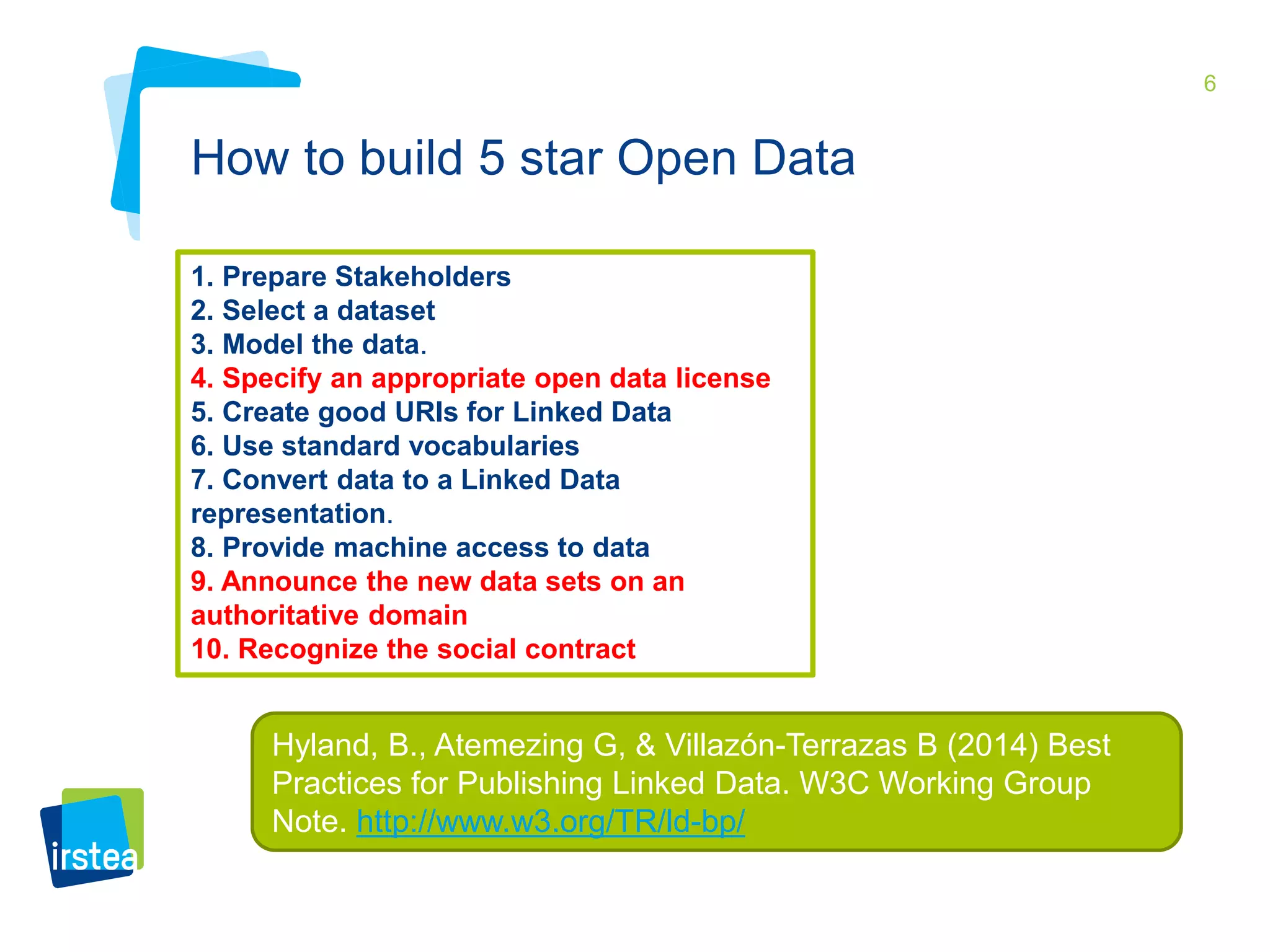
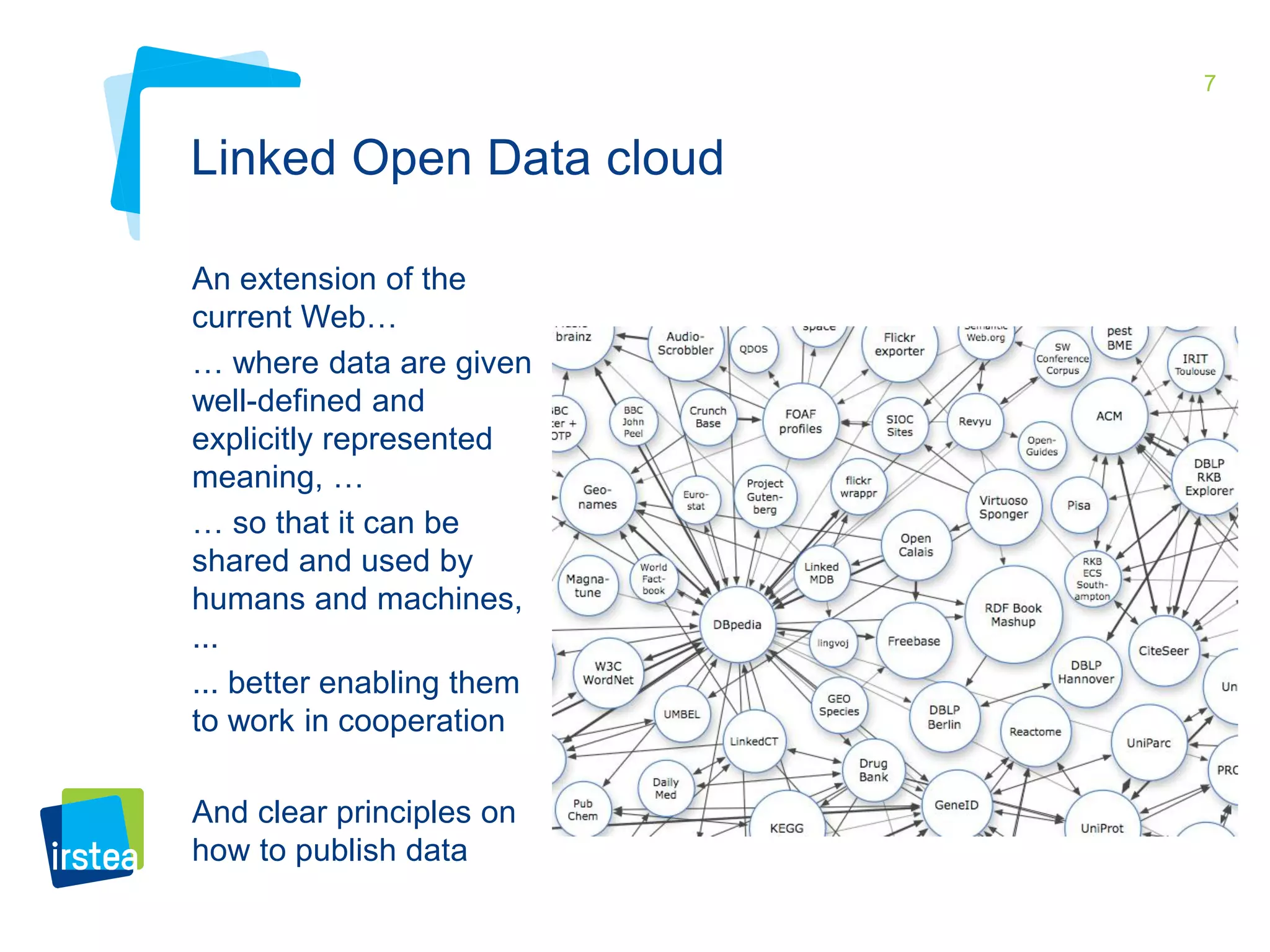
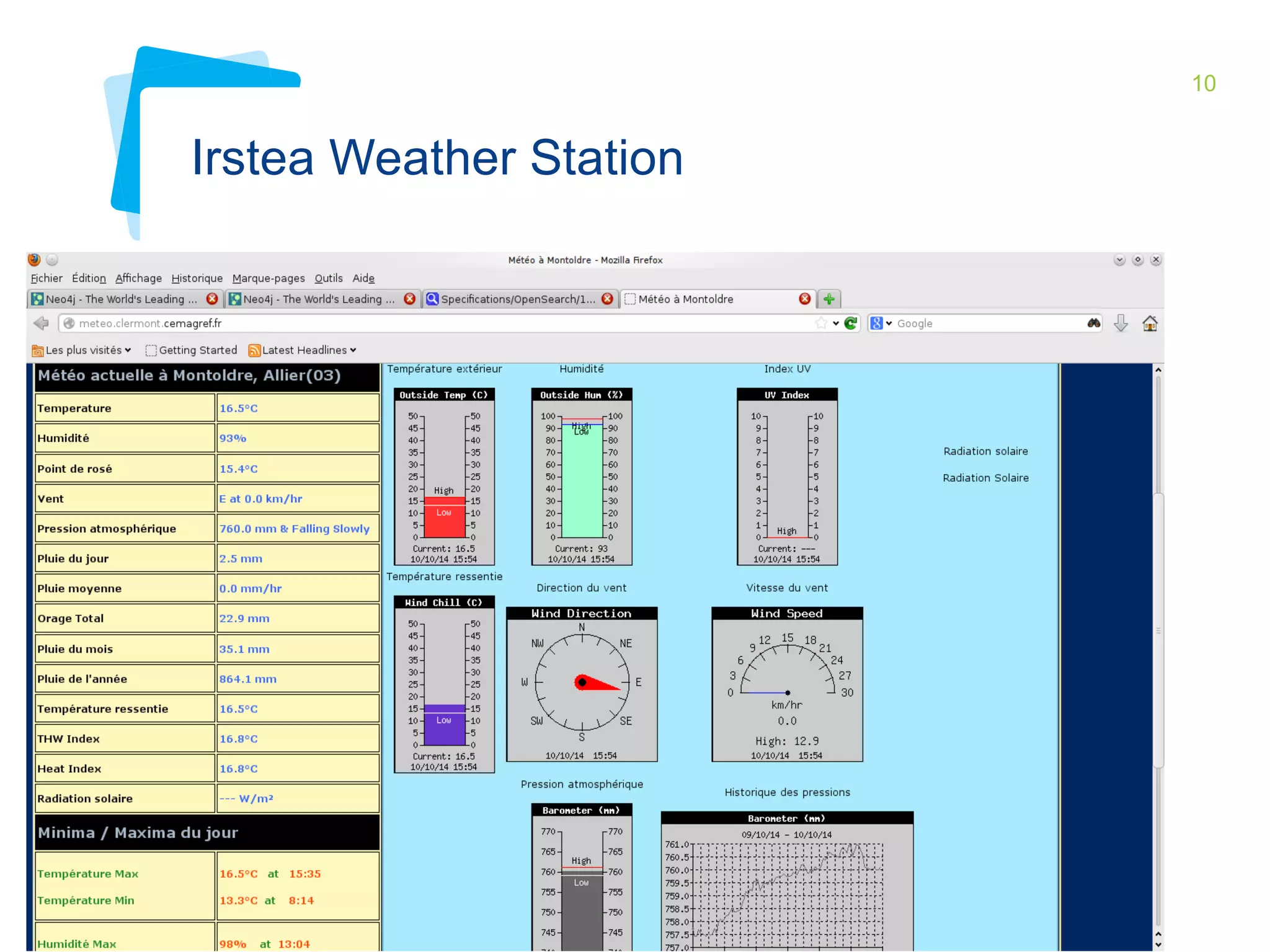
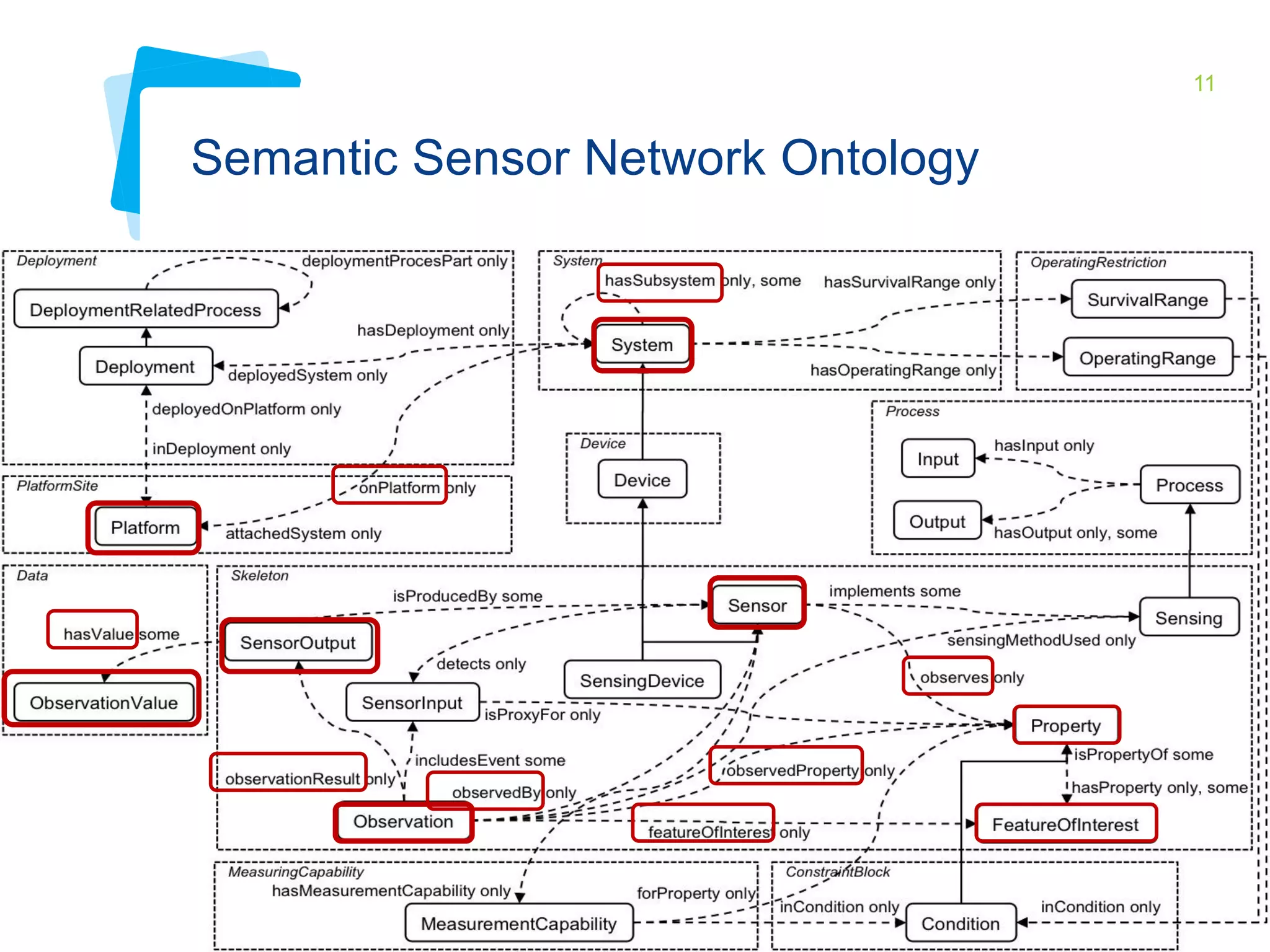
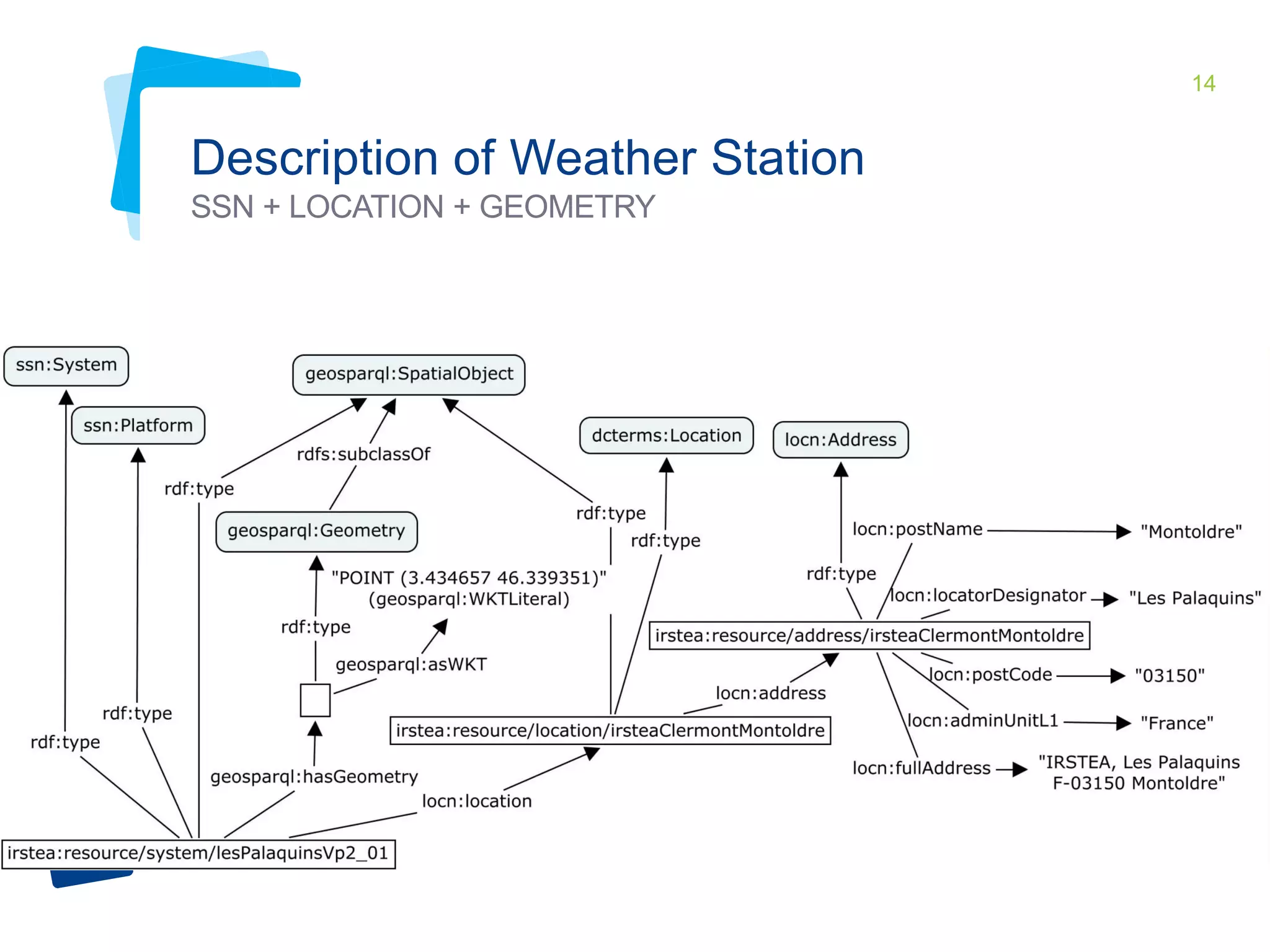
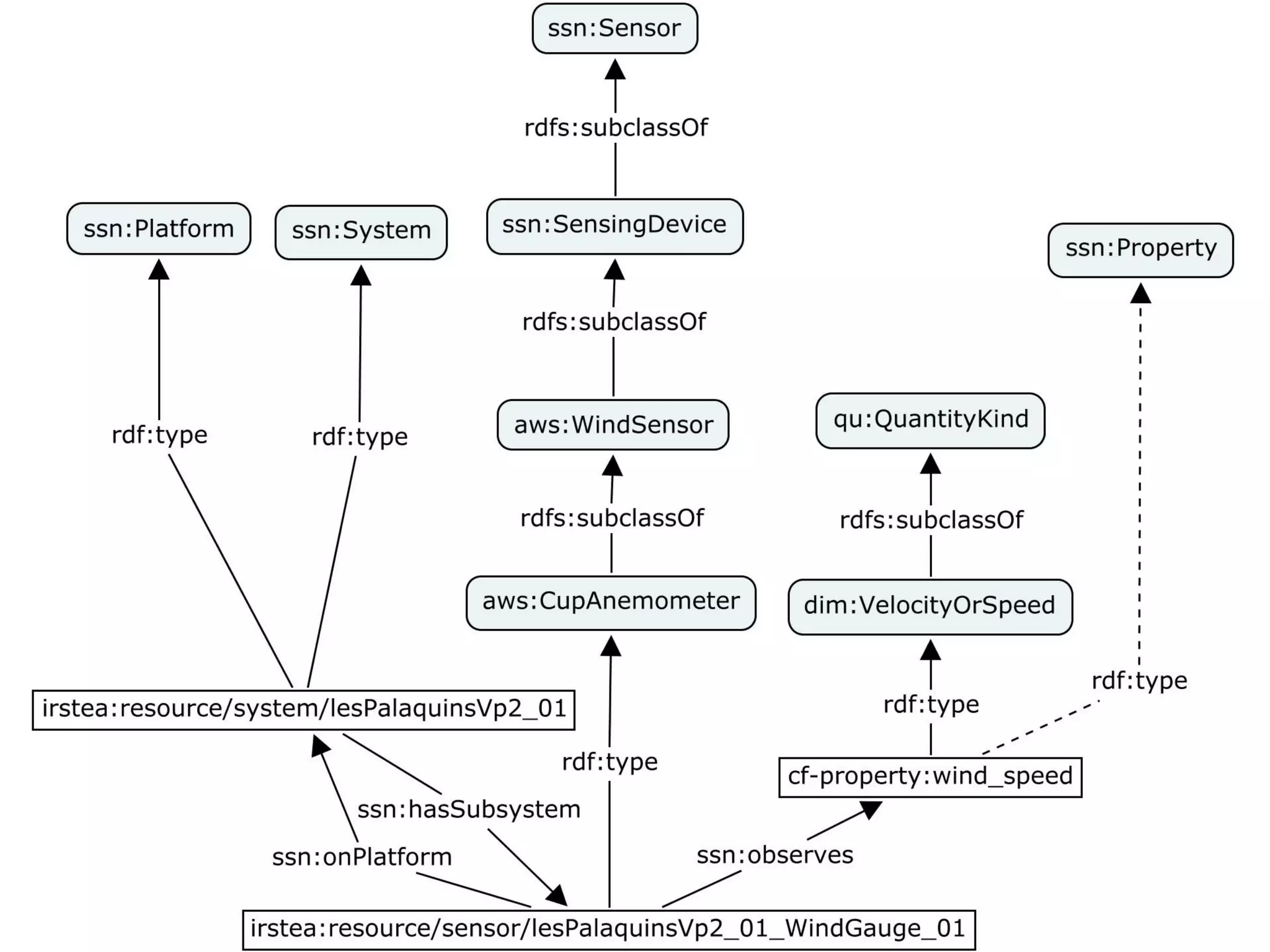
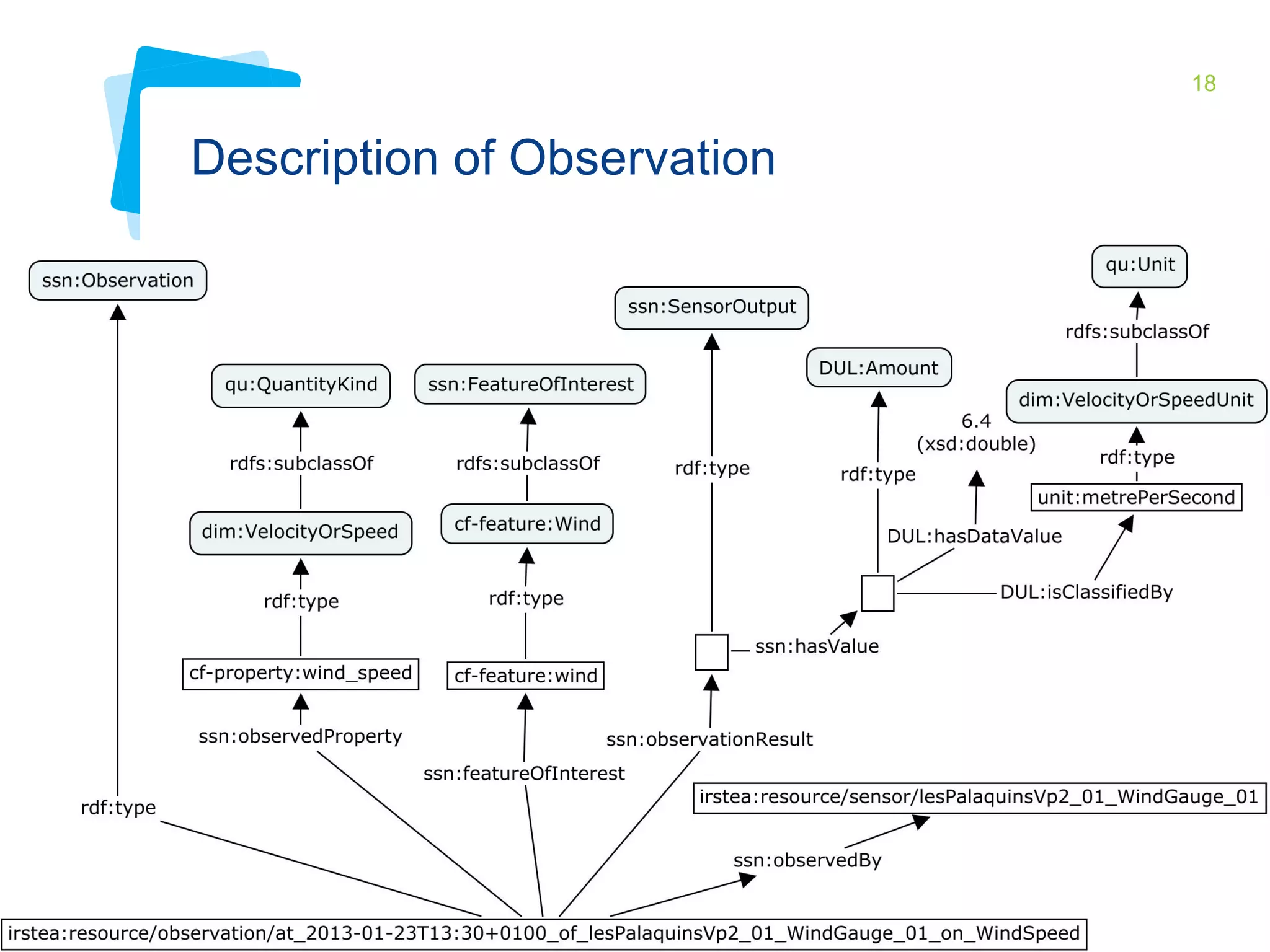
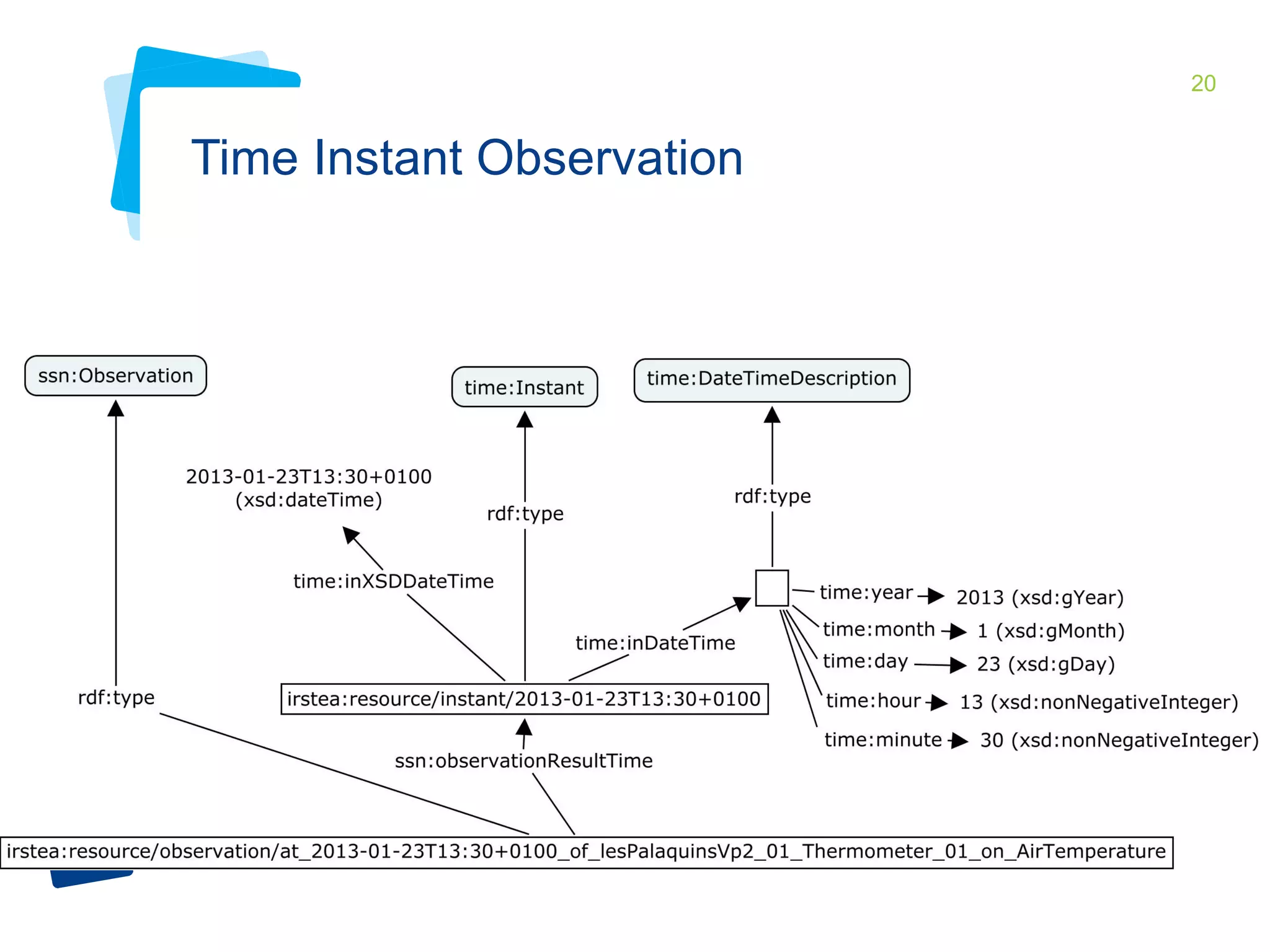
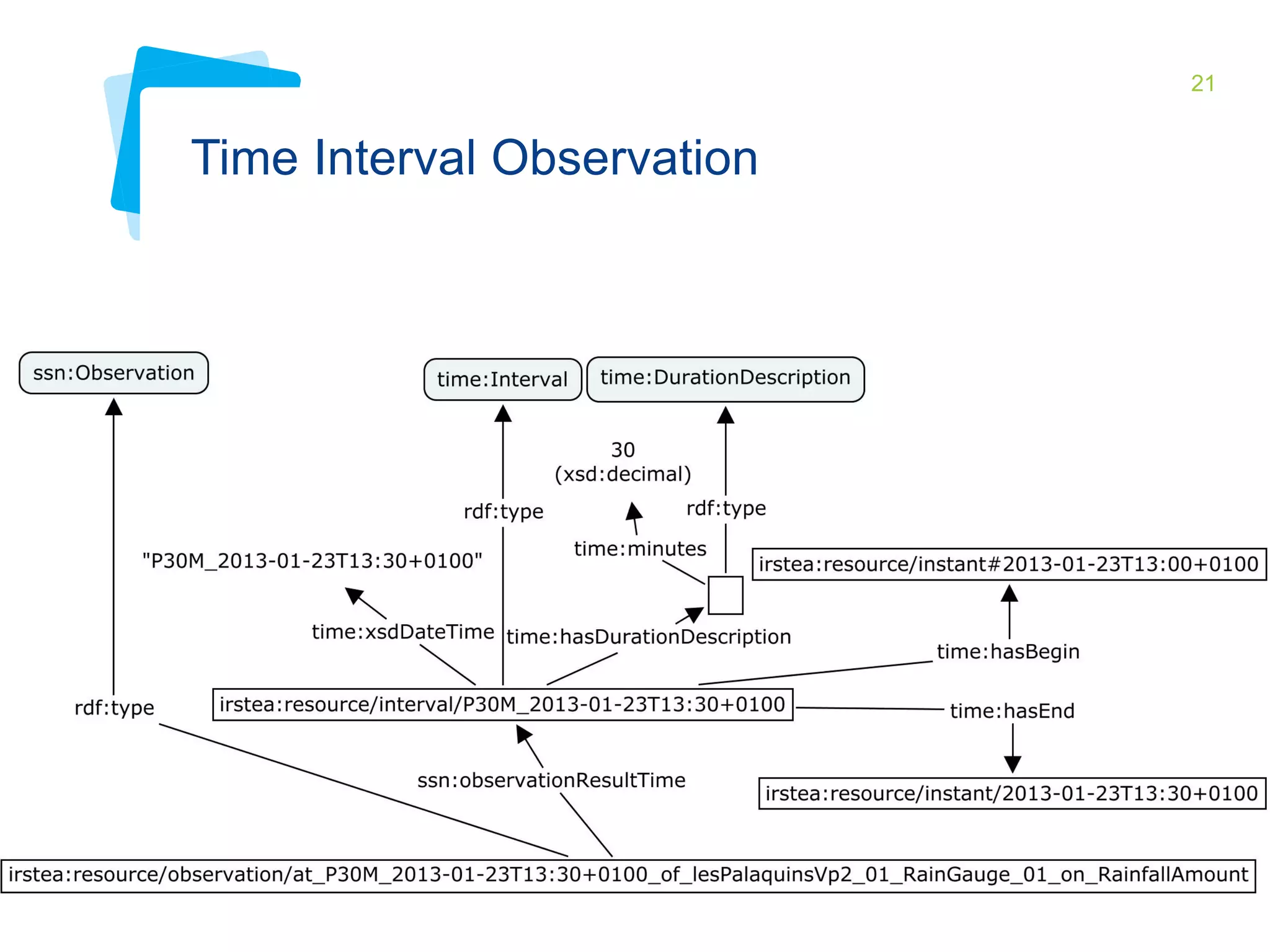
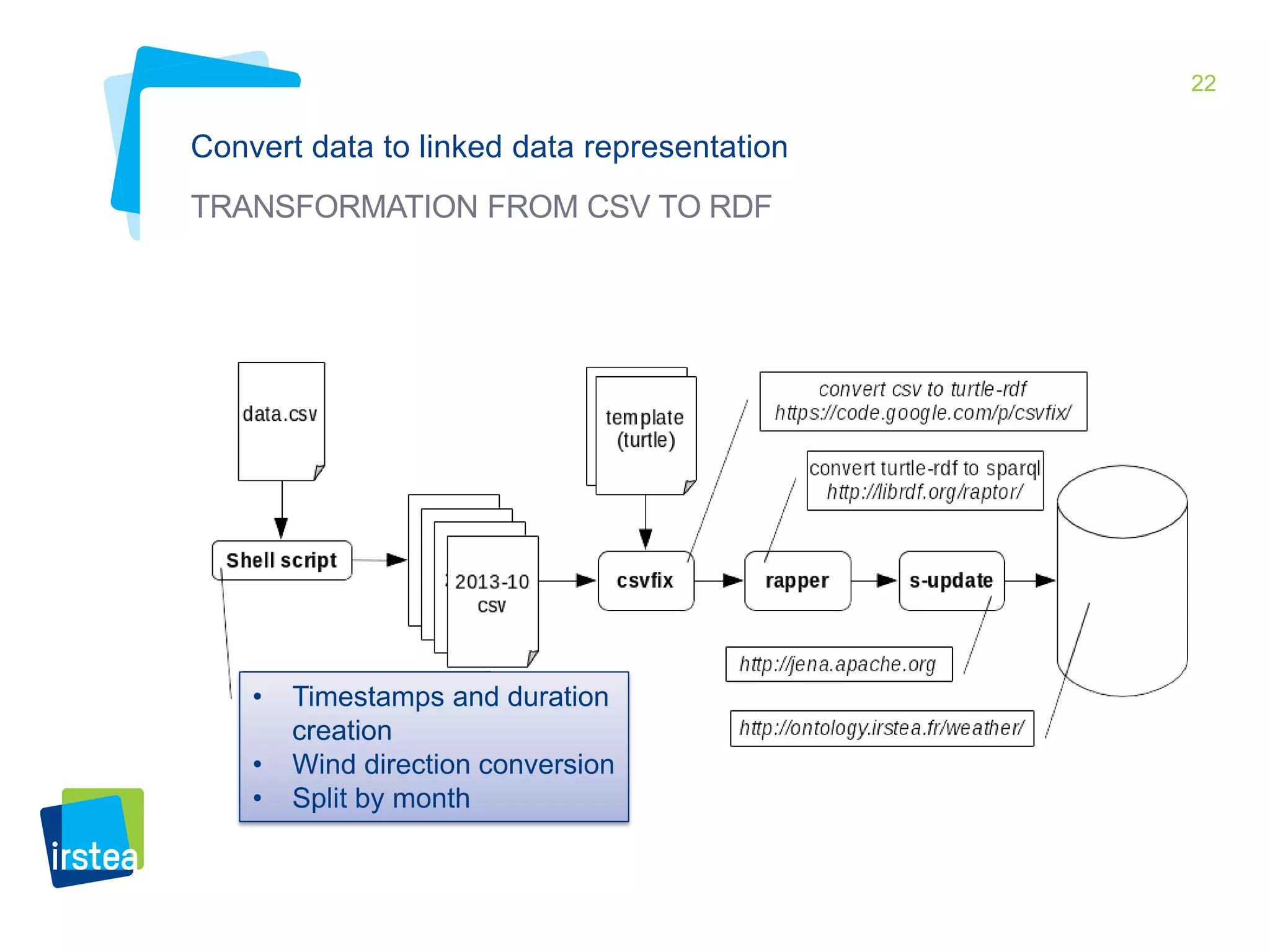
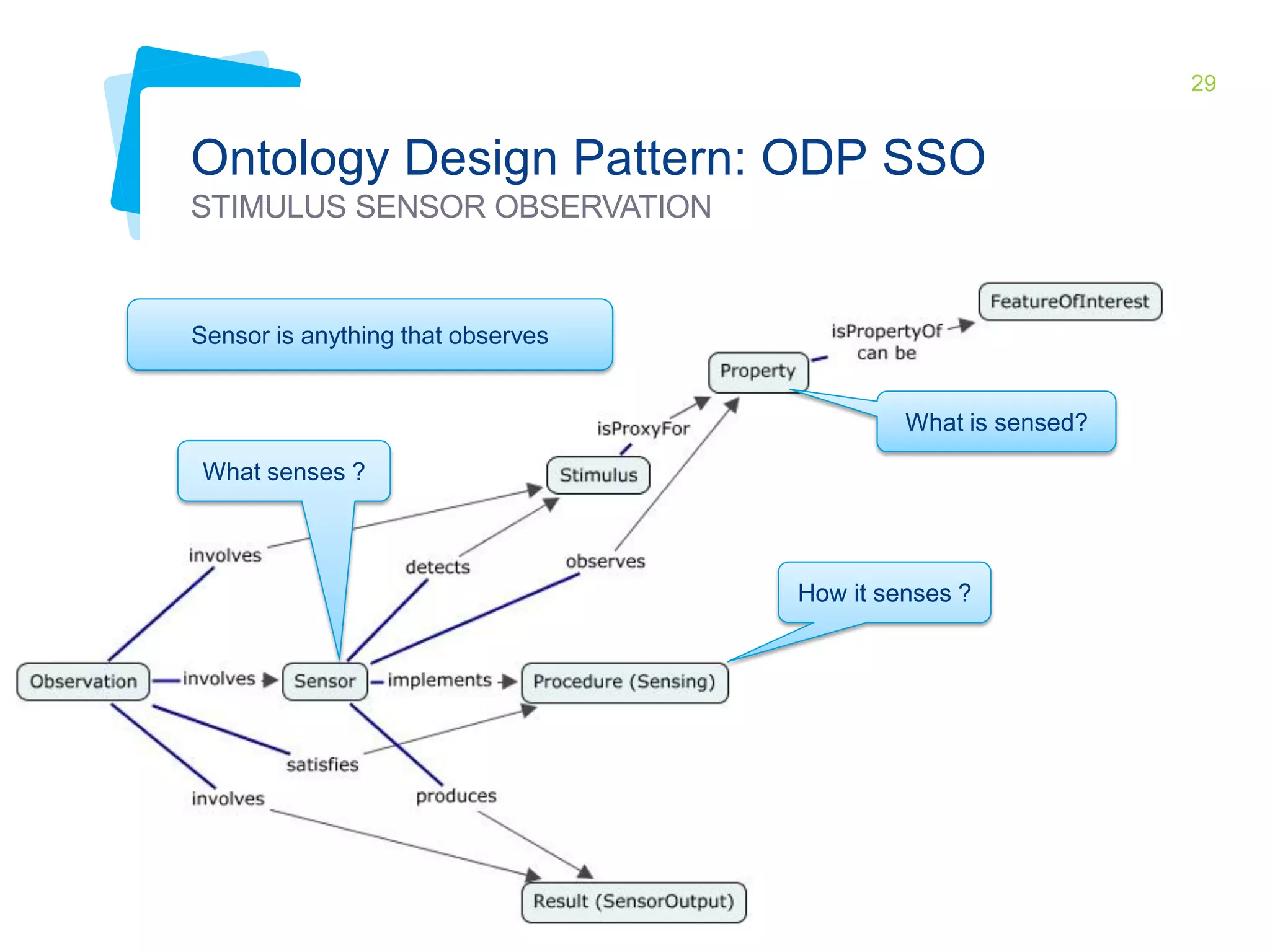
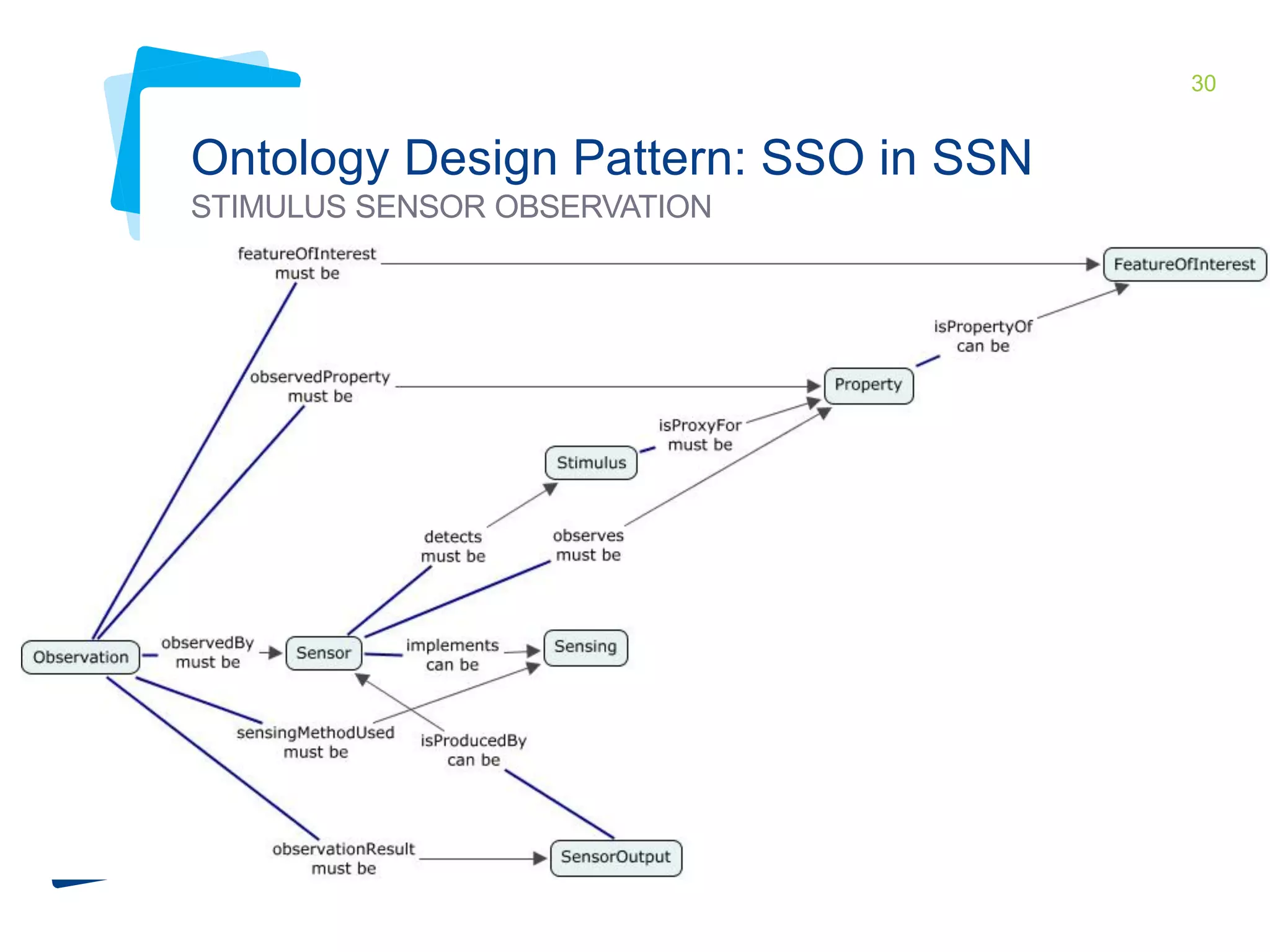
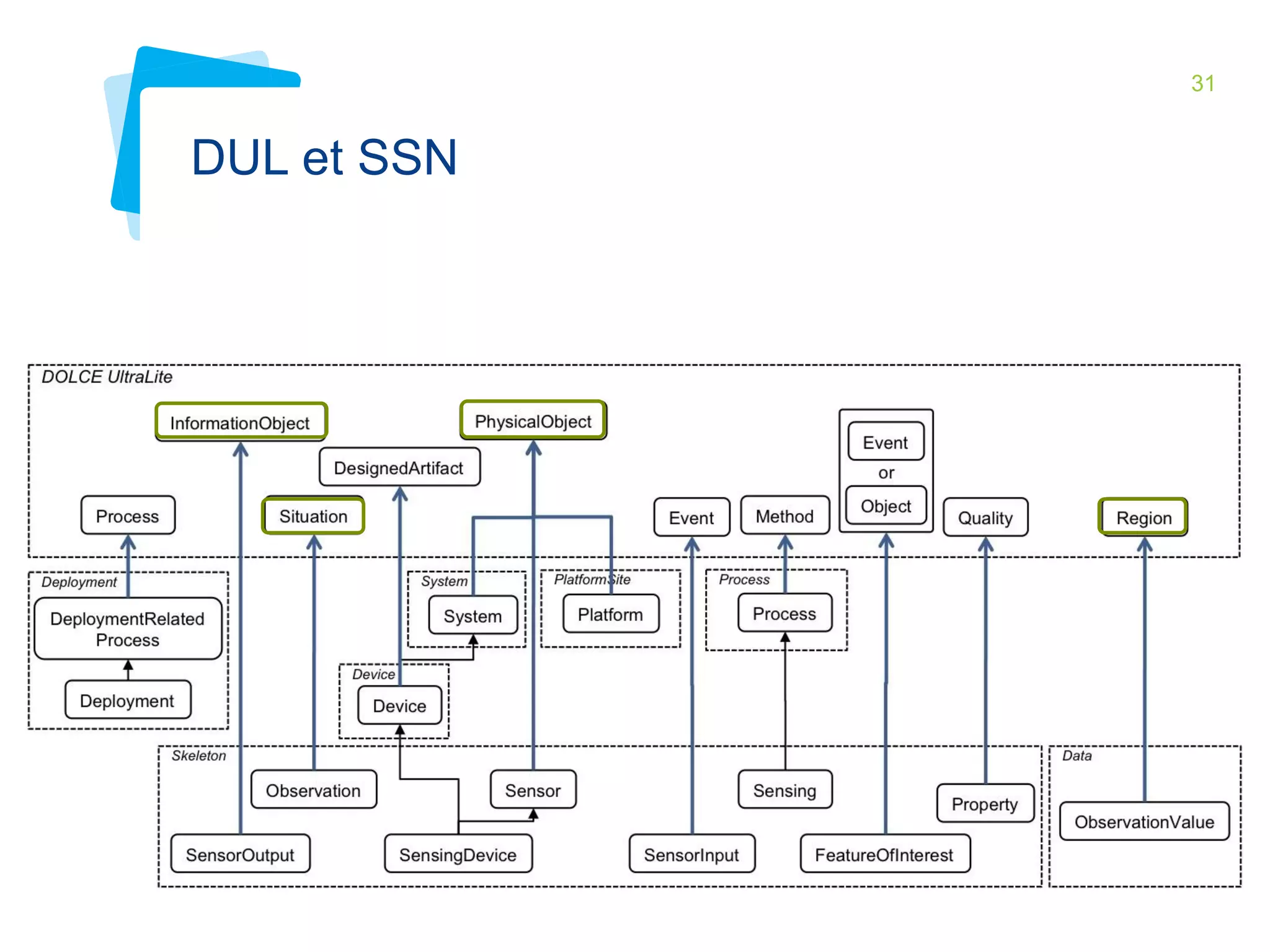
This document discusses Irstea's publication of weather station data as linked open data using semantic web standards. It provides an overview of open data and linked open data principles. It then describes Irstea's weather station in Montoldre, France, the sensors that collect data, and the observations made. It details how the data was modeled using the Semantic Sensor Network (SSN) ontology and other related ontologies. Finally, it discusses converting the data from CSV files to RDF and making it available via a SPARQL endpoint.