Download to read offline




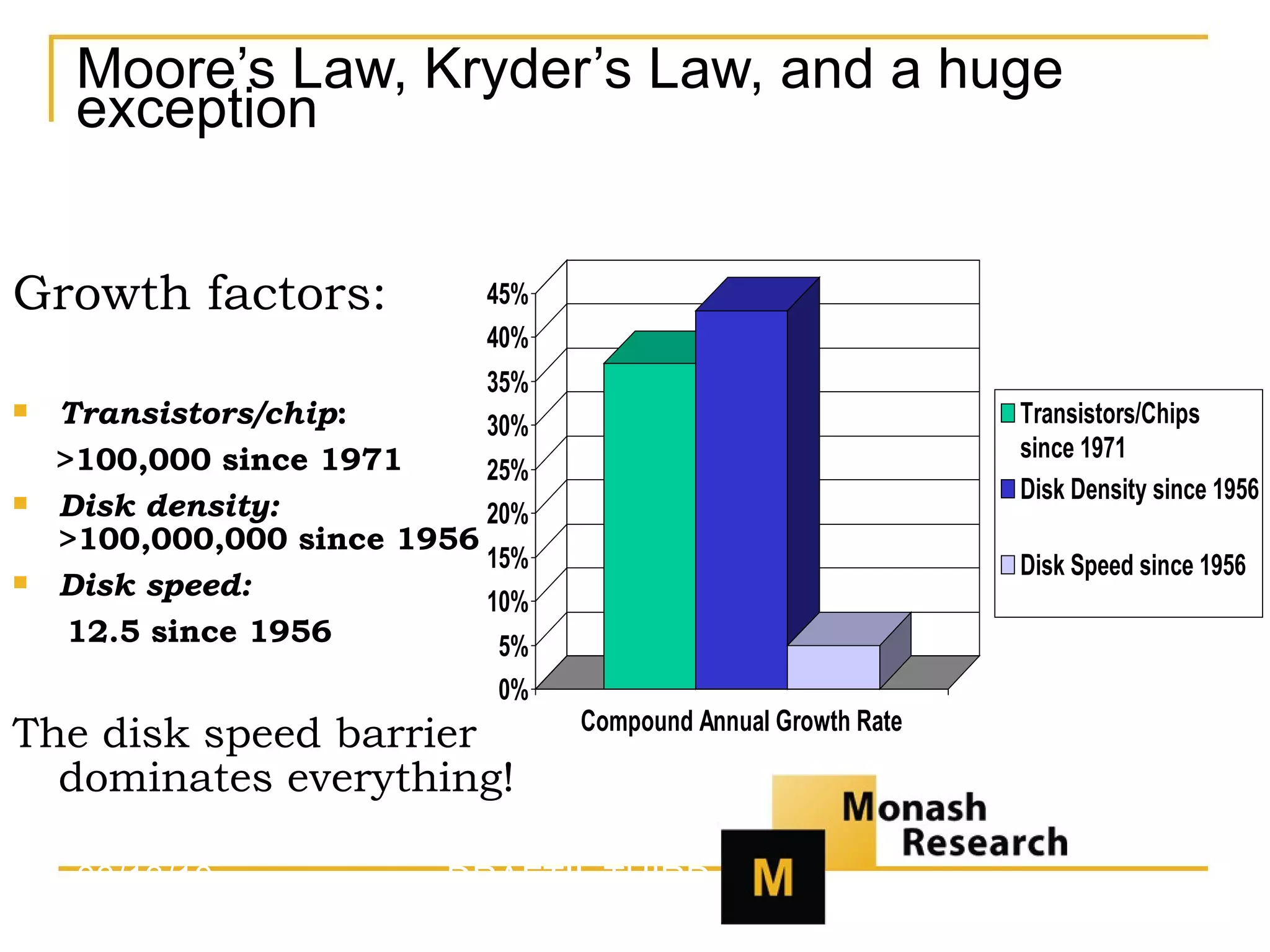



































There are specialized analytic database management systems (DBMS) because general-purpose DBMS are optimized for updating short rows rather than analytic query performance, which can see 10-100x price/performance differences. The disk speed barrier dominates everything due to the massive difference in access speeds between RAM, CPUs and disks. Major factors in selecting an analytic DBMS include query performance, update performance, compatibility requirements, analytics needs, manageability, and security features. The selection process involves defining use cases and requirements, creating a shortlist, conducting proof-of-concept evaluations, and selecting based on criteria like cost, speed, risk, and upside potential.























































![[DBA]_HiramFleitas_SQL_PASS_Summit_2017_Summary](https://cdn.slidesharecdn.com/ss_thumbnails/dbahiramfleitassqlpasssummit2017summary-180202201153-thumbnail.jpg?width=640&height=640&fit=bounds)


![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
















