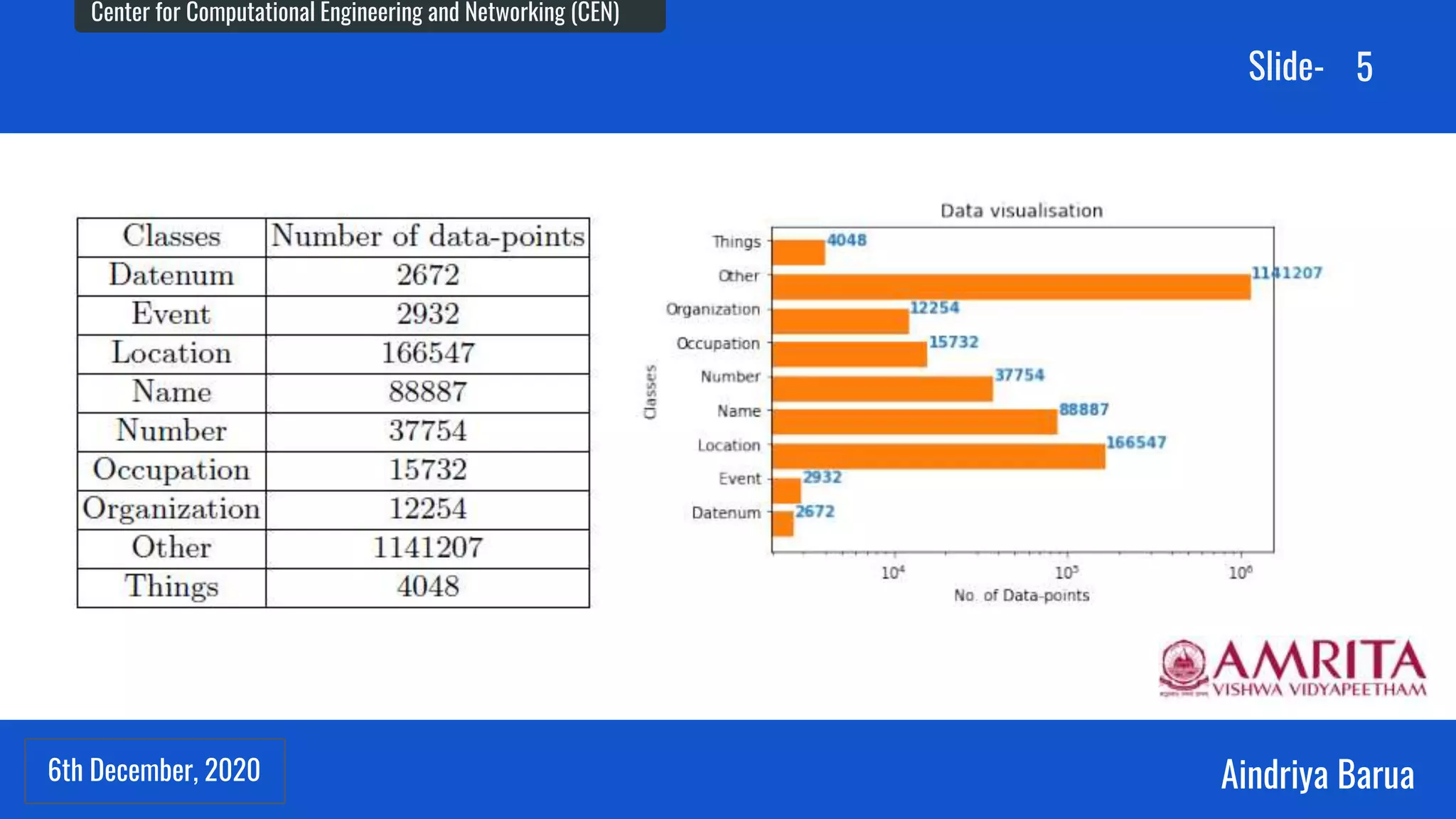
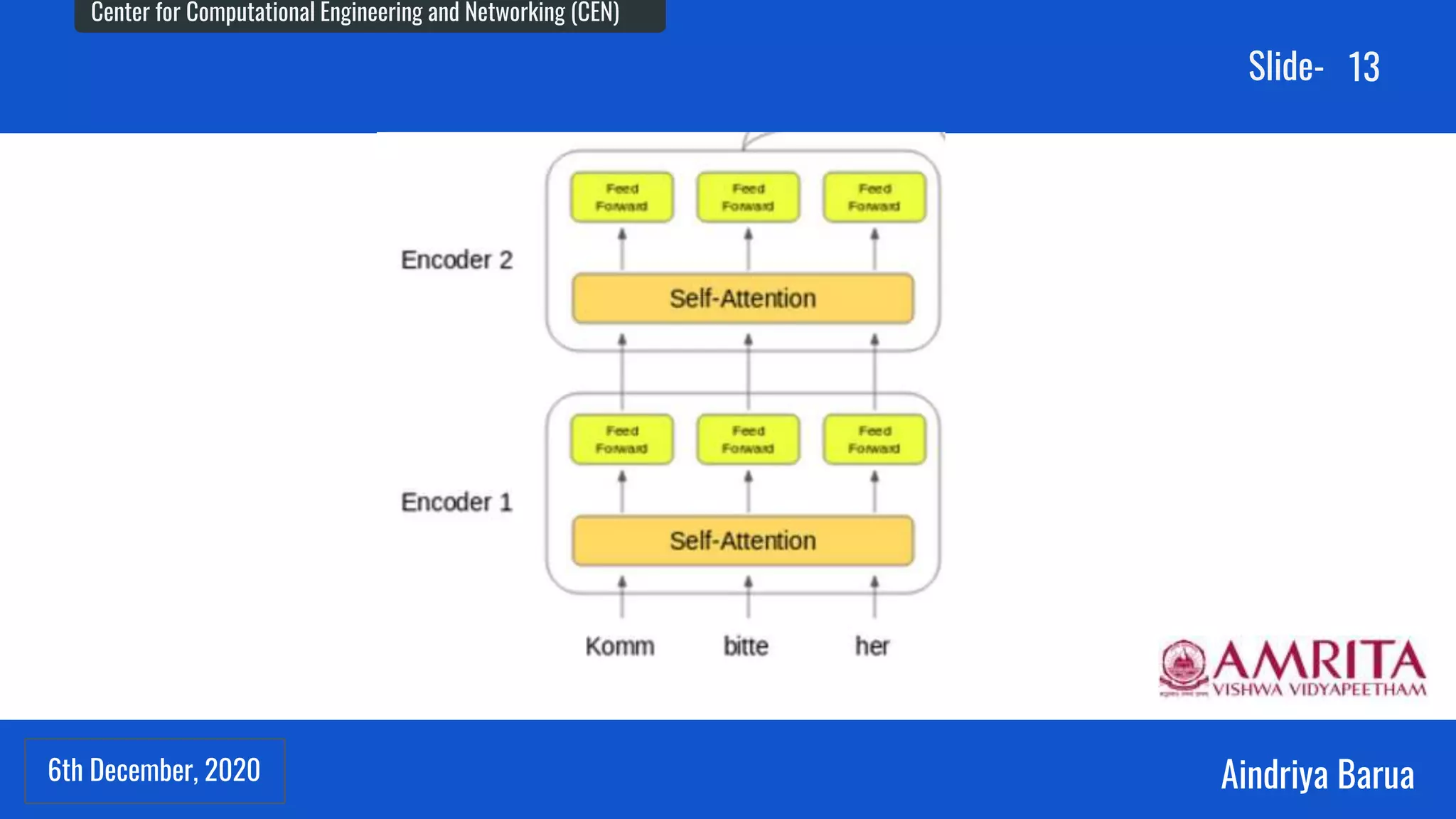
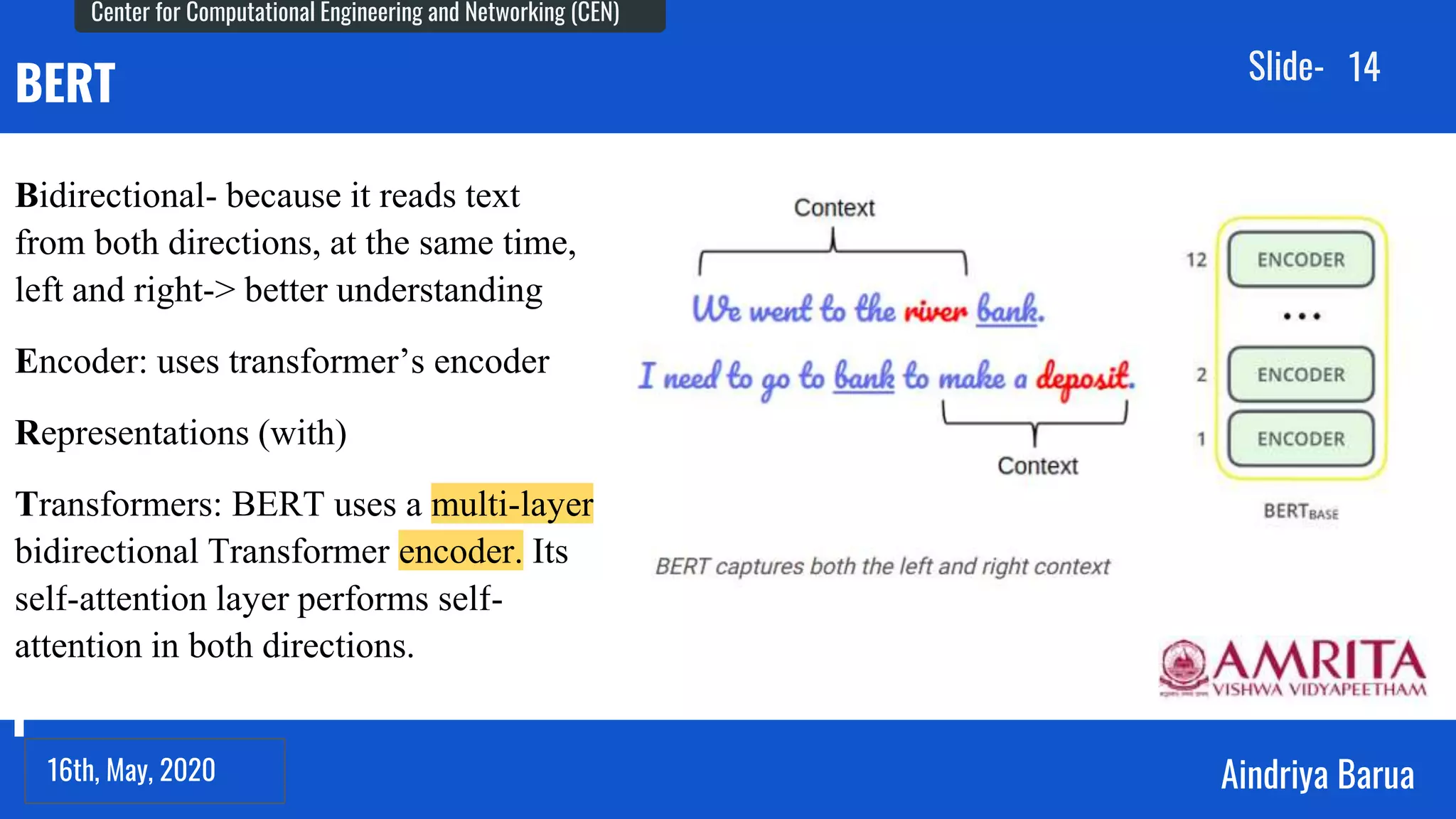
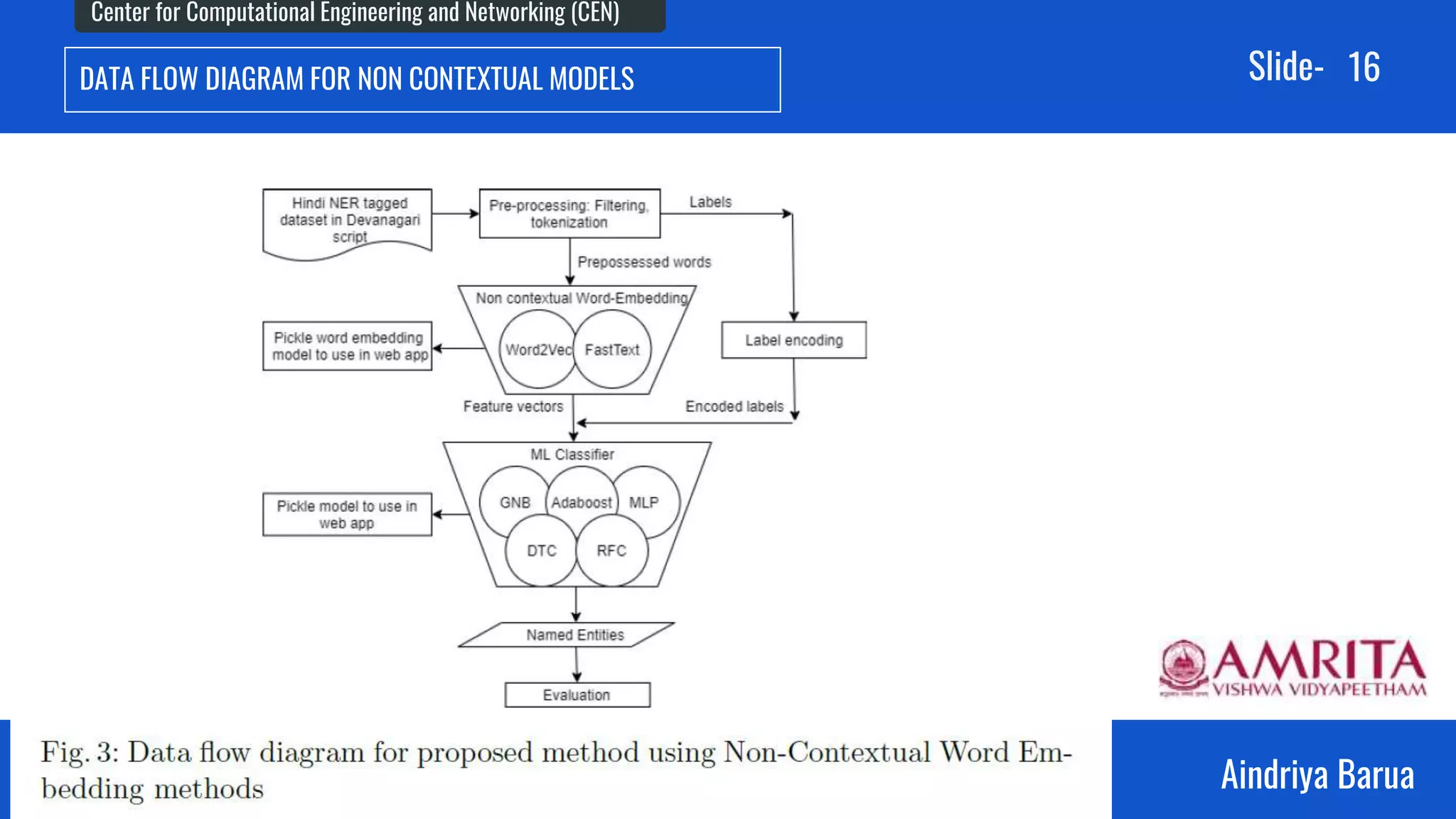
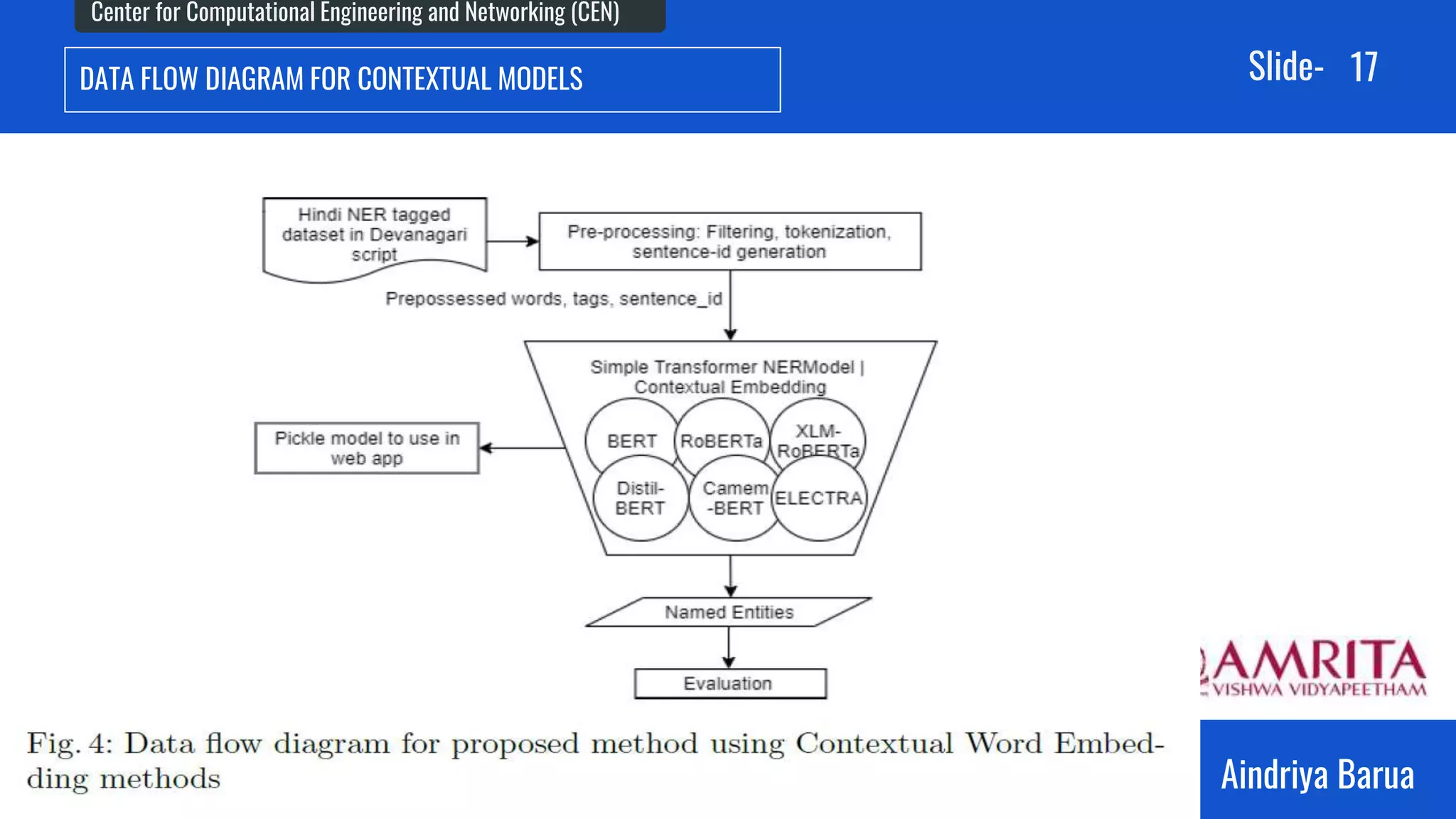
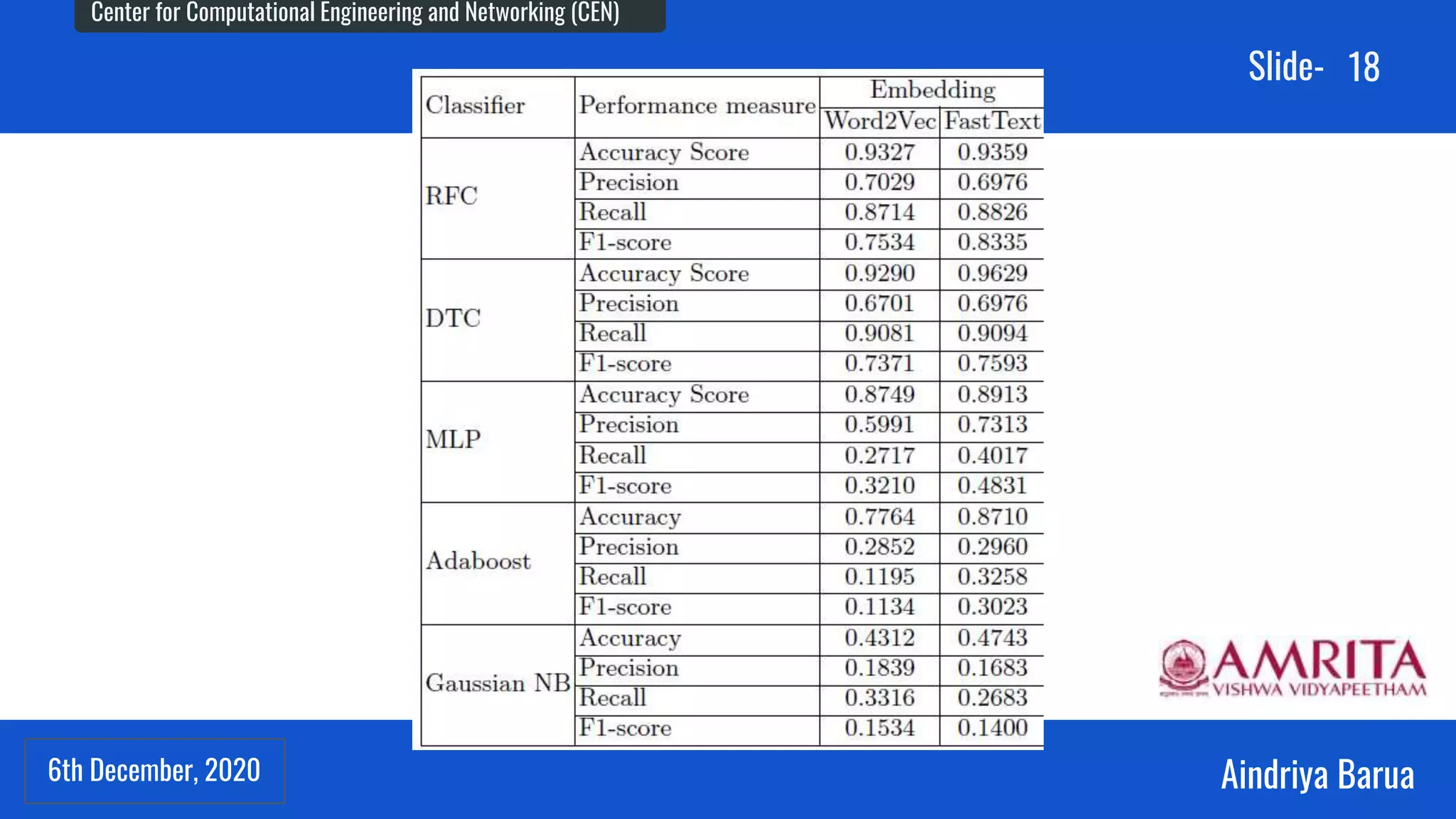
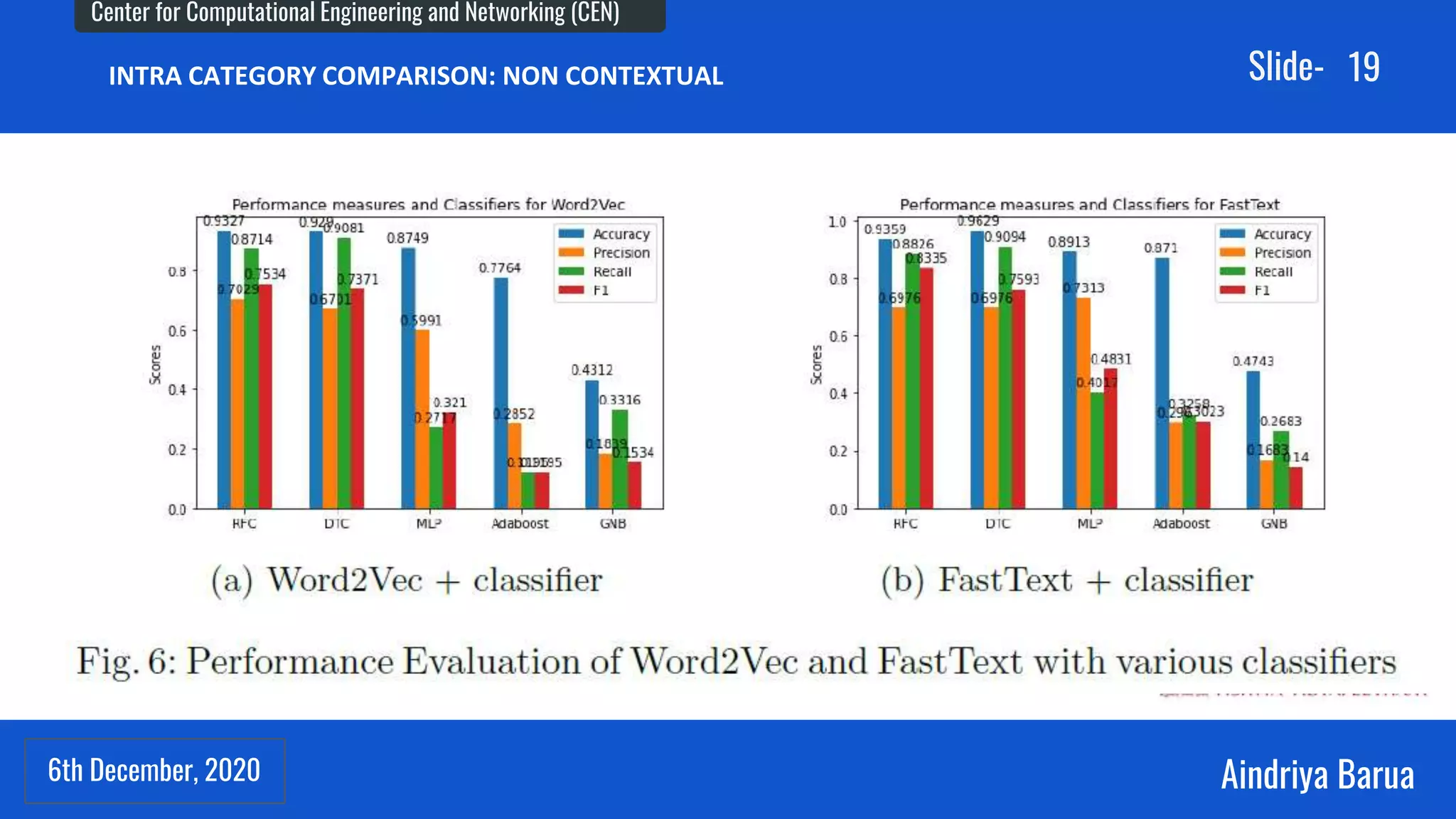
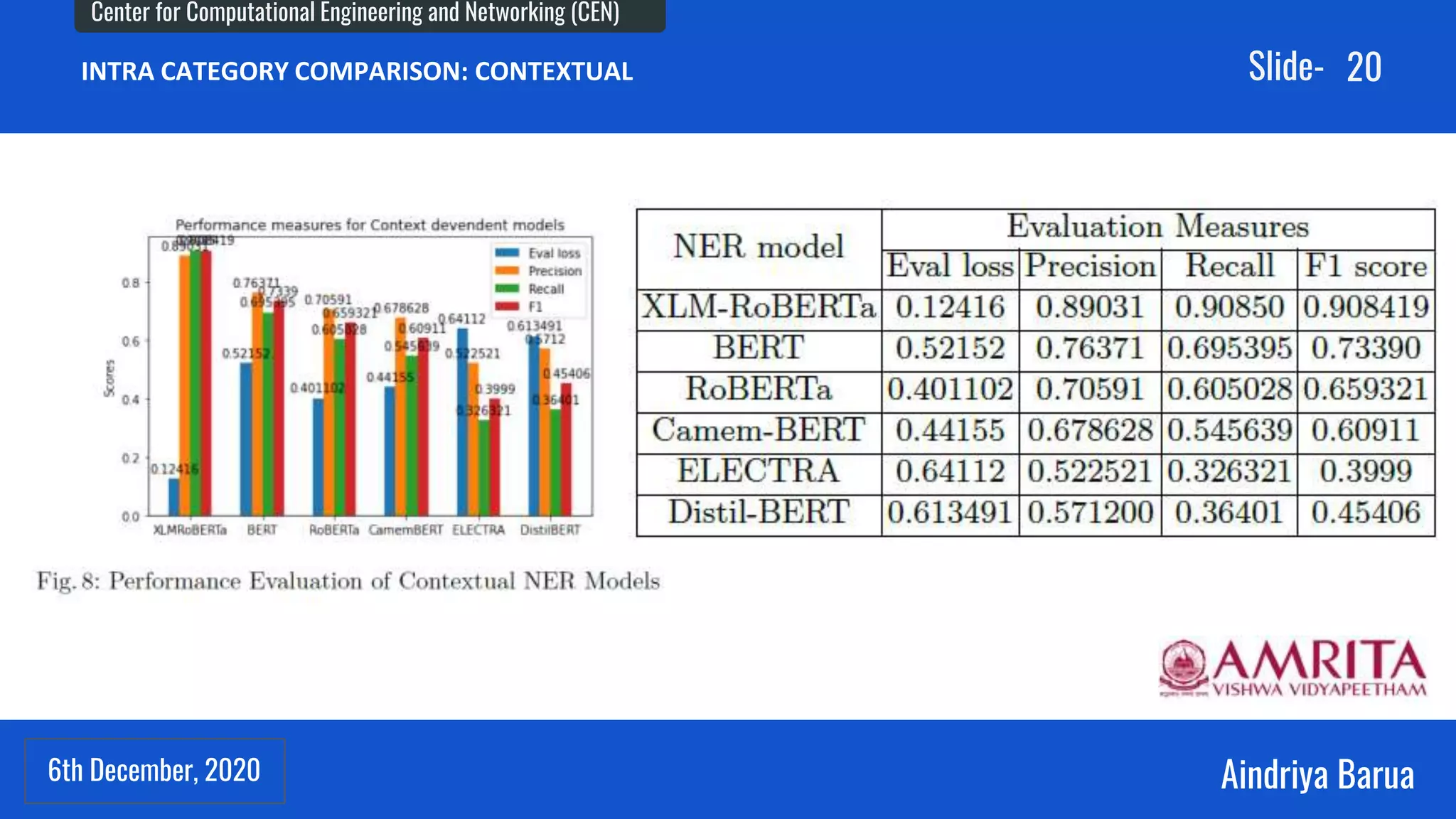
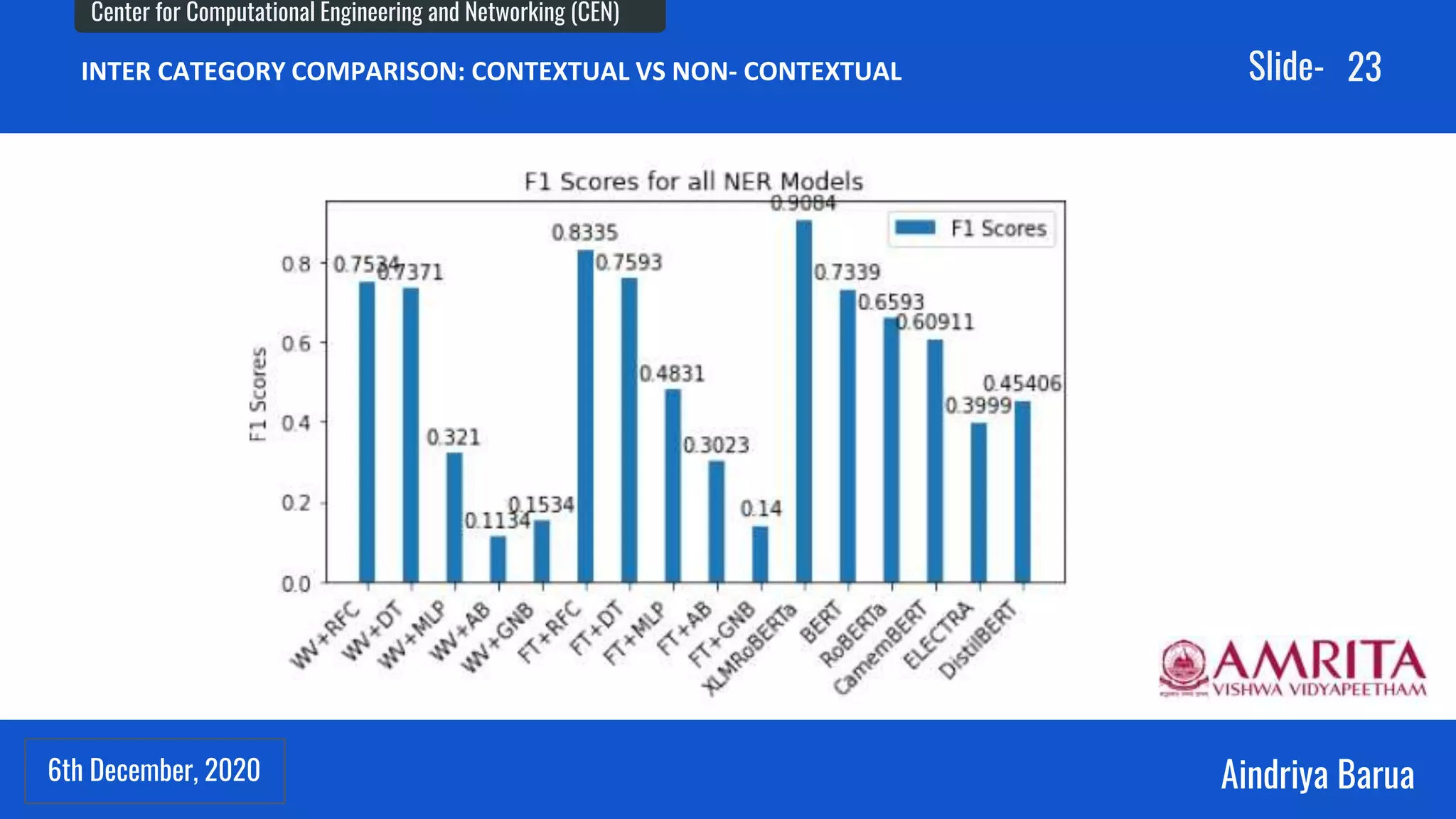
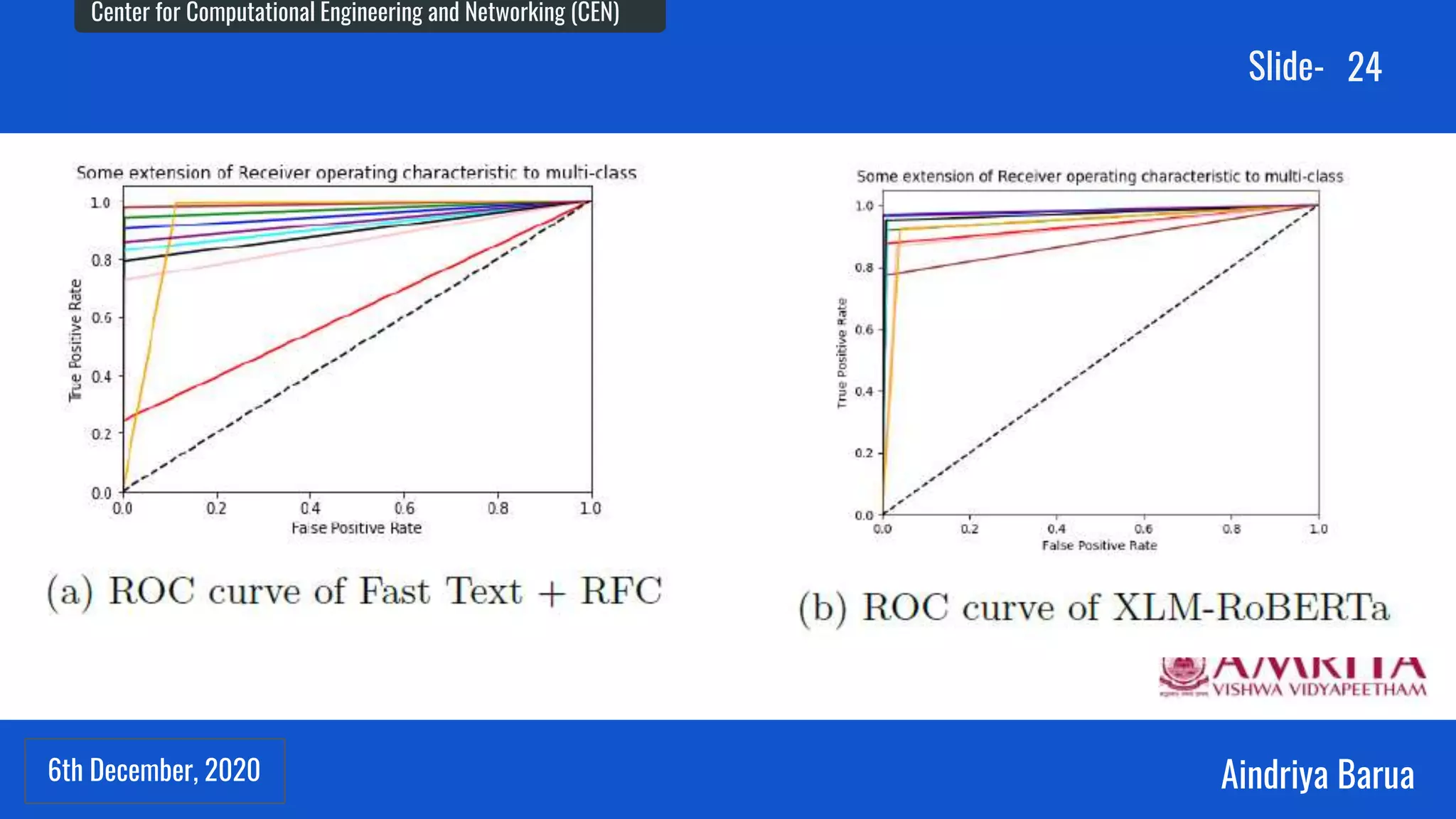
The document presents research on the analysis of contextual and non-contextual word embedding models for Named Entity Recognition (NER) in Hindi, along with the development of an interactive web application for data collection. It compares various models like word2vec, fasttext, BERT, and its variants, providing insights on their performance and potential applications in Indian languages. The study highlights future work directions, including hyper-parameter tuning and the incorporation of reinforcement learning for model improvement.