Download to read offline







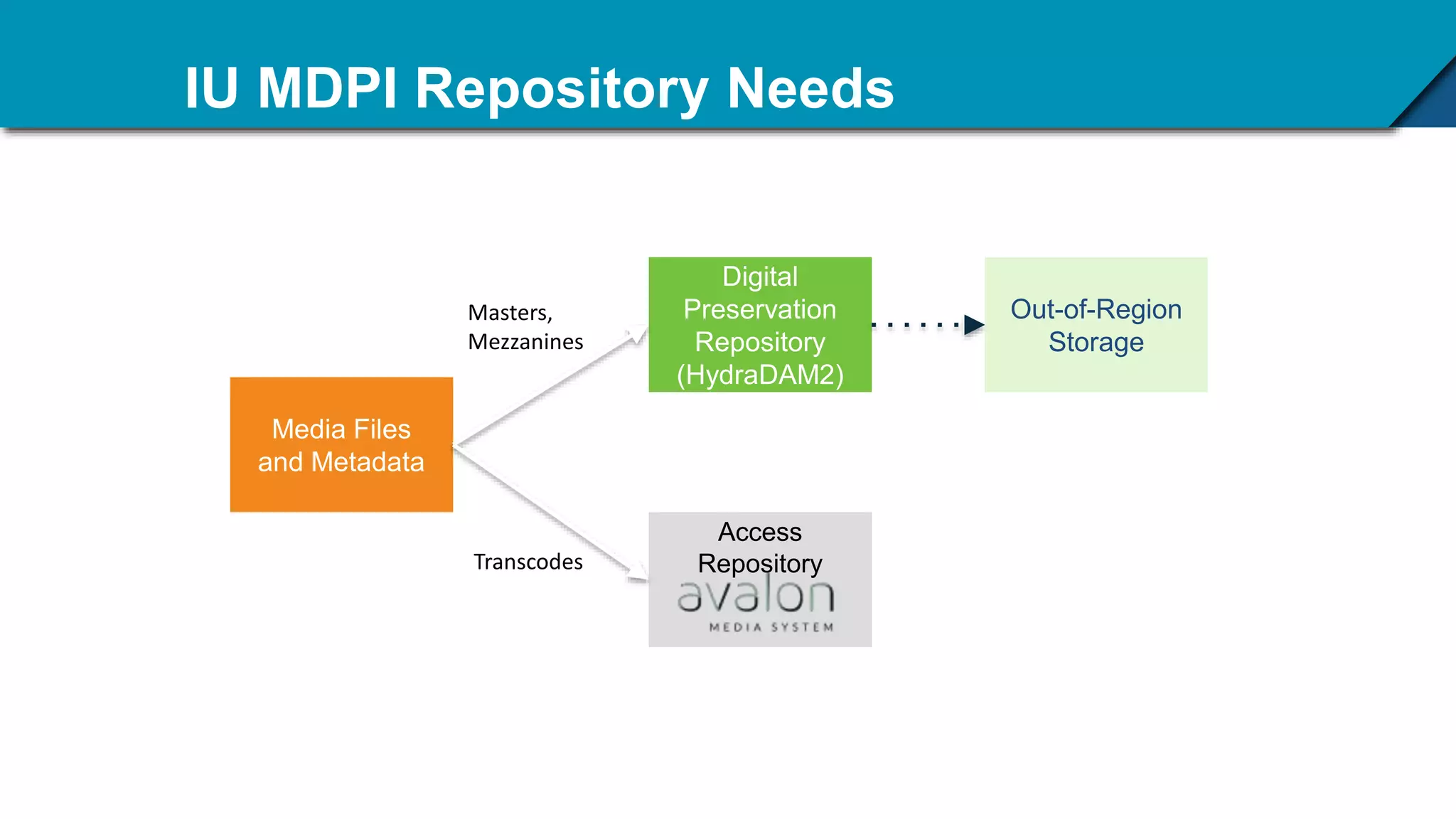







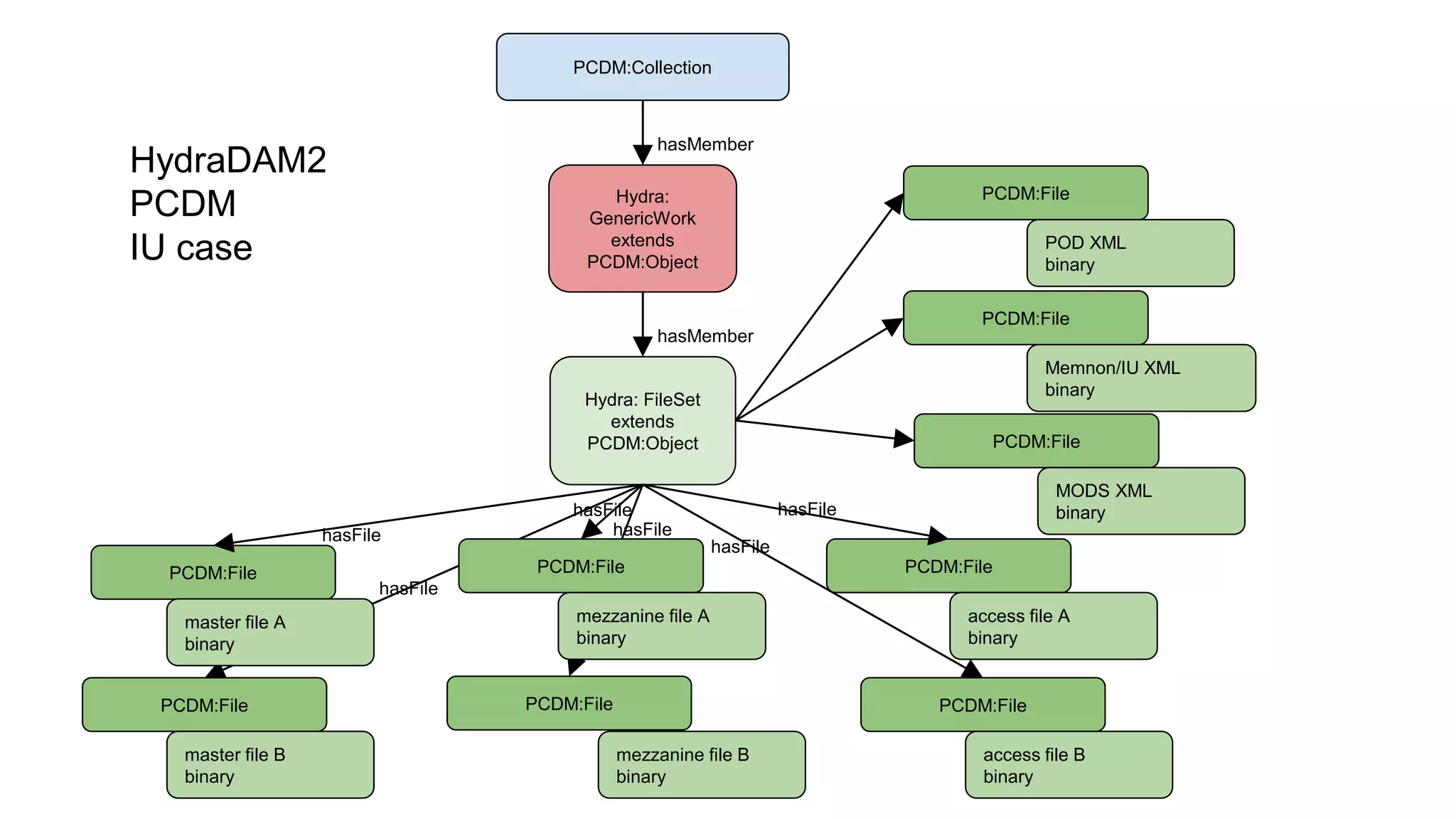
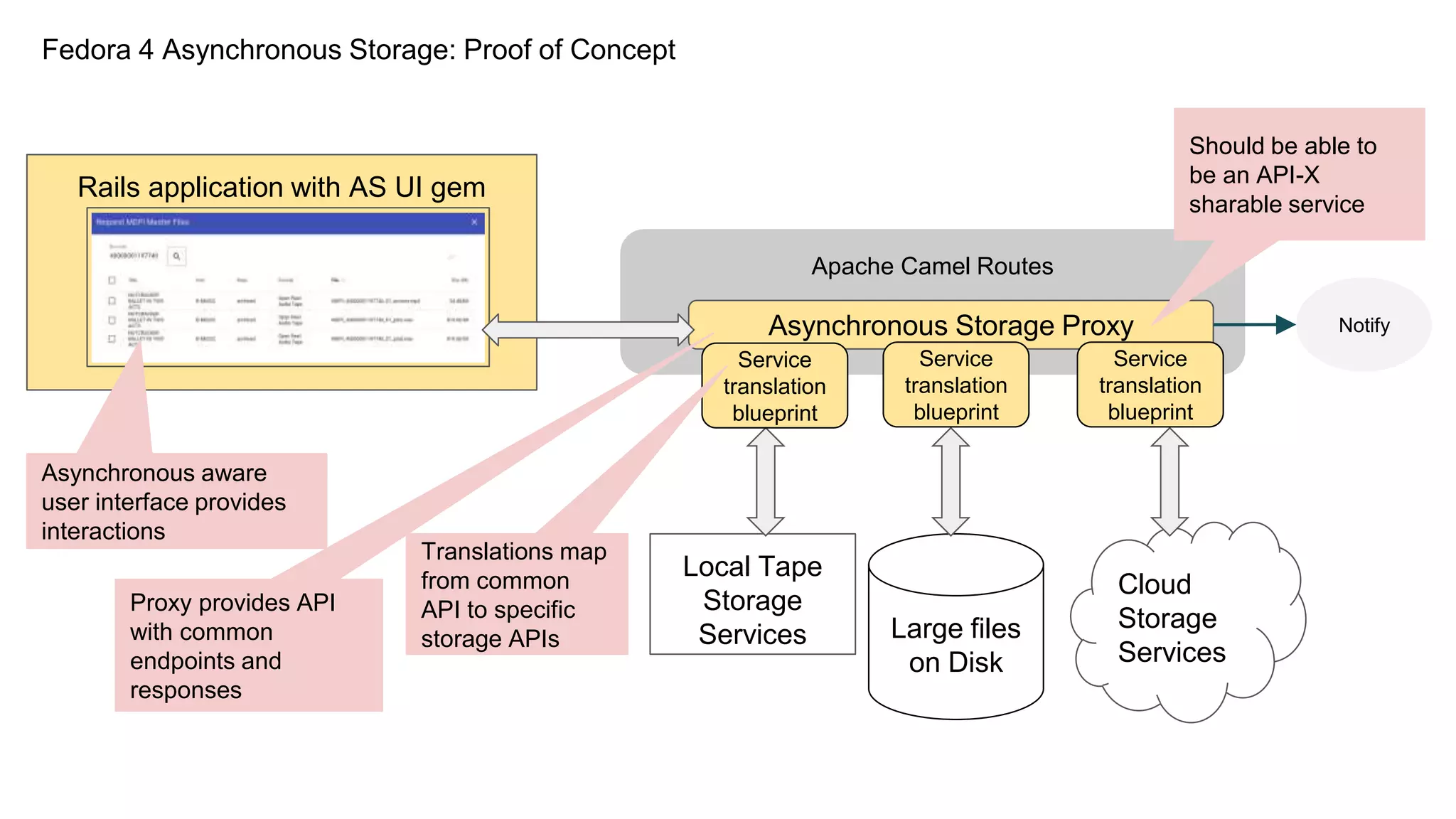
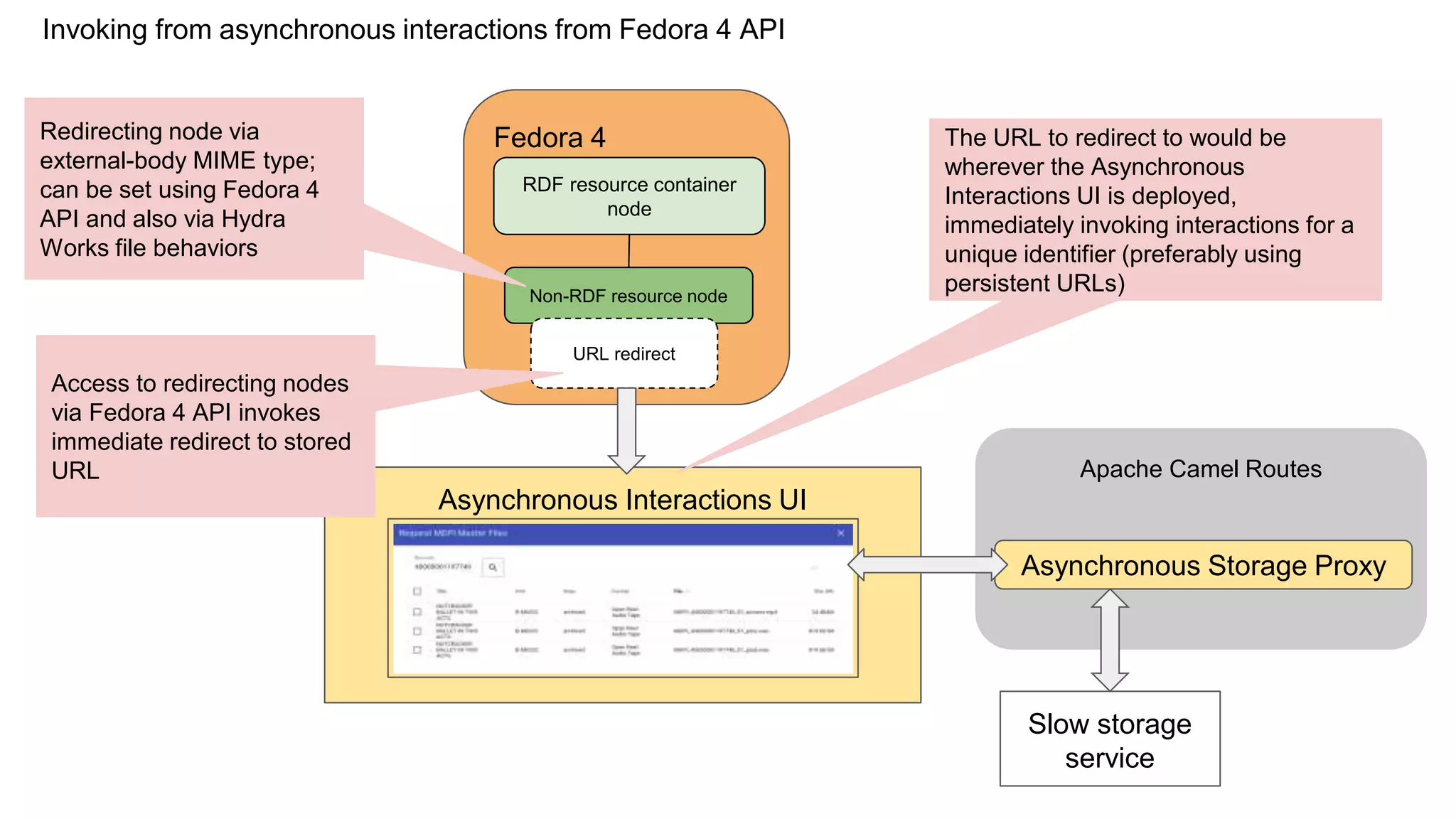

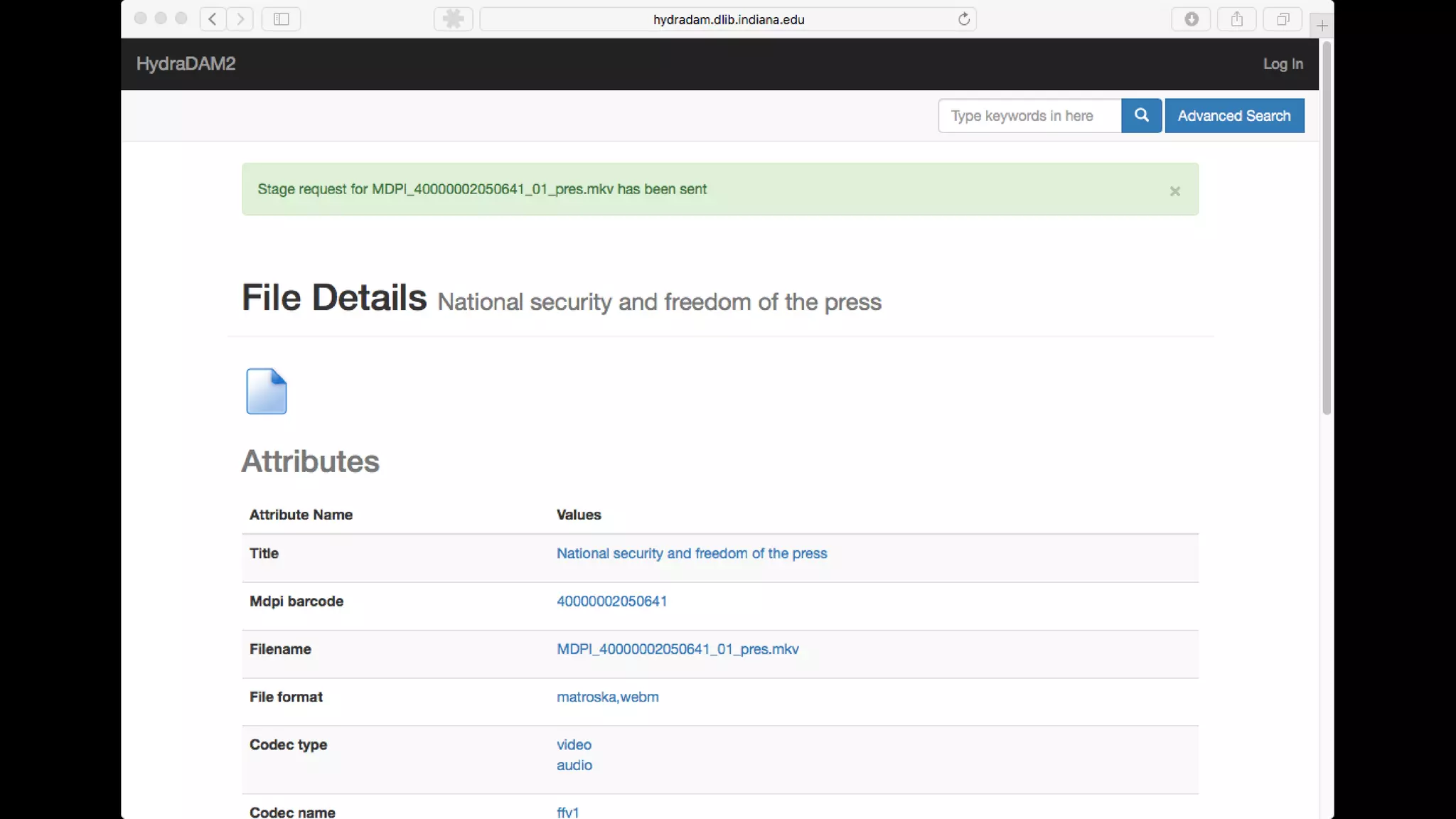
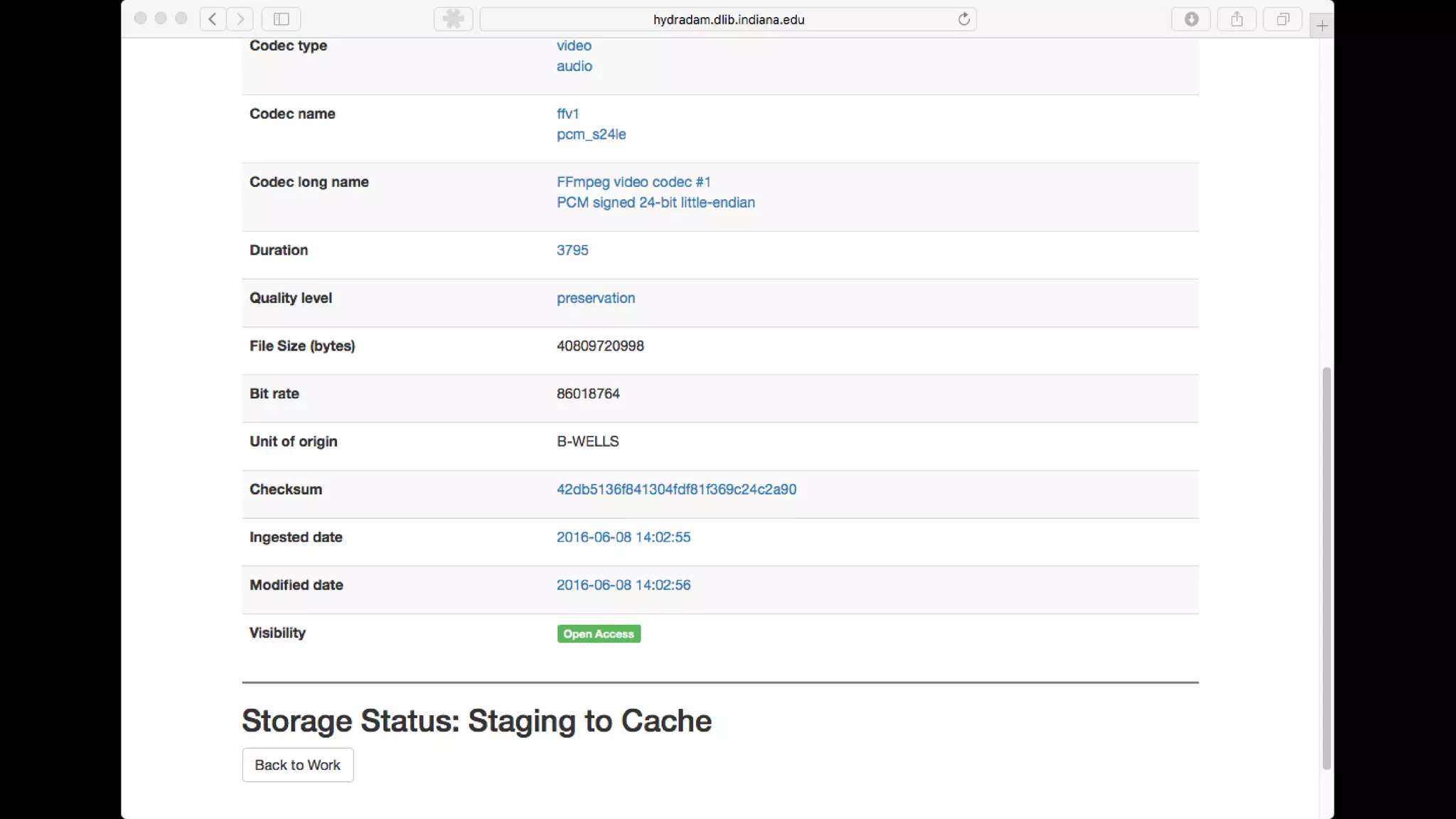
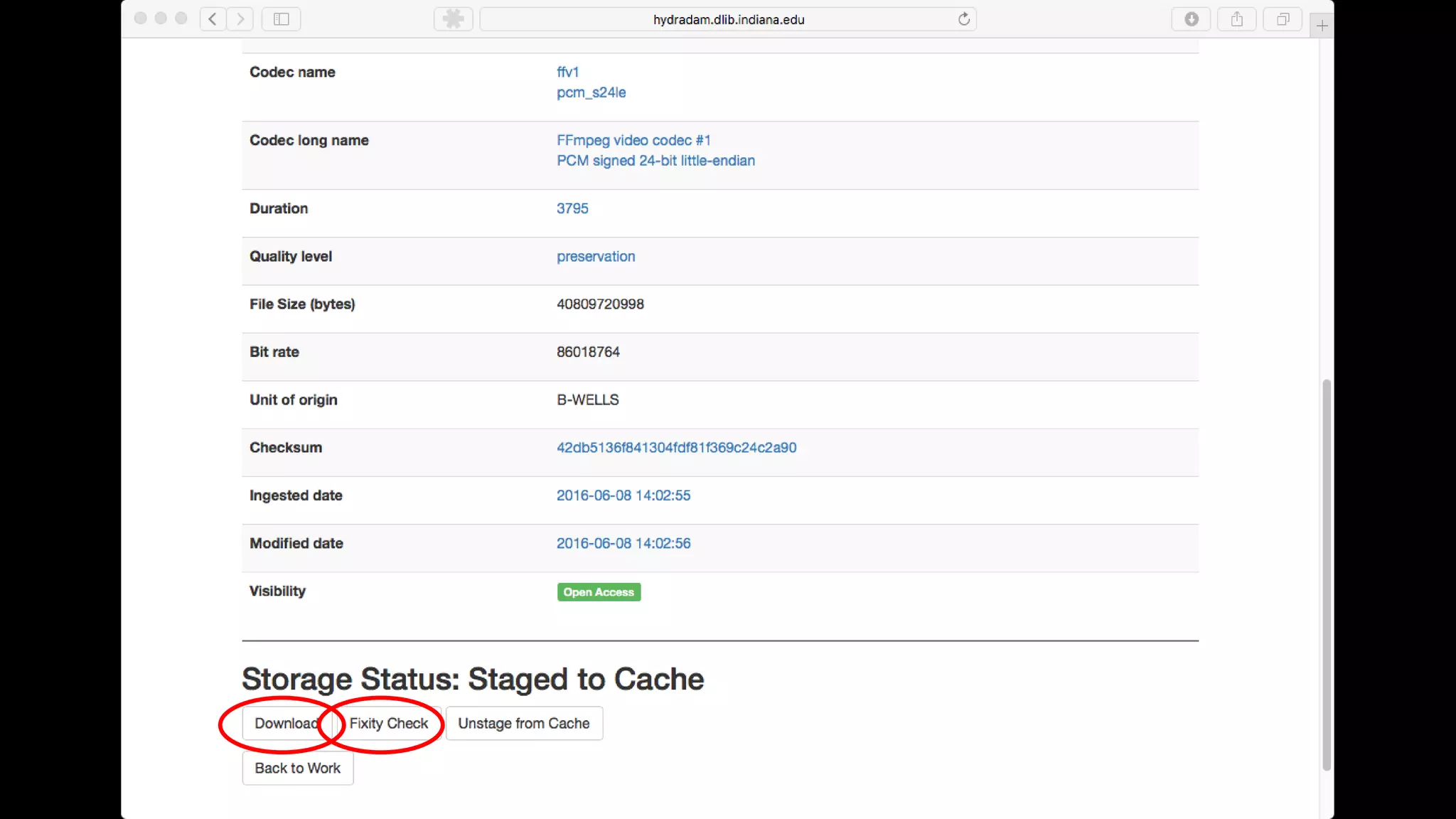
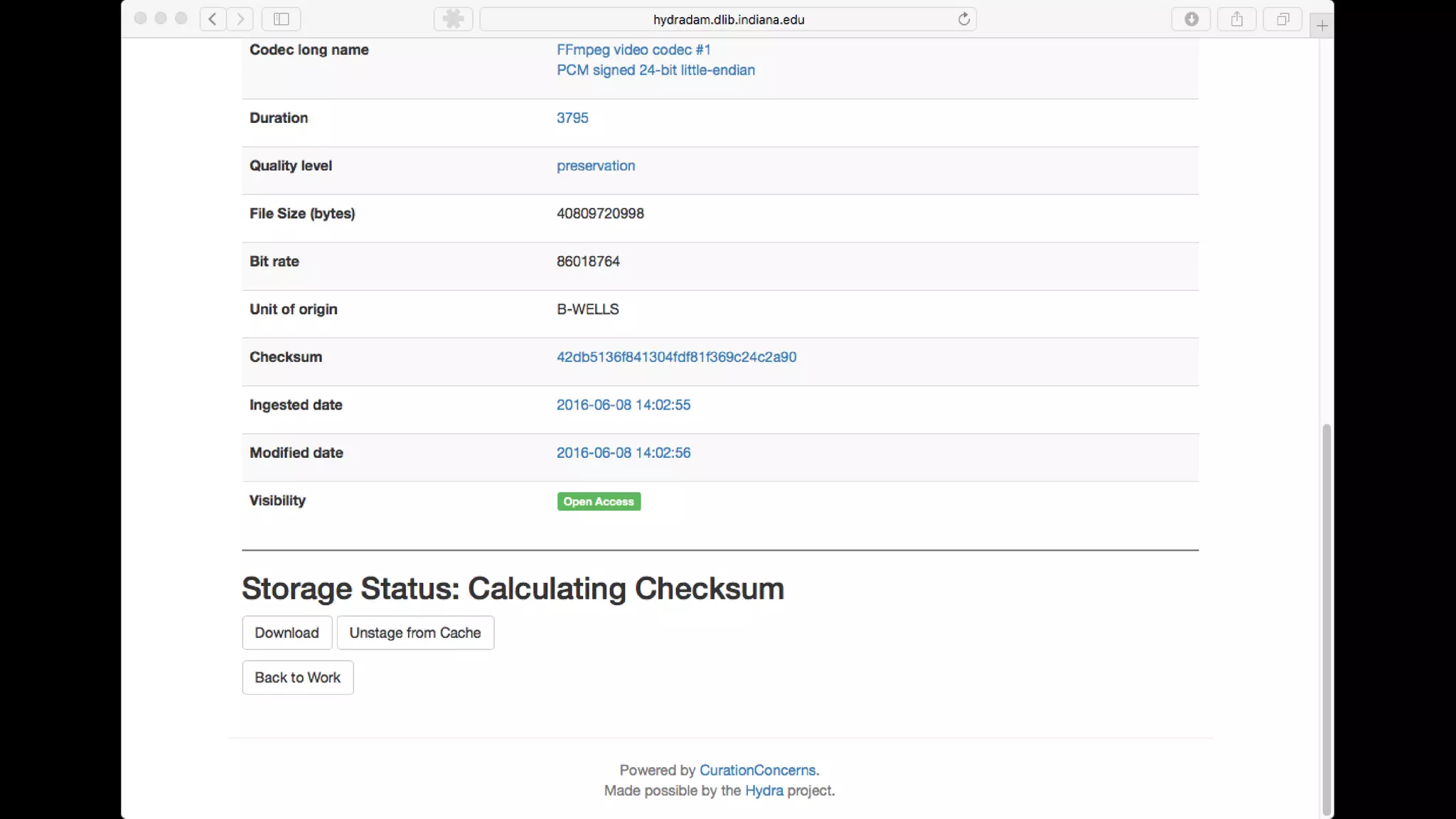



The Hydradam2 project aims to enhance digital asset management for audio and video preservation, addressing challenges such as metadata management and file storage needs at Indiana University and WGBH. It seeks to integrate with Fedora 4 for improved workflows and data modeling while facilitating the preservation of large media files, with a goal of universal accessibility by the IU bicentennial. The project includes collaboration across organizations, focusing on the development of storage solutions tailored to varying institutional requirements.
































































