Downloaded 18 times




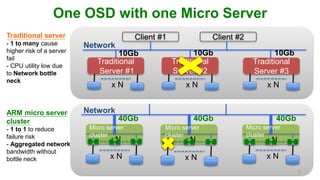



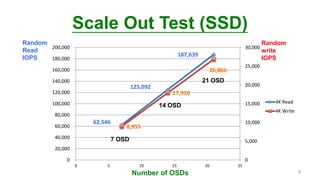
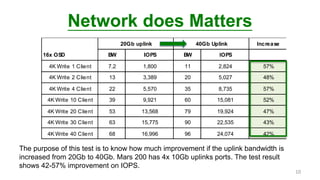
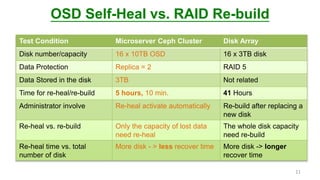
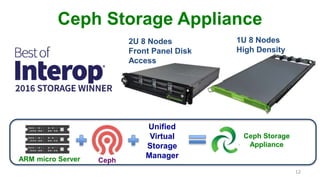





This document discusses how an ARM-based microserver cluster performs for Ceph storage. It outlines the issues with using a single server node with multiple Ceph OSDs, and describes how using a single micro server with one OSD reduces failure domains and bottlenecks. Test results show increased performance and lower power consumption compared to traditional servers. The document also introduces Ambedded's Ceph storage appliance and management software.



































































