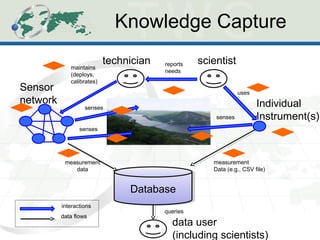
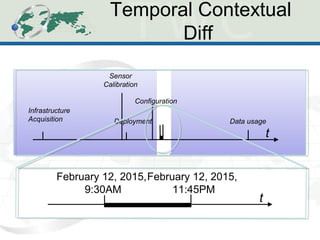
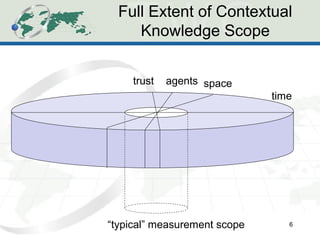
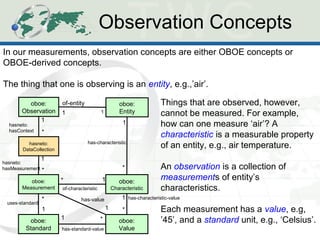
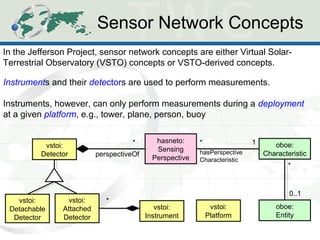
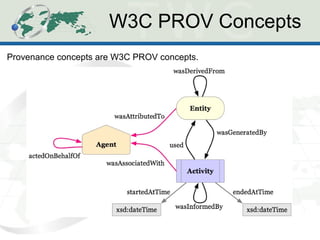
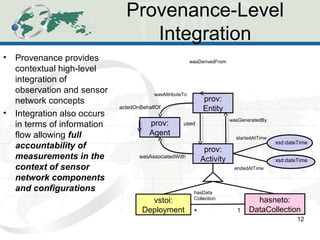
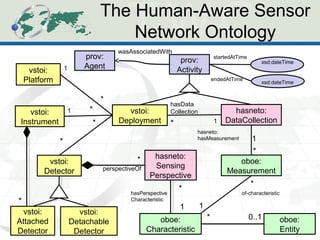
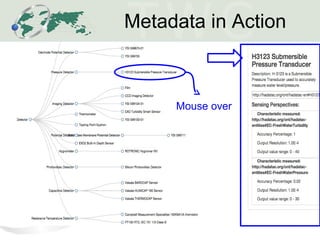
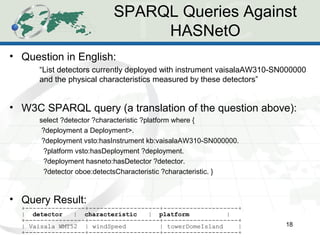
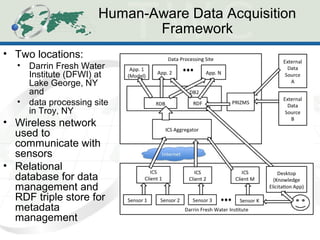
The document describes the Human-Aware Sensor Network Ontology (HASNetO), which provides semantic support for capturing contextual knowledge about empirical data collected by sensor networks. HASNetO integrates concepts from existing ontologies related to observations, sensors, and provenance to comprehensively describe sensor network measurements and associated contextual knowledge. This includes knowledge about sensor deployments, configurations, and data usage that is important but often not captured in sensor data alone. HASNetO is being developed and tested on data from two environmental monitoring sites.