Downloaded 12 times





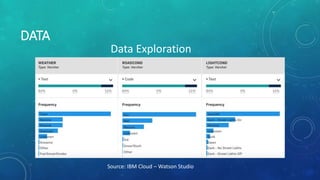
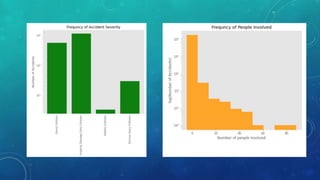
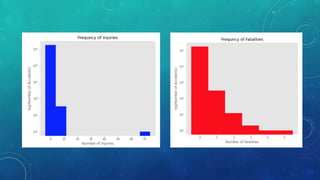

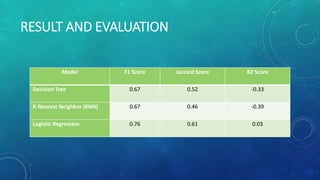



This document describes a capstone project to predict the severity of car accidents in Seattle using machine learning models. The project uses data from the Seattle Department of Transportation on accident characteristics and outcomes to build classification models including decision trees, KNN, and logistic regression. The logistic regression model achieved the best performance with an F1 score of 0.76 and R2 score of 0.03. In conclusion, the author states that such a model could help emergency services, insurers, and transit agencies respond to accidents.
























































