Download as PDF, PPTX









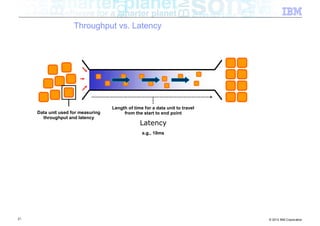





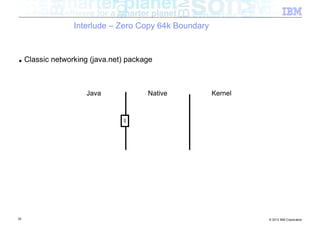
![Interlude – Zero Copy 64k Boundary
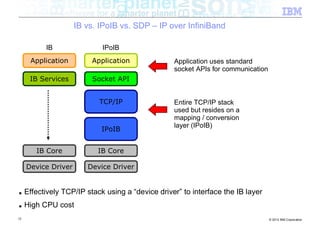
■ Classic networking (java.net) package
Java Native Kernel
byte[ ]
JNI
31 © 2012 IBM Corporation](https://image.slidesharecdn.com/highspeednetworksandjava-121018091237-phpapp01/85/High-speed-networks-and-Java-Ryan-Sciampacone-31-320.jpg)
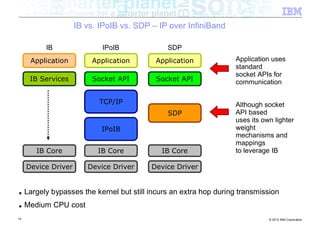
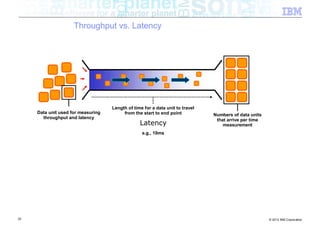
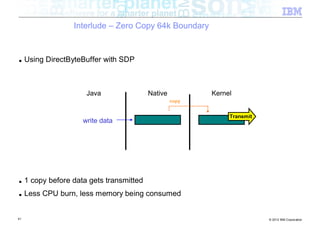
![Interlude – Zero Copy 64k Boundary
■ Classic networking (java.net) package
Java Native Kernel
byte[ ]
JNI
write data
32 © 2012 IBM Corporation](https://image.slidesharecdn.com/highspeednetworksandjava-121018091237-phpapp01/85/High-speed-networks-and-Java-Ryan-Sciampacone-32-320.jpg)
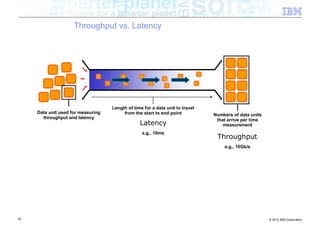
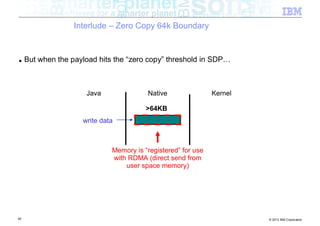
![Interlude – Zero Copy 64k Boundary
■ Classic networking (java.net) package
Java Native Kernel
byte[ ]
JNI
write data
33 © 2012 IBM Corporation](https://image.slidesharecdn.com/highspeednetworksandjava-121018091237-phpapp01/85/High-speed-networks-and-Java-Ryan-Sciampacone-33-320.jpg)
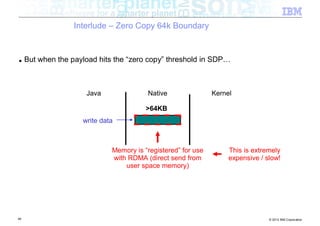
![Interlude – Zero Copy 64k Boundary
■ Classic networking (java.net) package
Java Native Kernel
copy
byte[ ]
JNI
write data
34 © 2012 IBM Corporation](https://image.slidesharecdn.com/highspeednetworksandjava-121018091237-phpapp01/85/High-speed-networks-and-Java-Ryan-Sciampacone-34-320.jpg)
![Interlude – Zero Copy 64k Boundary
■ Classic networking (java.net) package
Java Native Kernel
copy copy
byte[ ]
JNI
write data
35 © 2012 IBM Corporation](https://image.slidesharecdn.com/highspeednetworksandjava-121018091237-phpapp01/85/High-speed-networks-and-Java-Ryan-Sciampacone-35-320.jpg)
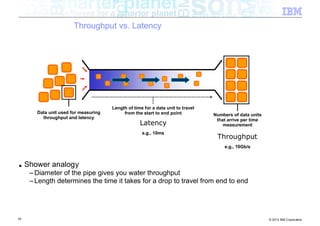
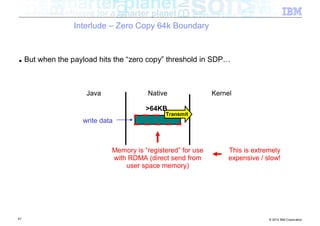
![Interlude – Zero Copy 64k Boundary
■ Classic networking (java.net) package
Java Native Kernel
copy copy
byte[ ]
Transmit
JNI
write data
■ 2 copies before data gets transmitted
■ Lots of CPU burn, lots of memory being consumed
36 © 2012 IBM Corporation](https://image.slidesharecdn.com/highspeednetworksandjava-121018091237-phpapp01/85/High-speed-networks-and-Java-Ryan-Sciampacone-36-320.jpg)










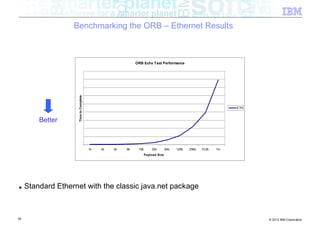
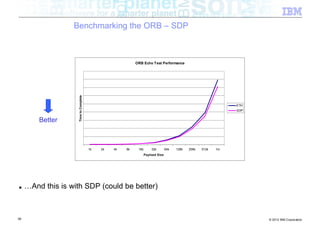
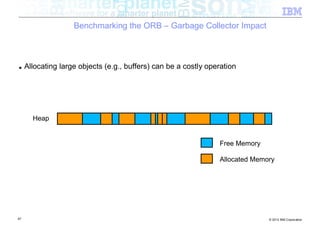
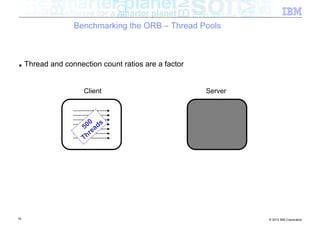
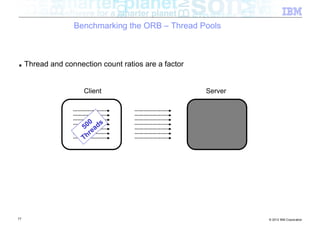
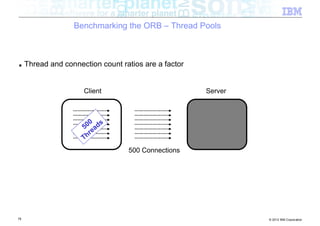
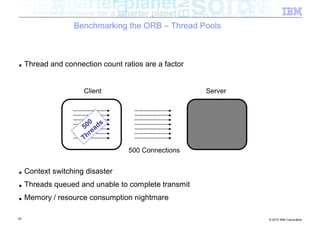
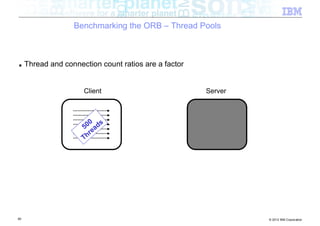
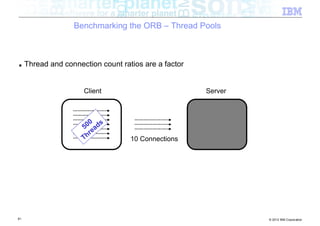
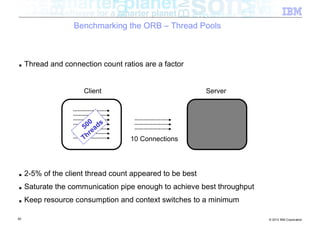
![Benchmarking the ORB – Background
■ Experiment: How does the ORB perform over InfiniBand?
■ Tests conducted
– Send different sized packets from a client to a server
– Time required for write followed by read
– Compare standard Ethernet to SDP / IPoIB
■ Conditions
– 500 client threads
– Echo style test (send to server, server echoes data back)
– byte[] payload
– 40Gb/s InfiniBand
■ Goal being to look at
– ORB performance when data pipe isn’t the bottleneck (Time to complete benchmark)
– Threading performance
■ Realistically expecting to discover bottlenecks in the ORB
54 © 2012 IBM Corporation](https://image.slidesharecdn.com/highspeednetworksandjava-121018091237-phpapp01/85/High-speed-networks-and-Java-Ryan-Sciampacone-54-320.jpg)
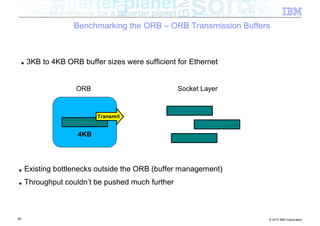
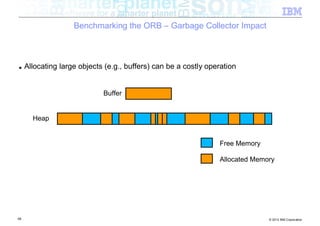
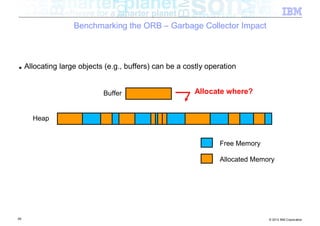
![Benchmarking the ORB – ORB Transmission Buffers
byte[ ]
57 © 2012 IBM Corporation](https://image.slidesharecdn.com/highspeednetworksandjava-121018091237-phpapp01/85/High-speed-networks-and-Java-Ryan-Sciampacone-57-320.jpg)
![Benchmarking the ORB – ORB Transmission Buffers
ORB
byte[ ]
58 © 2012 IBM Corporation](https://image.slidesharecdn.com/highspeednetworksandjava-121018091237-phpapp01/85/High-speed-networks-and-Java-Ryan-Sciampacone-58-320.jpg)
![Benchmarking the ORB – ORB Transmission Buffers
ORB
byte[ ]
write data
59 © 2012 IBM Corporation](https://image.slidesharecdn.com/highspeednetworksandjava-121018091237-phpapp01/85/High-speed-networks-and-Java-Ryan-Sciampacone-59-320.jpg)
![Benchmarking the ORB – ORB Transmission Buffers
ORB
byte[ ]
write data
Internal buffer
for transmission
60 © 2012 IBM Corporation](https://image.slidesharecdn.com/highspeednetworksandjava-121018091237-phpapp01/85/High-speed-networks-and-Java-Ryan-Sciampacone-60-320.jpg)
![Benchmarking the ORB – ORB Transmission Buffers
ORB
byte[ ]
write data
2KB 1KB
61 © 2012 IBM Corporation](https://image.slidesharecdn.com/highspeednetworksandjava-121018091237-phpapp01/85/High-speed-networks-and-Java-Ryan-Sciampacone-61-320.jpg)
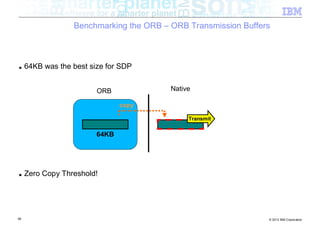
![Benchmarking the ORB – ORB Transmission Buffers
ORB
byte[ ]
write data
1KB
1KB 1KB
62 © 2012 IBM Corporation](https://image.slidesharecdn.com/highspeednetworksandjava-121018091237-phpapp01/85/High-speed-networks-and-Java-Ryan-Sciampacone-62-320.jpg)
![Benchmarking the ORB – ORB Transmission Buffers
ORB
copy
byte[ ]
write data
1KB
1KB 1KB
63 © 2012 IBM Corporation](https://image.slidesharecdn.com/highspeednetworksandjava-121018091237-phpapp01/85/High-speed-networks-and-Java-Ryan-Sciampacone-63-320.jpg)
![Benchmarking the ORB – ORB Transmission Buffers
ORB
copy
byte[ ]
Transmit
write data
1KB
1KB 1KB
■ Many additional costs being incurred (per thread!) to transmit a byte array
64 © 2012 IBM Corporation](https://image.slidesharecdn.com/highspeednetworksandjava-121018091237-phpapp01/85/High-speed-networks-and-Java-Ryan-Sciampacone-64-320.jpg)

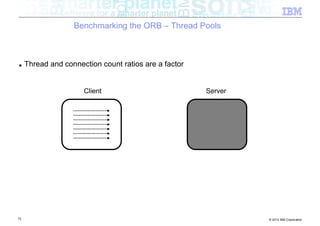
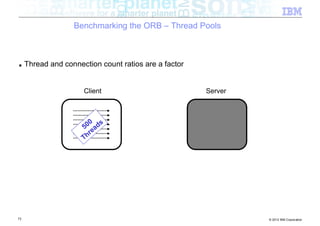
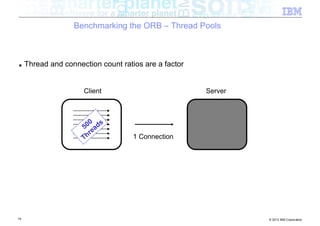
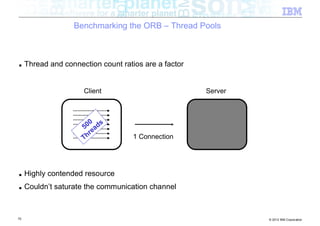
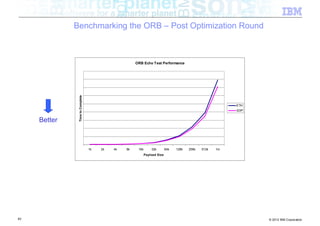
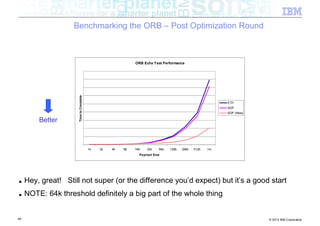
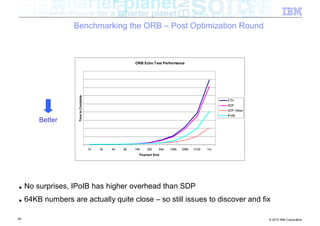







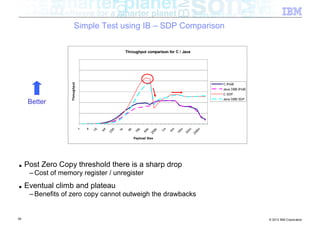
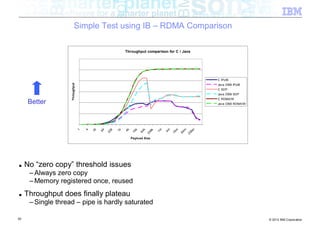
The document discusses high-speed networks and their performance implications for Java development. It summarizes the results of tests comparing the throughput of C and Java programs when sending data over different network types, including InfiniBand and its protocols. The tests found that for small payloads, the C programs generally had higher throughput than the Java programs. But as payload sizes increased above around 128KB, the throughput of the Java programs approached that of the C programs. The document also discusses challenges for Java in exploiting features like remote direct memory access over high-speed networks.






















































































