



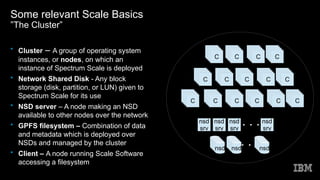
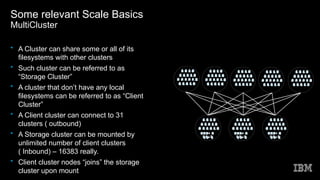

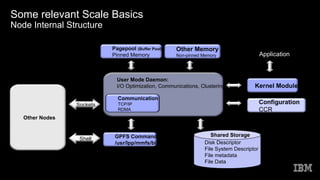







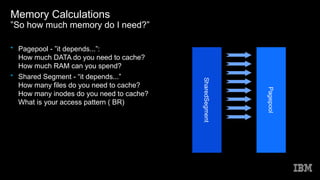
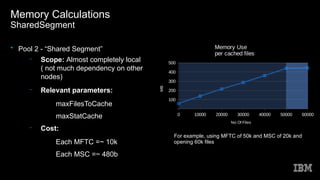


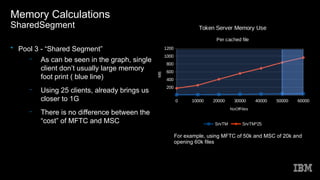







This document discusses Spectrum Scale memory usage. It outlines Spectrum Scale basics like clusters, nodes, and filesystems. It describes the different Spectrum Scale memory pools: pagepool for data, shared segment for metadata references, and external heap for daemons. It provides information on calculating memory needs based on parameters like files to cache, stat cache size, nodes, and access patterns. Other topics covered include related Linux memory usage and out of scope memory components.



































































