Downloaded 17 times


















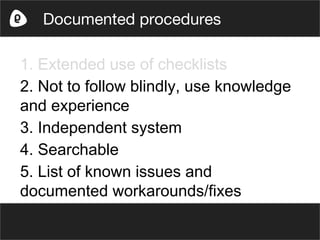












The document discusses the integration of human factors in DevOps through various methodologies such as monitoring, automation, and incident response. It emphasizes that system and human issues are interconnected, affecting downtime and overall business health. The importance of training, checklists, and iterative reviews to improve team responses during incidents is highlighted, along with principles of human operations.















































