Download to read offline



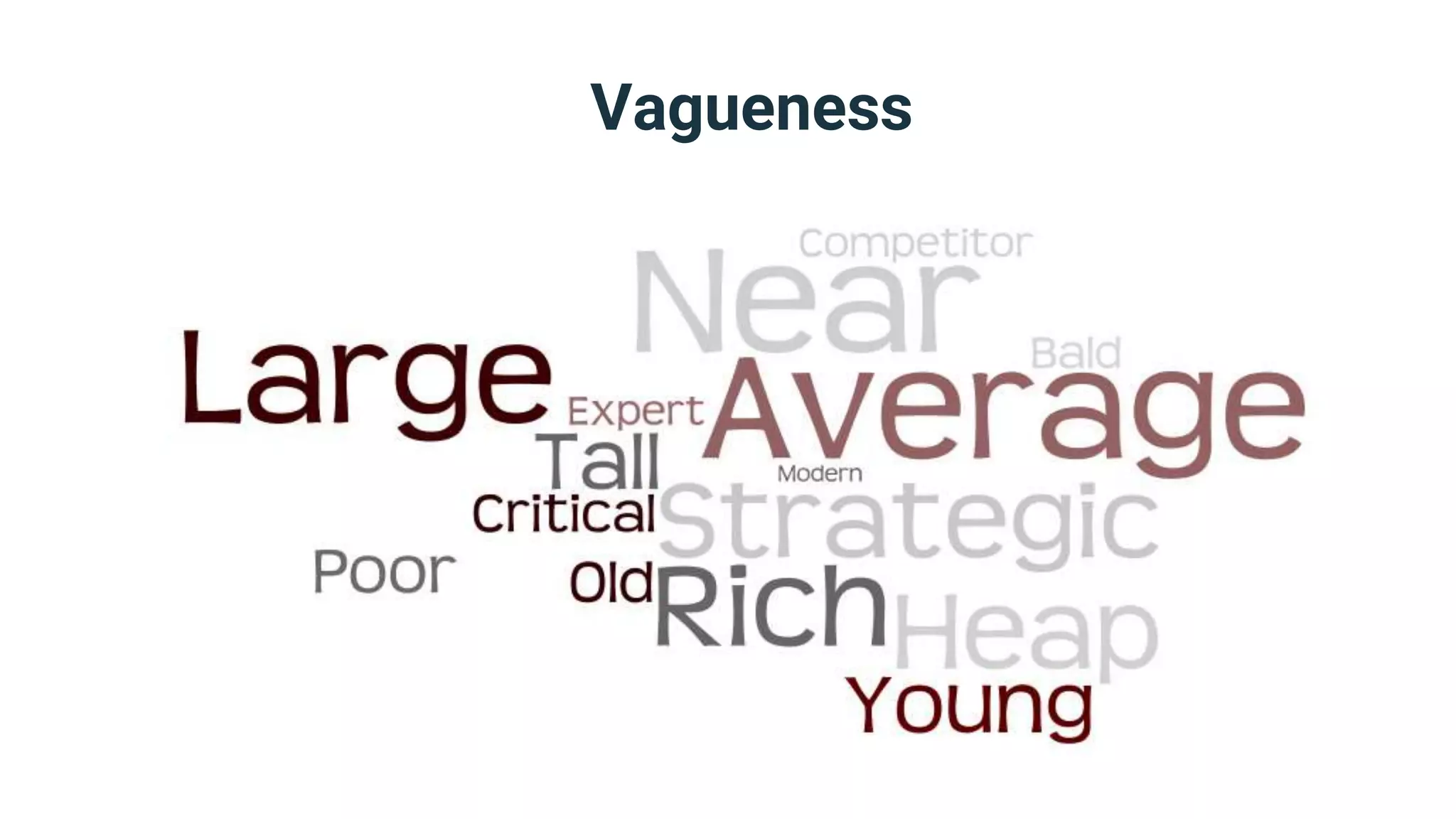


























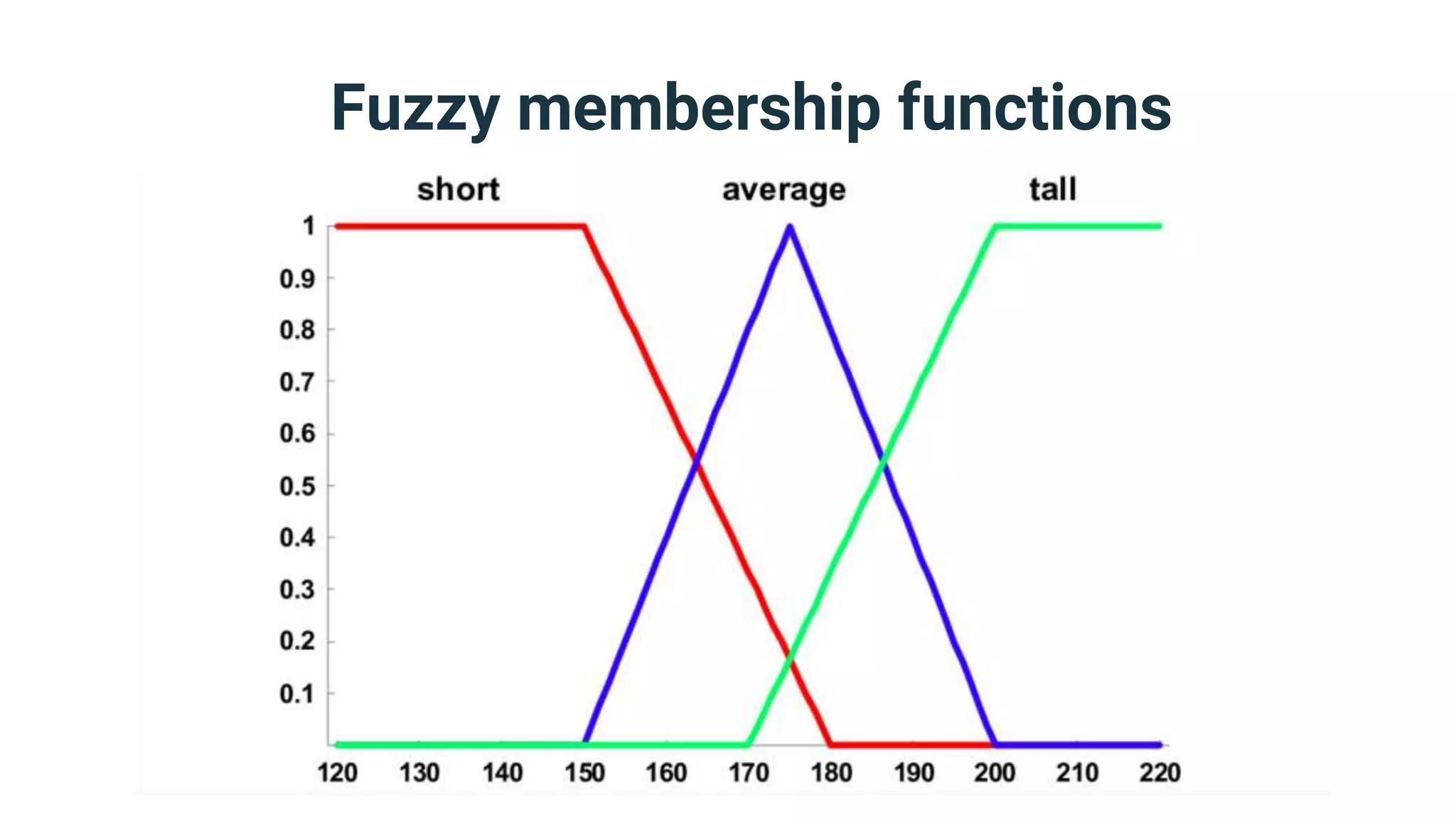
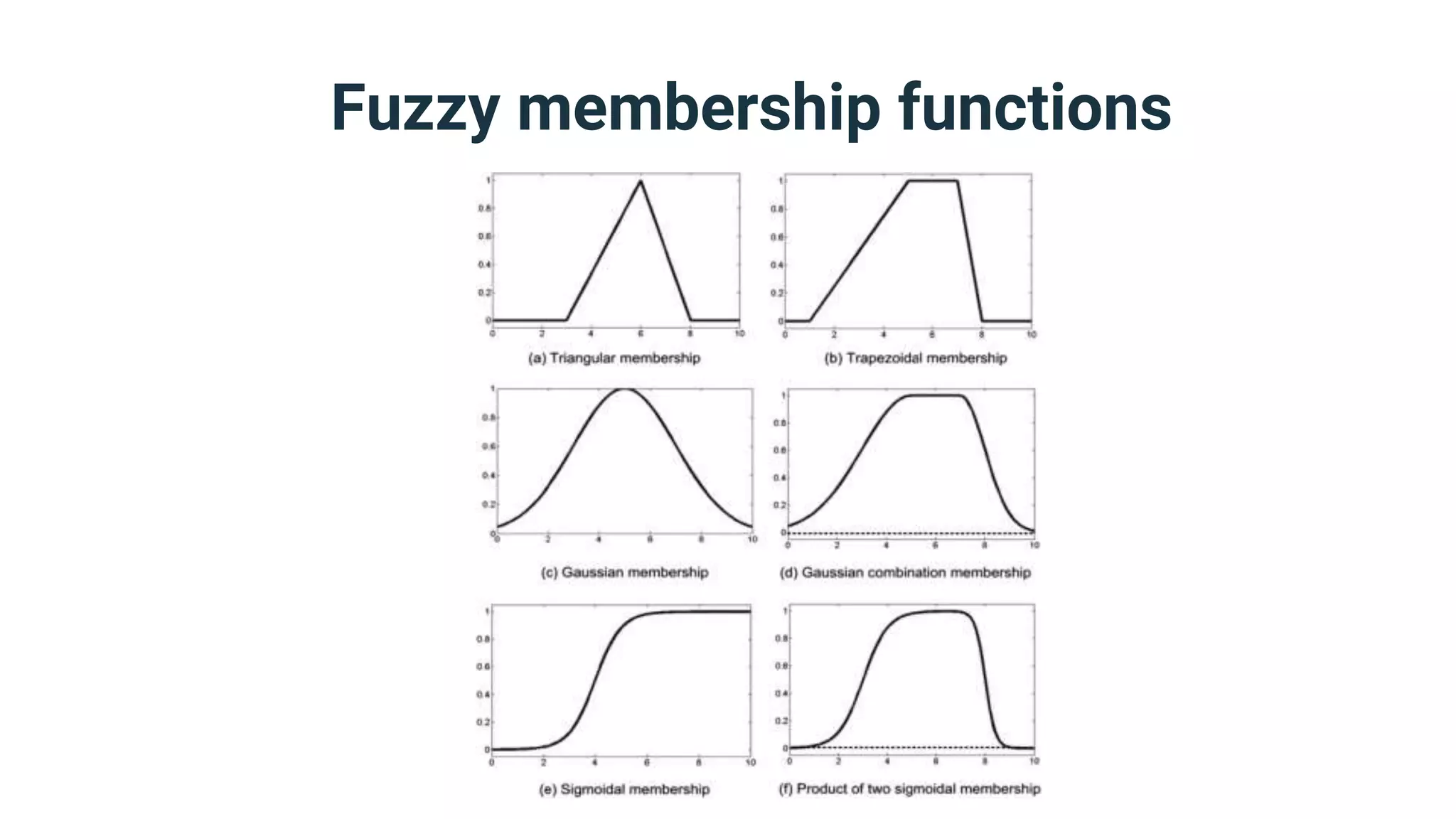
![Fuzzification options
● The number and kind of fuzzy degrees you
need to acquire for your model’s vague
elements depend on the latter’s vagueness
type and dimensions.
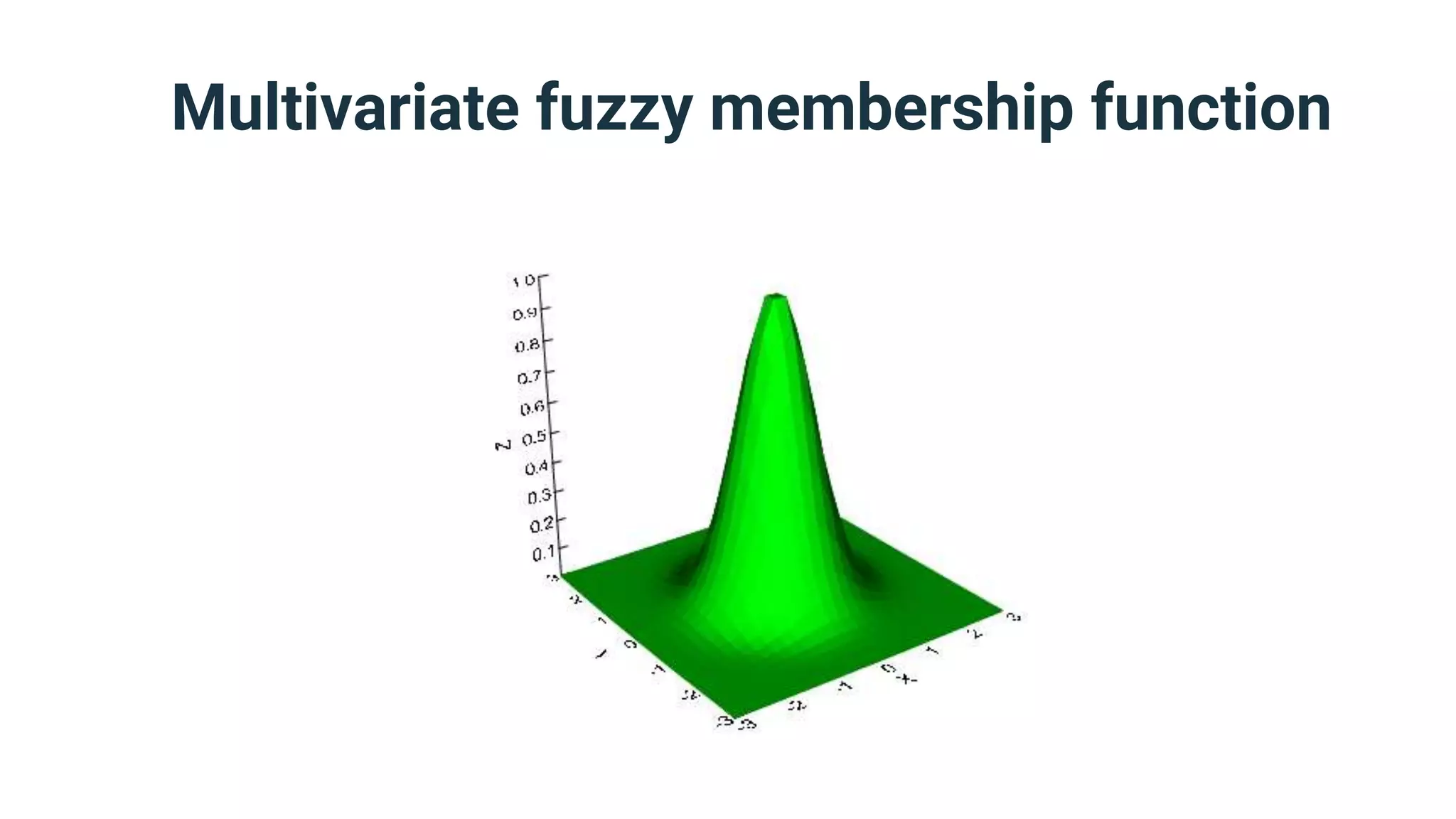
● If your element has quantitative vagueness
in one dimension, then all you need is a
fuzzy membership function that maps
numerical values of the dimension to fuzzy
degrees in the range [0,1]](https://image.slidesharecdn.com/dmzeurope2019handlingvagueness-191111083826/75/How-many-truths-can-you-handle-40-2048.jpg)




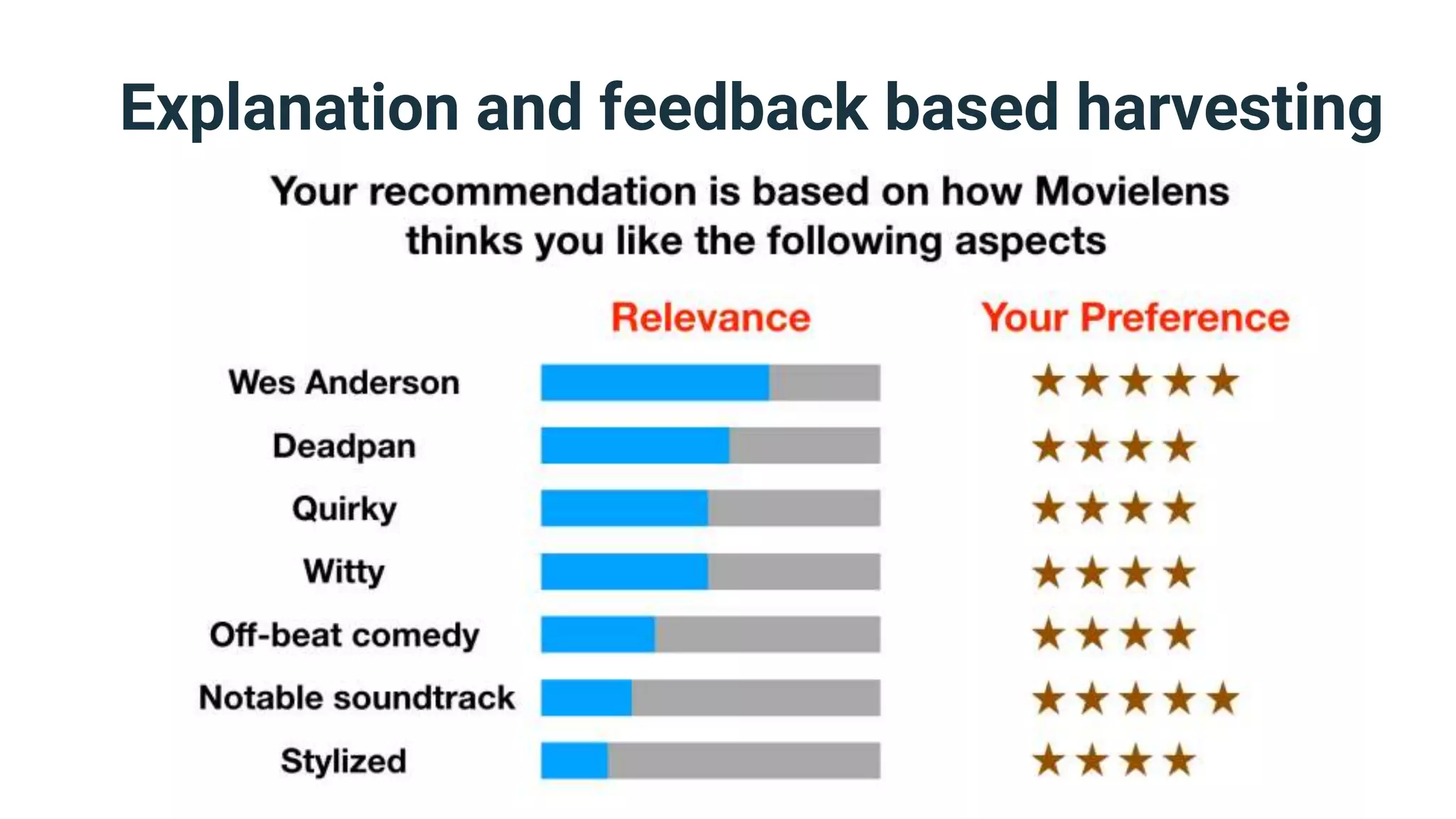


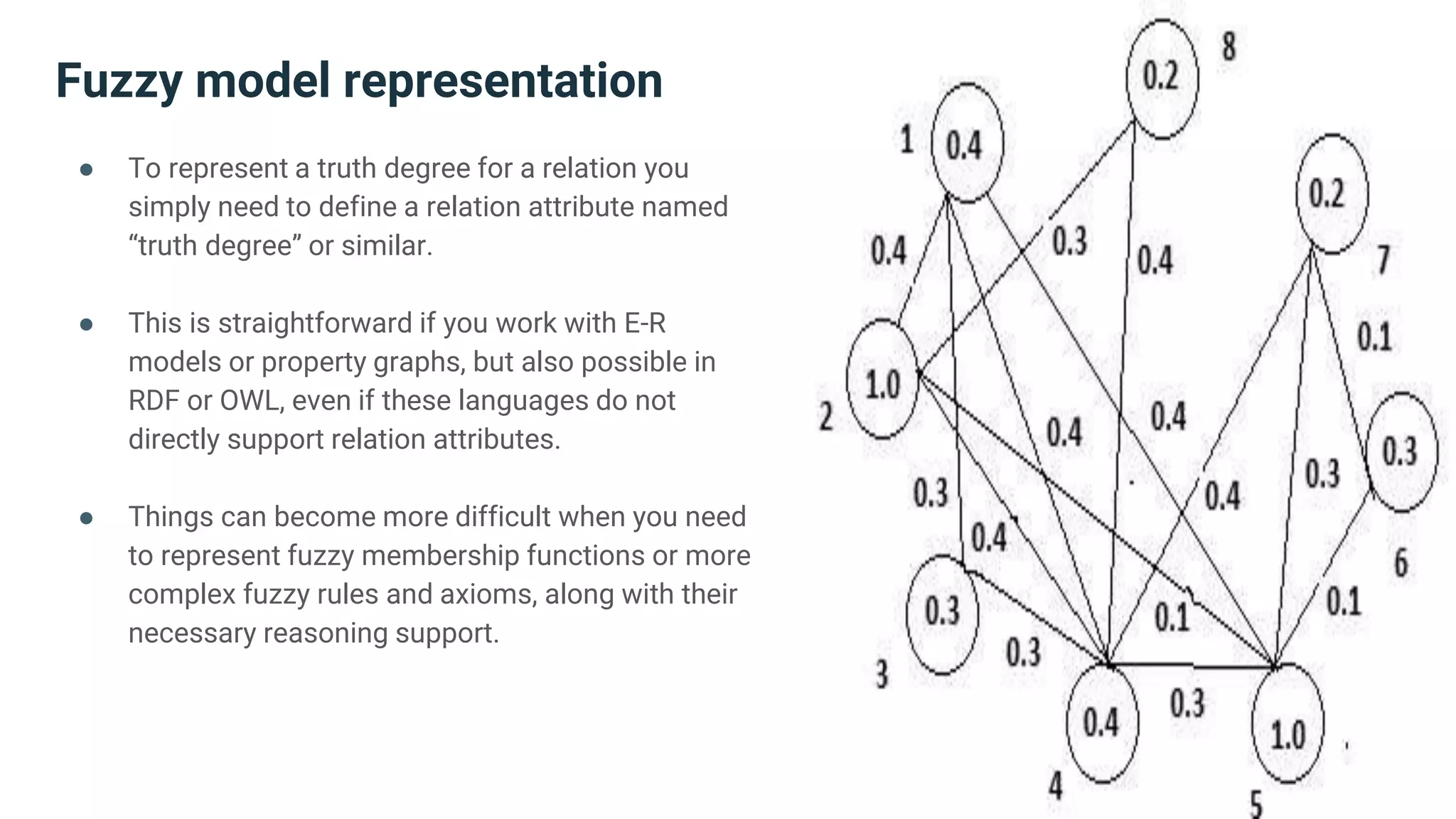


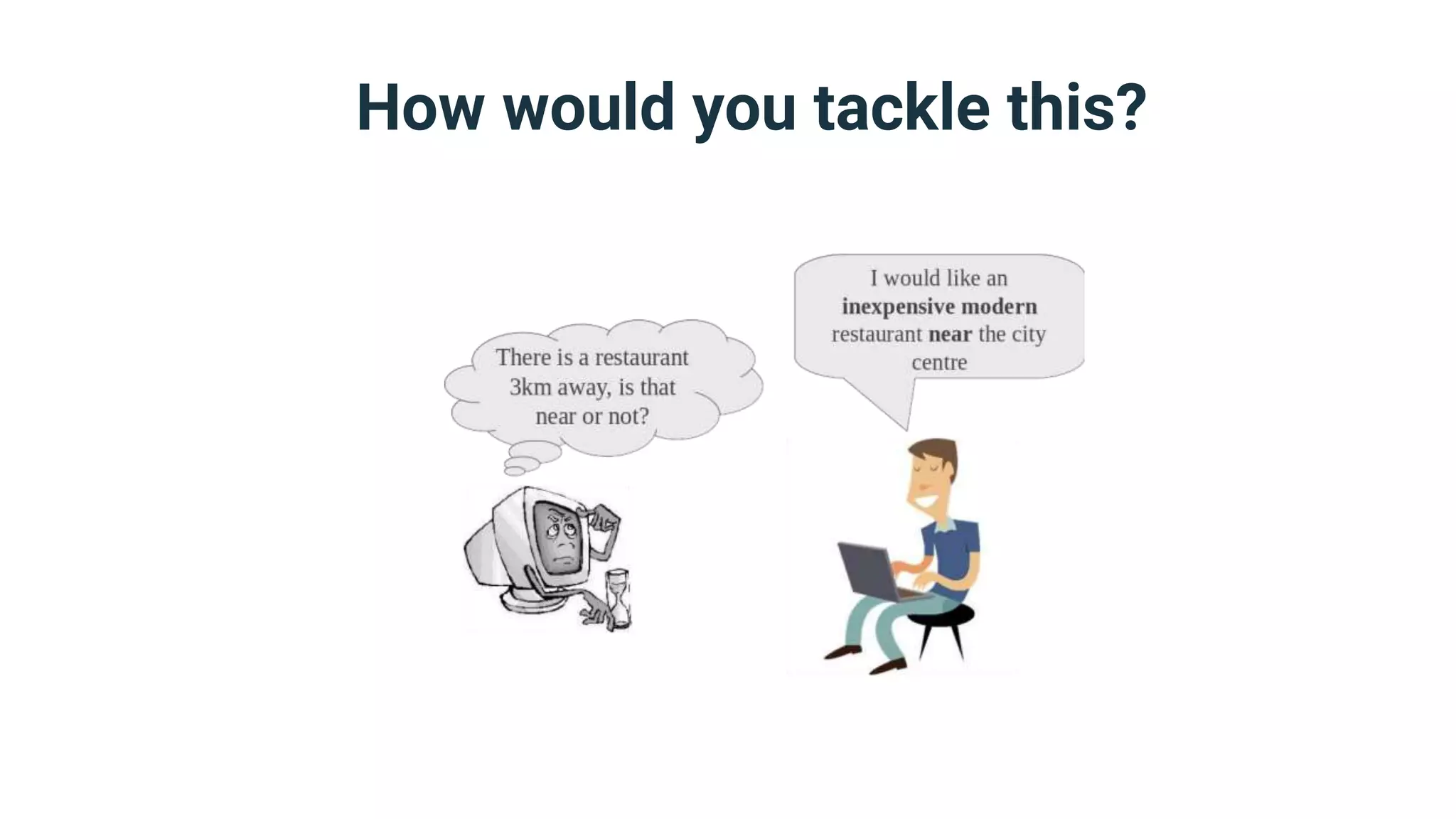
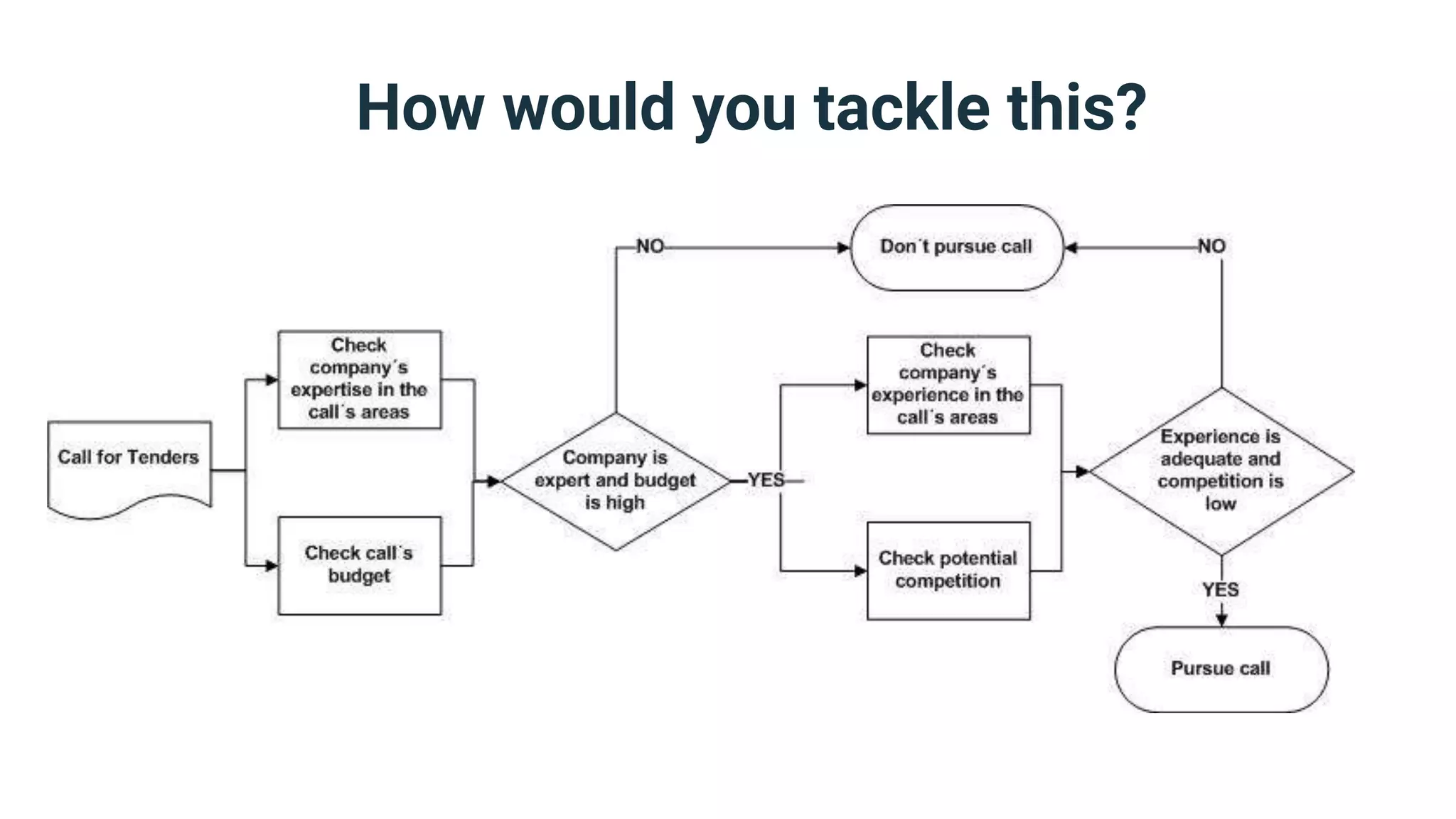

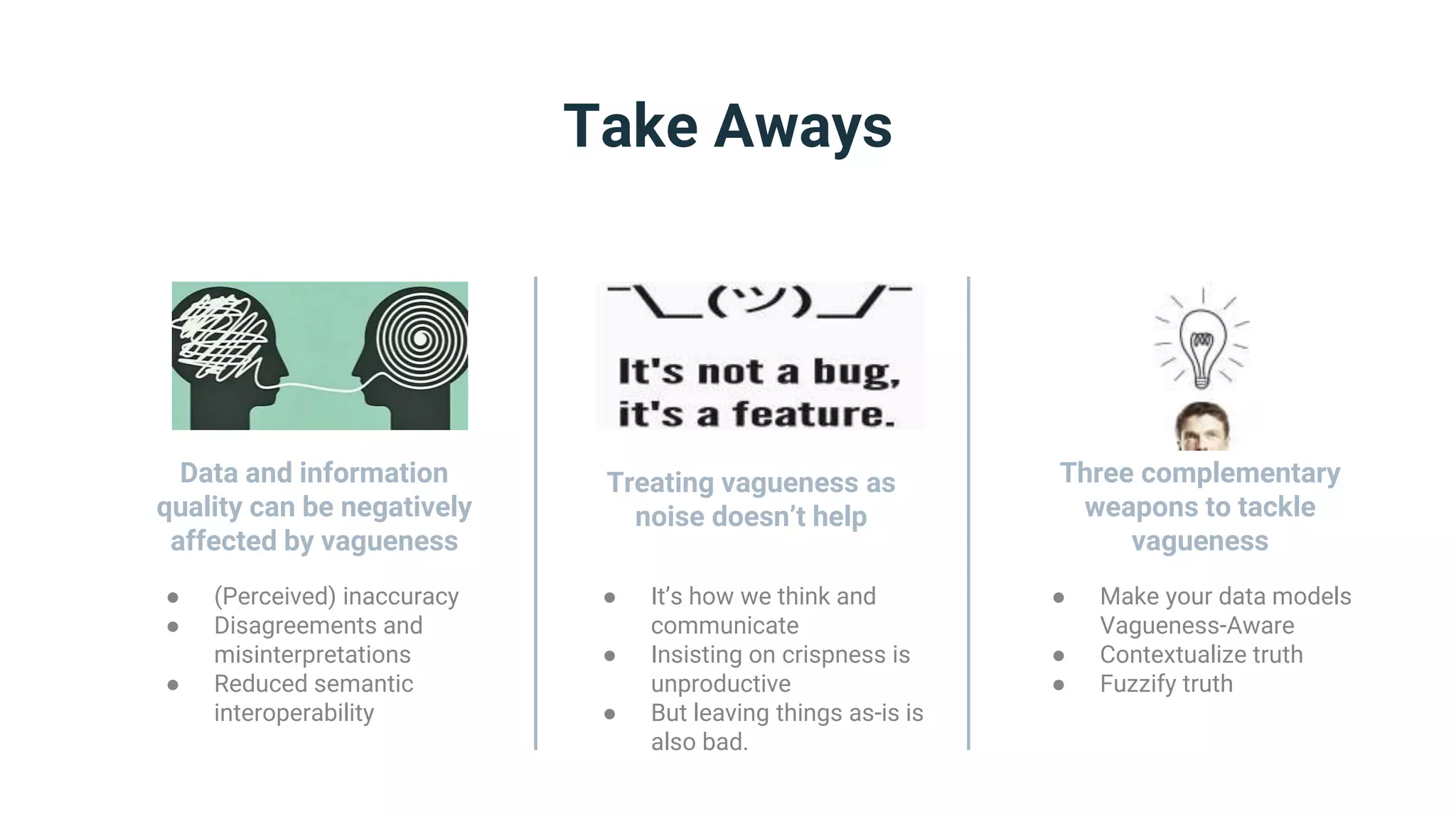




The document discusses strategies for handling vagueness in data models, emphasizing the importance of identifying, measuring, and addressing vague elements to improve communication and data quality. Key techniques include vagueness awareness, truth contextualization, and truth fuzzification, each aimed at minimizing misinterpretations and disagreements. The author advocates for a more nuanced approach to semantic modeling by recognizing the impact of vagueness on data integrity and providing methods to manage it effectively.



































































