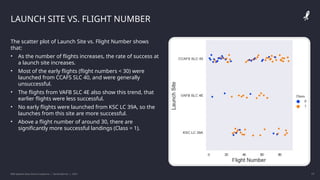
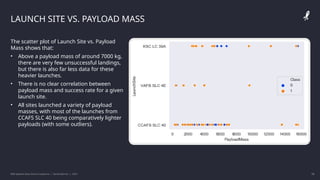
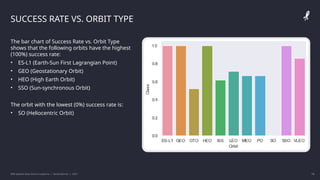
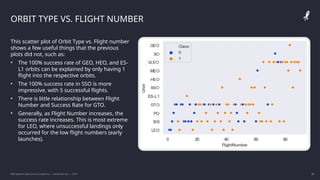
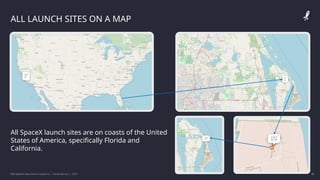
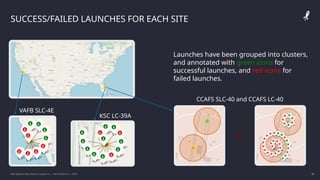
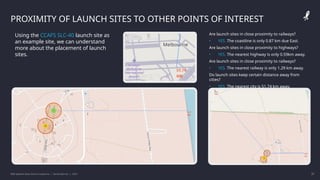
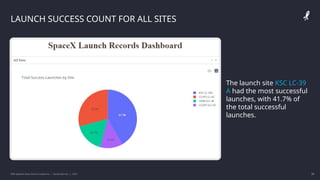
The IBM Data Science Capstone project by Daniel Barnes analyzes SpaceX's Falcon 9 landing success using methodologies such as data collection, exploratory data analysis, and predictive modeling. Key results include an interactive dashboard, geospatial analytics, and insights on the correlation between launch attributes and landing success. The project aims to predict whether the Falcon 9 first stage will land successfully, helping assess the cost-effectiveness of SpaceX's launches compared to other providers.
















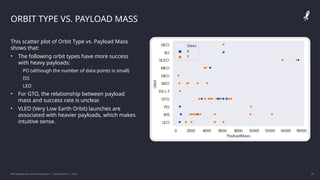
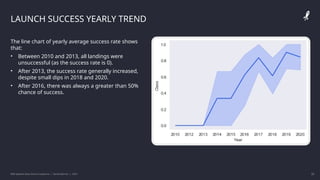


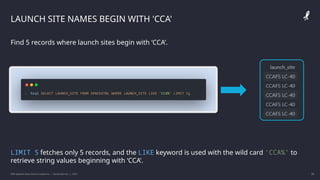






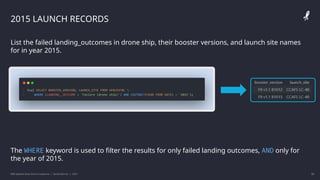





























































![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)















