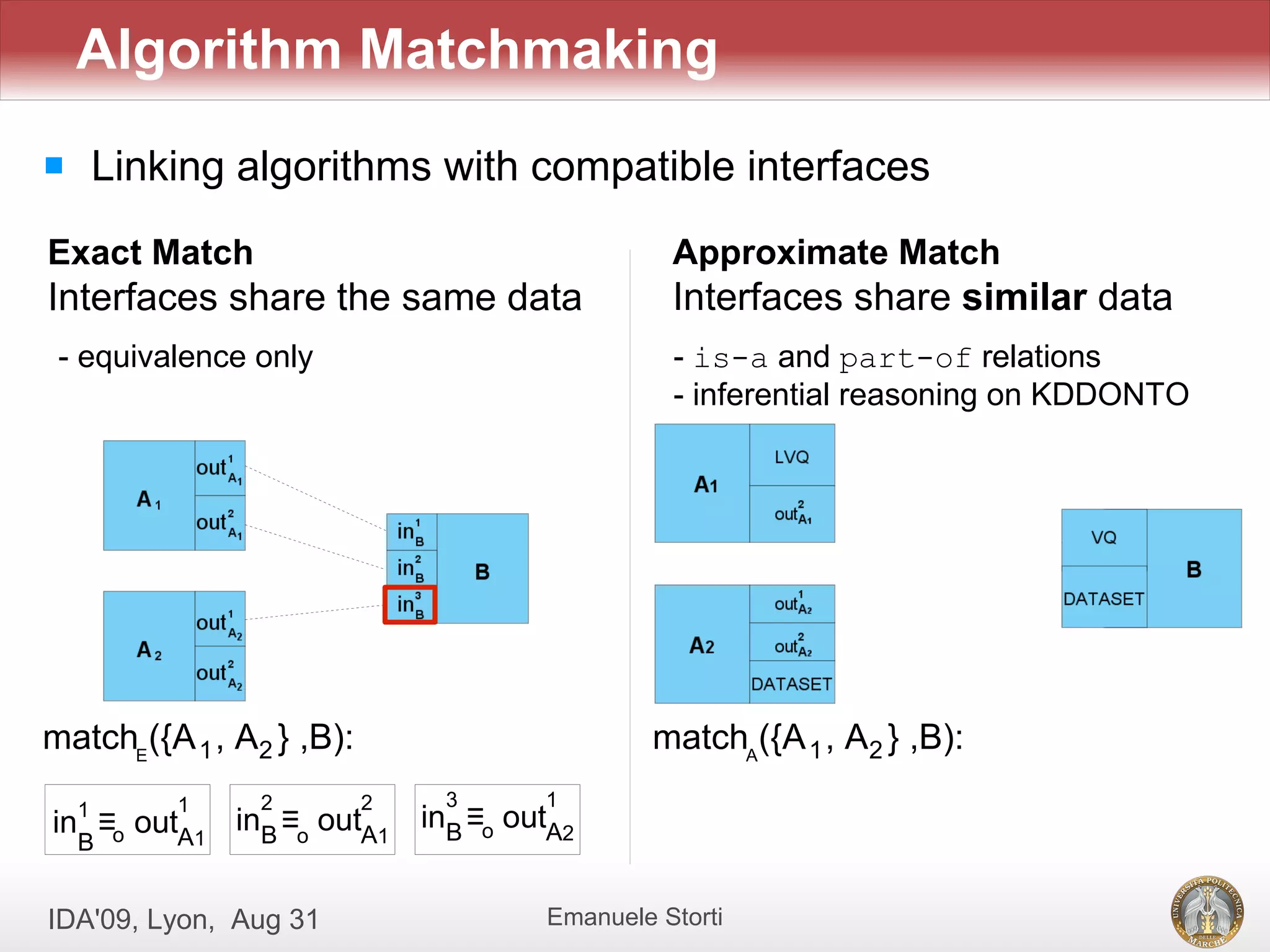
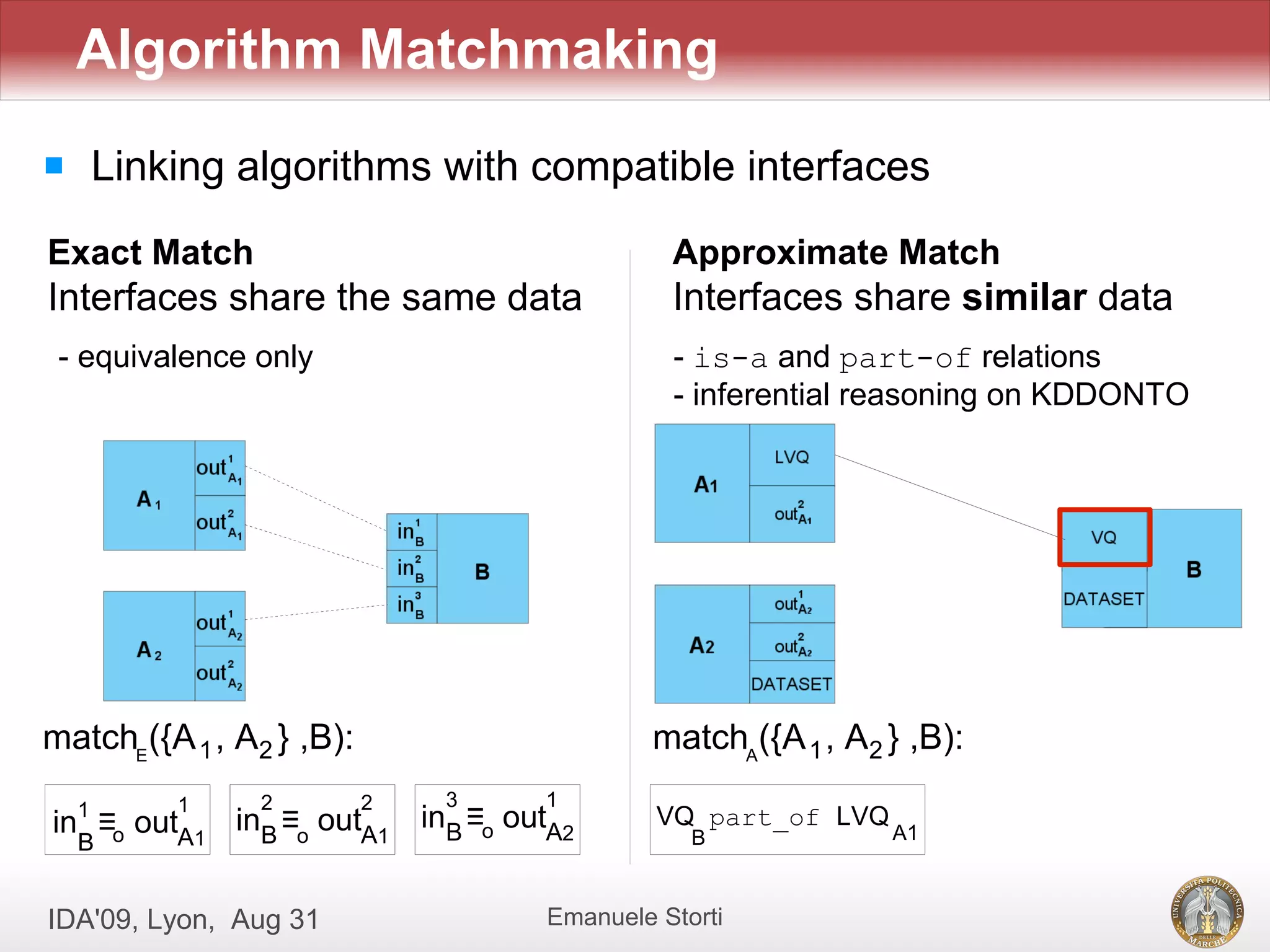










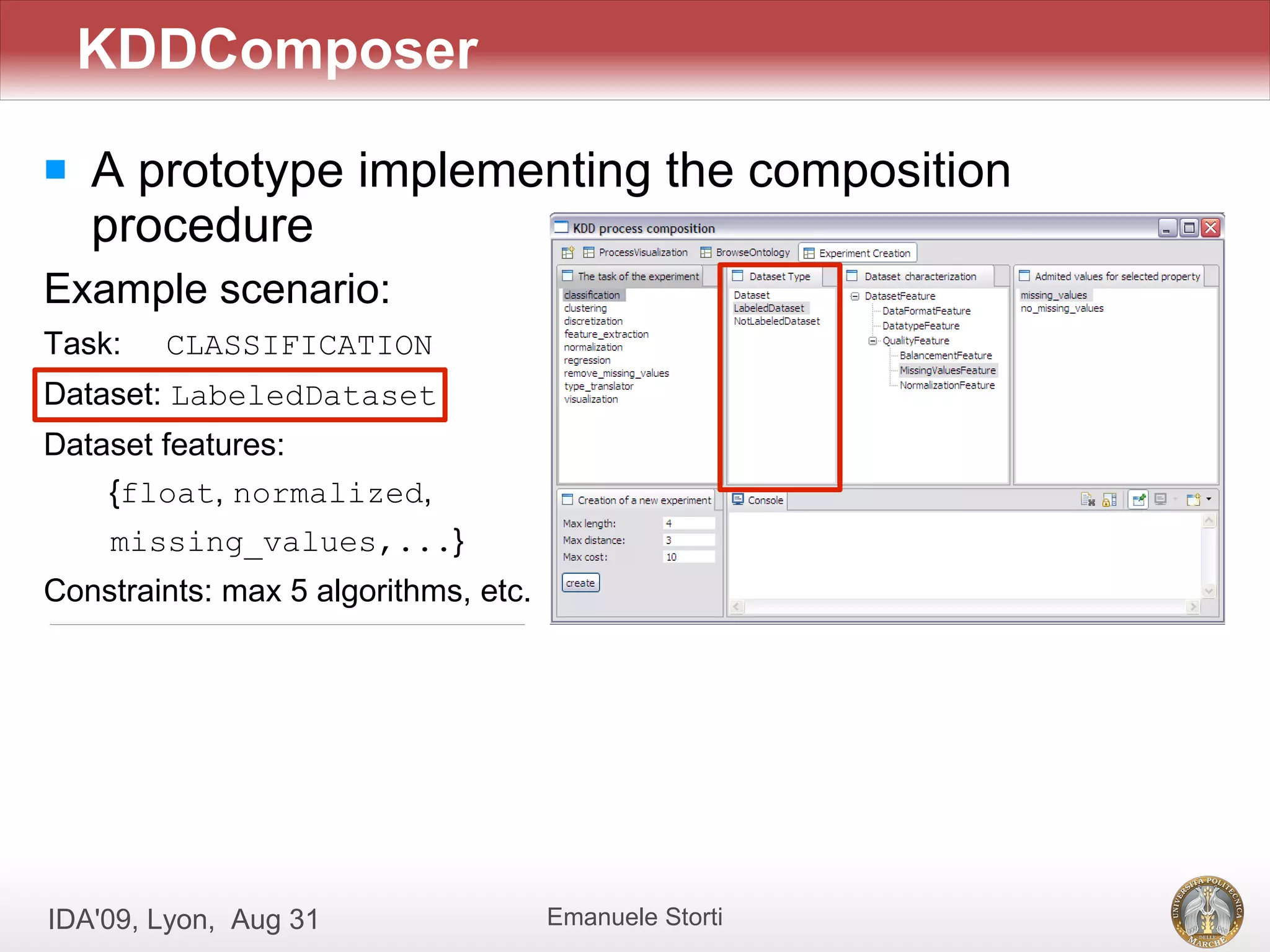
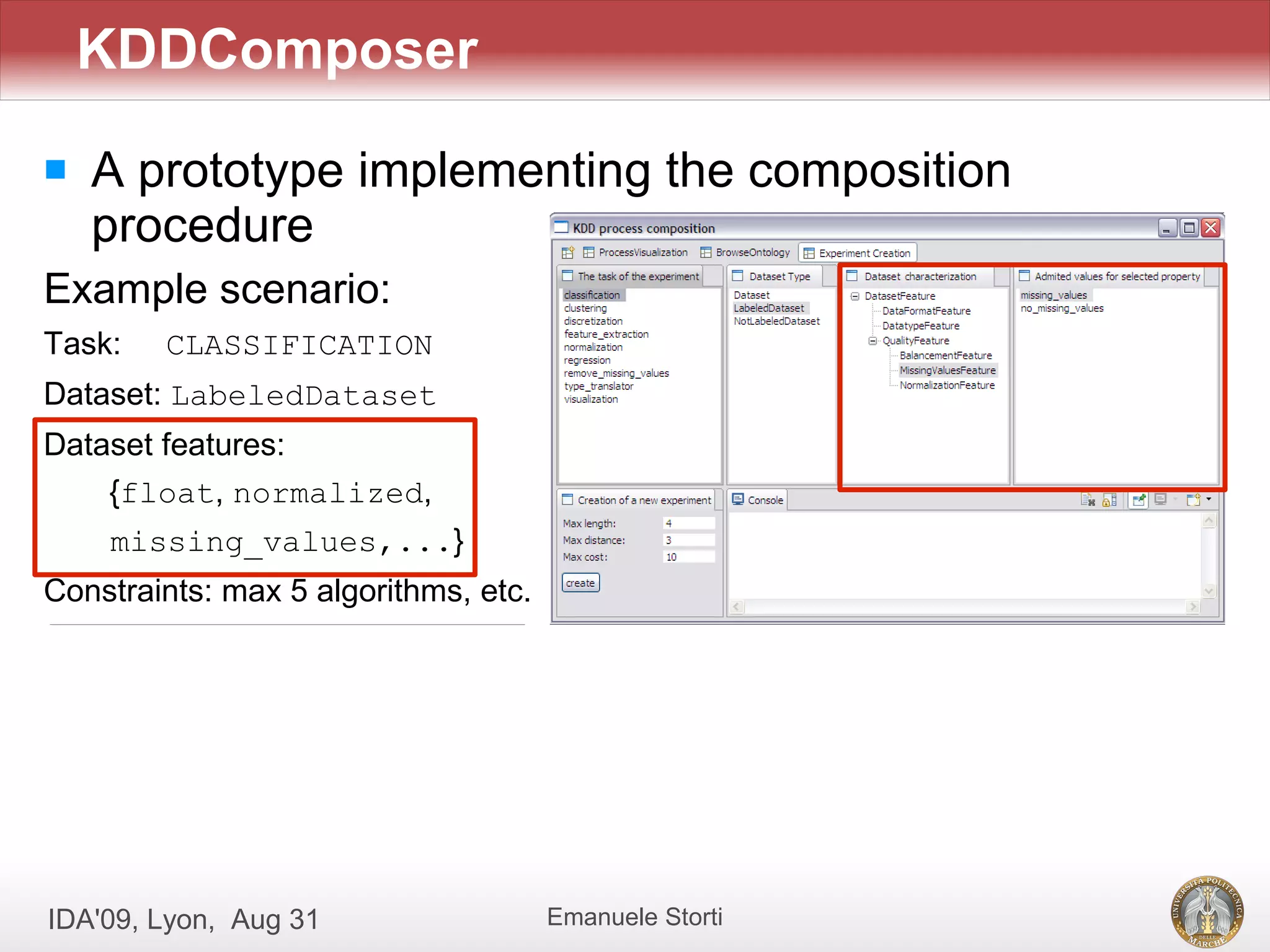
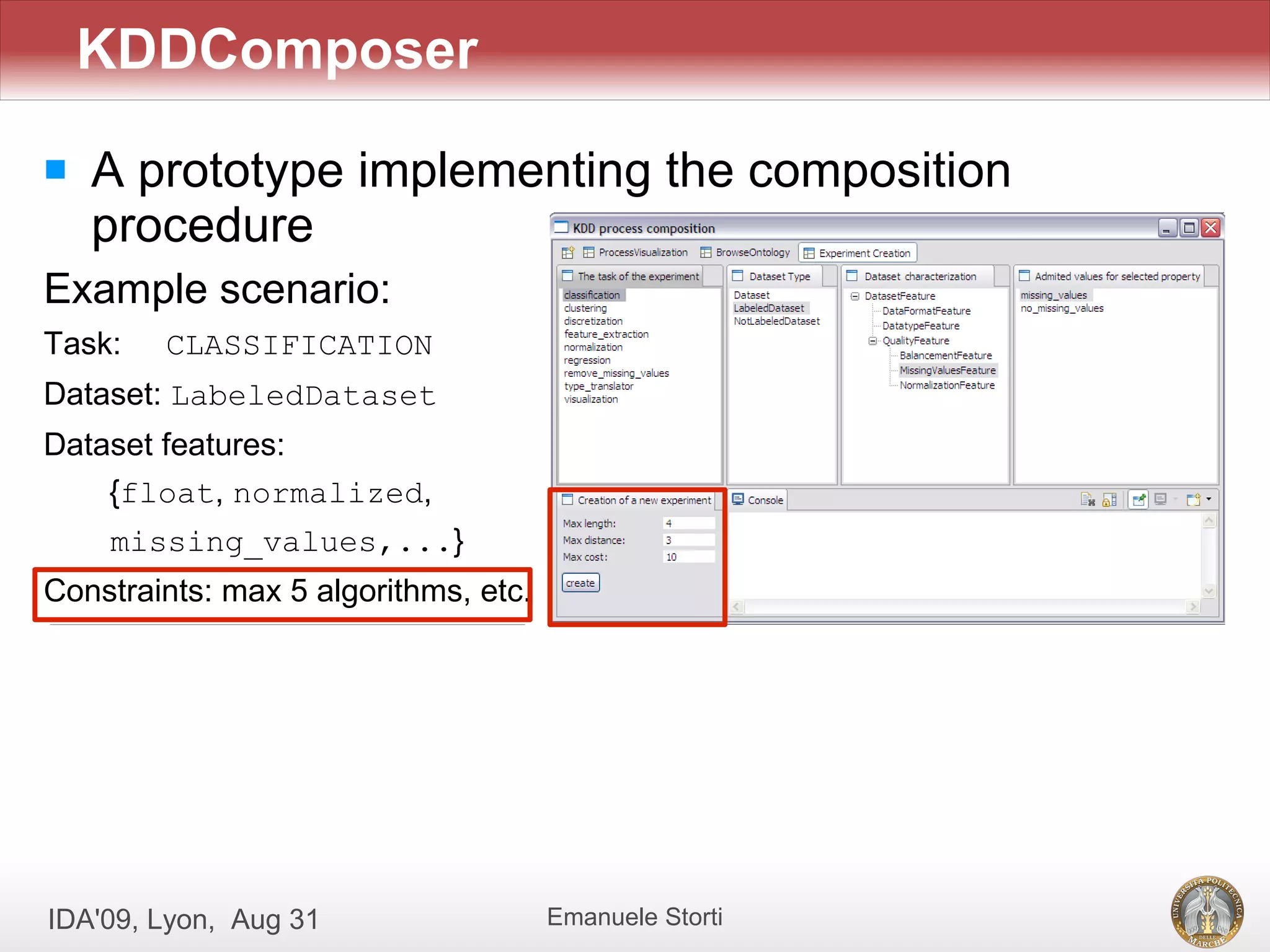










































![[Evaldas Taroza - Master thesis] Schema Matching and Automatic Web Data Extra...](https://cdn.slidesharecdn.com/ss_thumbnails/5c1568bc-753d-44dc-88ac-dcf114742b88-150313043325-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)
























