Download as PDF, PPTX



![Information Consumption on Social
Media
• Updates of Friends and
Acquaintances
• News [1]
– 86% of Twitter
users surveyed
4
Introduction](https://image.slidesharecdn.com/pavan-defense-slideshare-160427152038/75/Personalized-and-Adaptive-Semantic-Information-Filtering-for-Social-Media-Pavan-Kapanipathi-s-Defense-4-2048.jpg)
![Information Consumption on Social
Media
• Updates of Friends and
Acquaintances
• News [1]
– 86% of Twitter
users surveyed
• Medical Information [2]
– 1 in 3 use social media
5
Introduction](https://image.slidesharecdn.com/pavan-defense-slideshare-160427152038/75/Personalized-and-Adaptive-Semantic-Information-Filtering-for-Social-Media-Pavan-Kapanipathi-s-Defense-5-2048.jpg)
![Information Consumption on Social
Media
• Updates of Friends and
Acquaintances
• News [1]
– 86% of Twitter
users surveyed
• Medical Information [2]
– 1 in 3 use social media
• Disaster Management [3]
– 20 million tweets on Hurricane Sandy
– Most crisis management agencies
monitor social media 6
Introduction](https://image.slidesharecdn.com/pavan-defense-slideshare-160427152038/75/Personalized-and-Adaptive-Semantic-Information-Filtering-for-Social-Media-Pavan-Kapanipathi-s-Defense-6-2048.jpg)
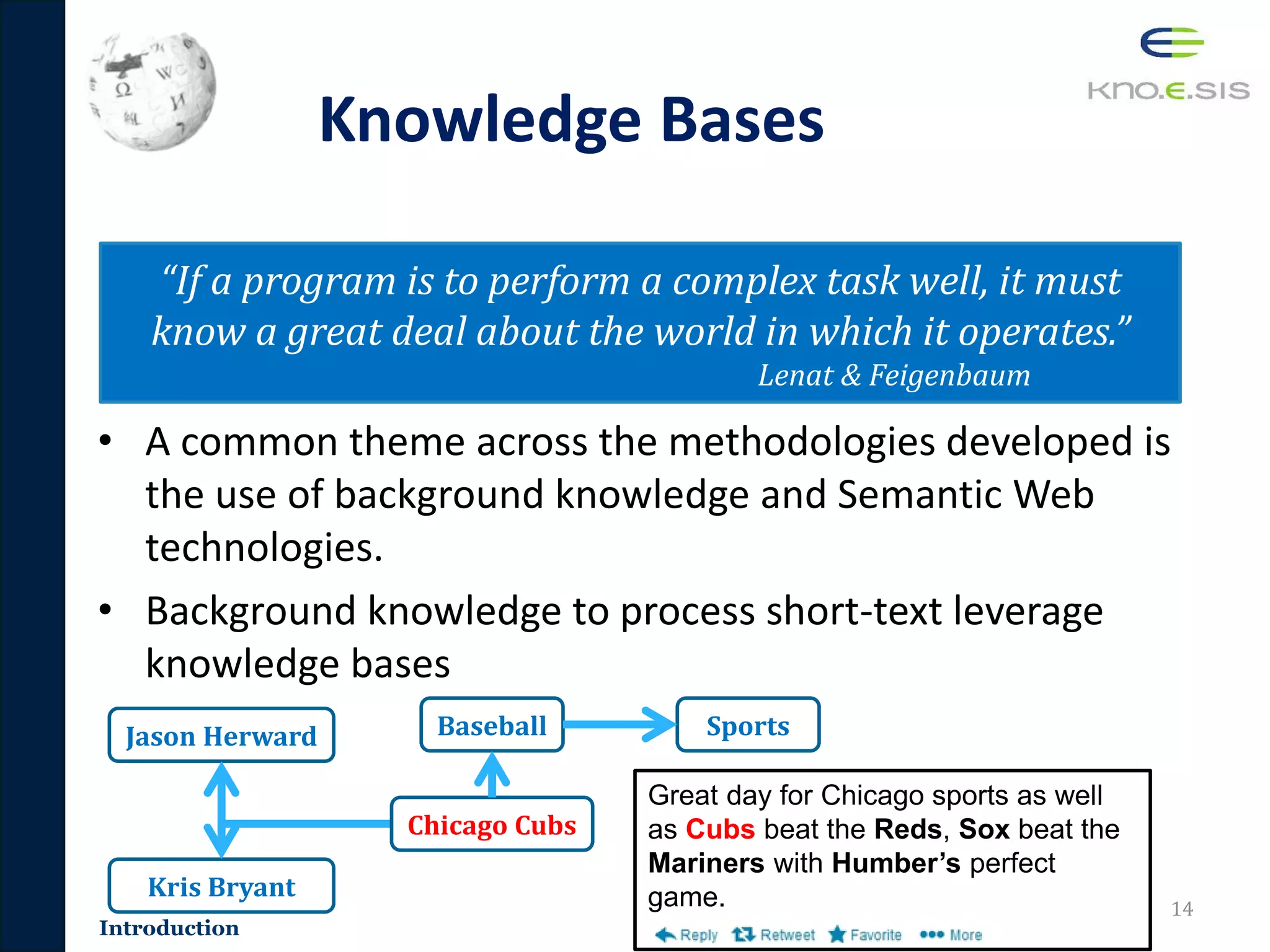
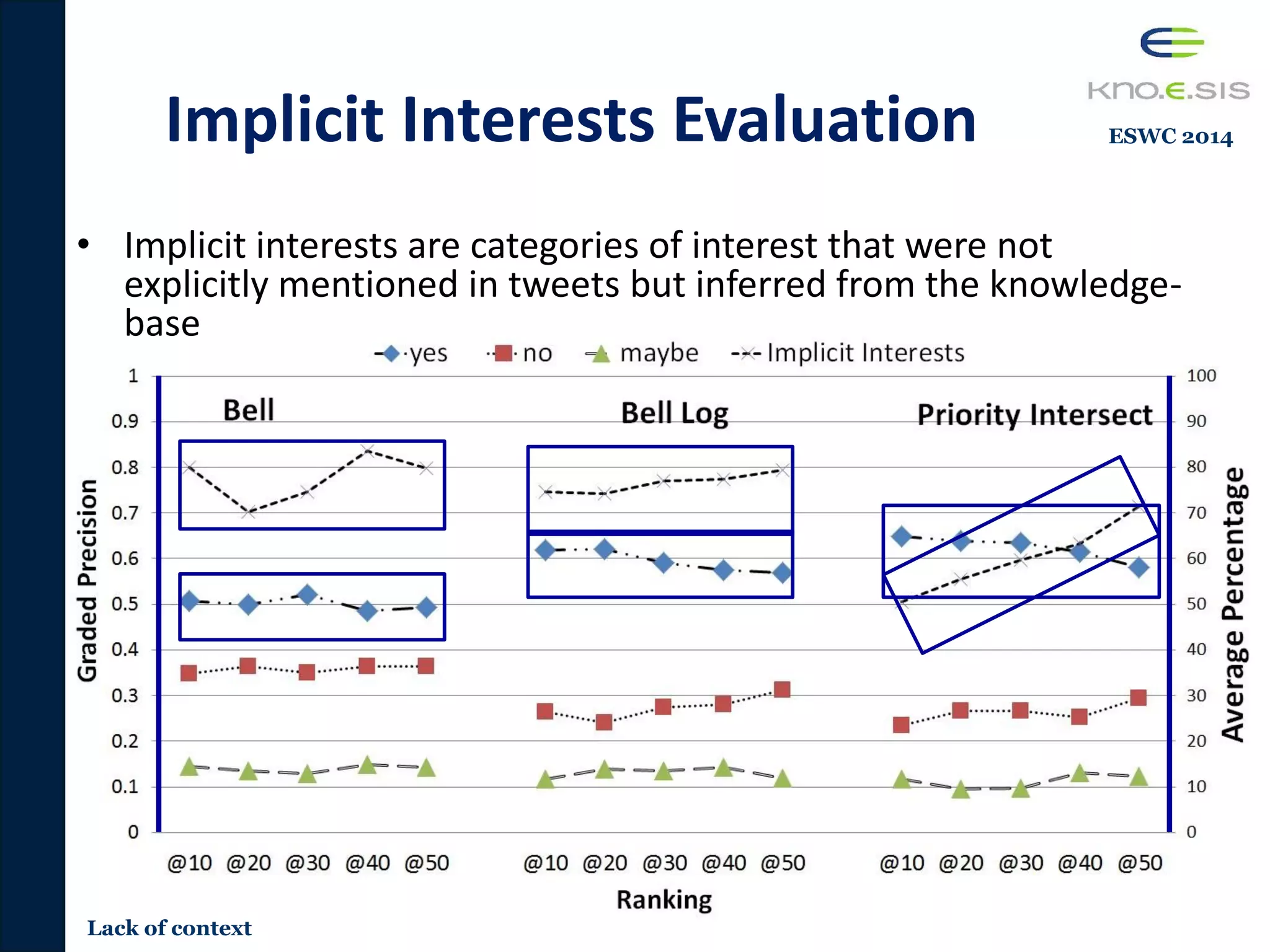
![Challenges
1. Lack of Context
• Lack of context for processing short-text
– Short-Text
• Average length of social media posts (Facebook, Twitter, Google+, etc.)
are 100-160 characters
• Identifying topics from short-text is important
– We can infer the author’s interest and deliver the tweet to interested
users in the topic
– Traditional techniques are shown to have not perform well on social
media [Sriram 2010, Derczynski 2013]
11
Great day for Chicago sports as well
as Cubs beat the Reds, Sox beat the
Mariners with Humber’s perfect game.](https://image.slidesharecdn.com/pavan-defense-slideshare-160427152038/75/Personalized-and-Adaptive-Semantic-Information-Filtering-for-Social-Media-Pavan-Kapanipathi-s-Defense-11-2048.jpg)


![Wikipedia as a Knowledge Base
• Requirements for a Knowledge base to be used for filtering
social data
– Diversity and Comprehensiveness: Large set of diverse users on social
media such as Twitter and Facebook
– Real-time updates: Social media is a real-time platform the discusses
dynamic topics
• Wikipedia as the Knowledge base
– Semi structured – Extract the structure
– Diverse: Collaborative effort of 80,000 users with 5 million articles
– Near real-time updates with unbiased views on topics [Ferron 2011]
15
Introduction](https://image.slidesharecdn.com/pavan-defense-slideshare-160427152038/75/Personalized-and-Adaptive-Semantic-Information-Filtering-for-Social-Media-Pavan-Kapanipathi-s-Defense-15-2048.jpg)

![Outline
• Short-Text: Lack of context for processing
– Hierarchical Interest Graphs
– Built a hierarchical context for tweets leveraging Wikipedia category
structure. This hierarchical context is utilized for user modeling and
recommendations.
– Publications [ESWC 2014, WWWCOMP 2014, TR-JRNL 2016]
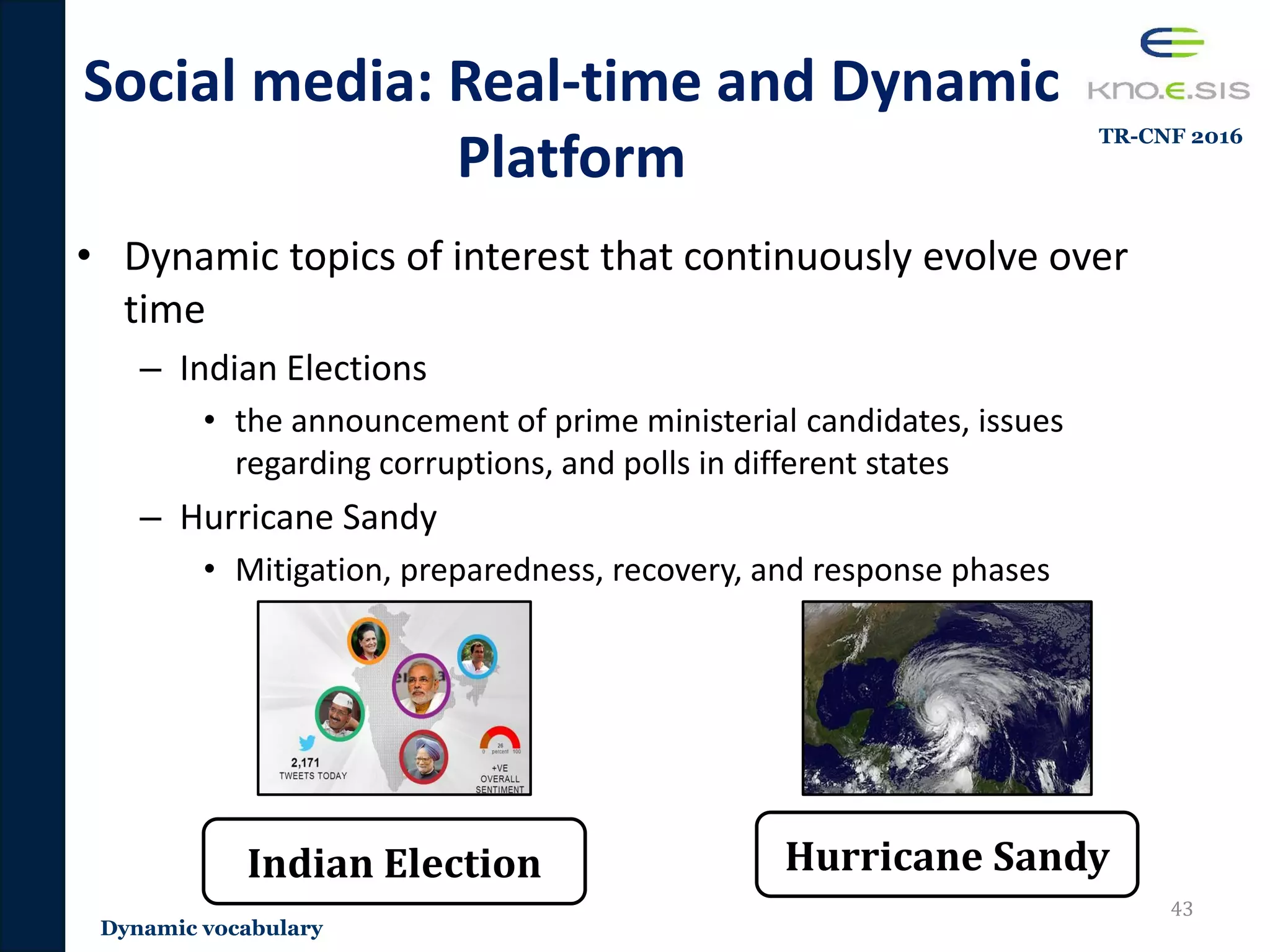
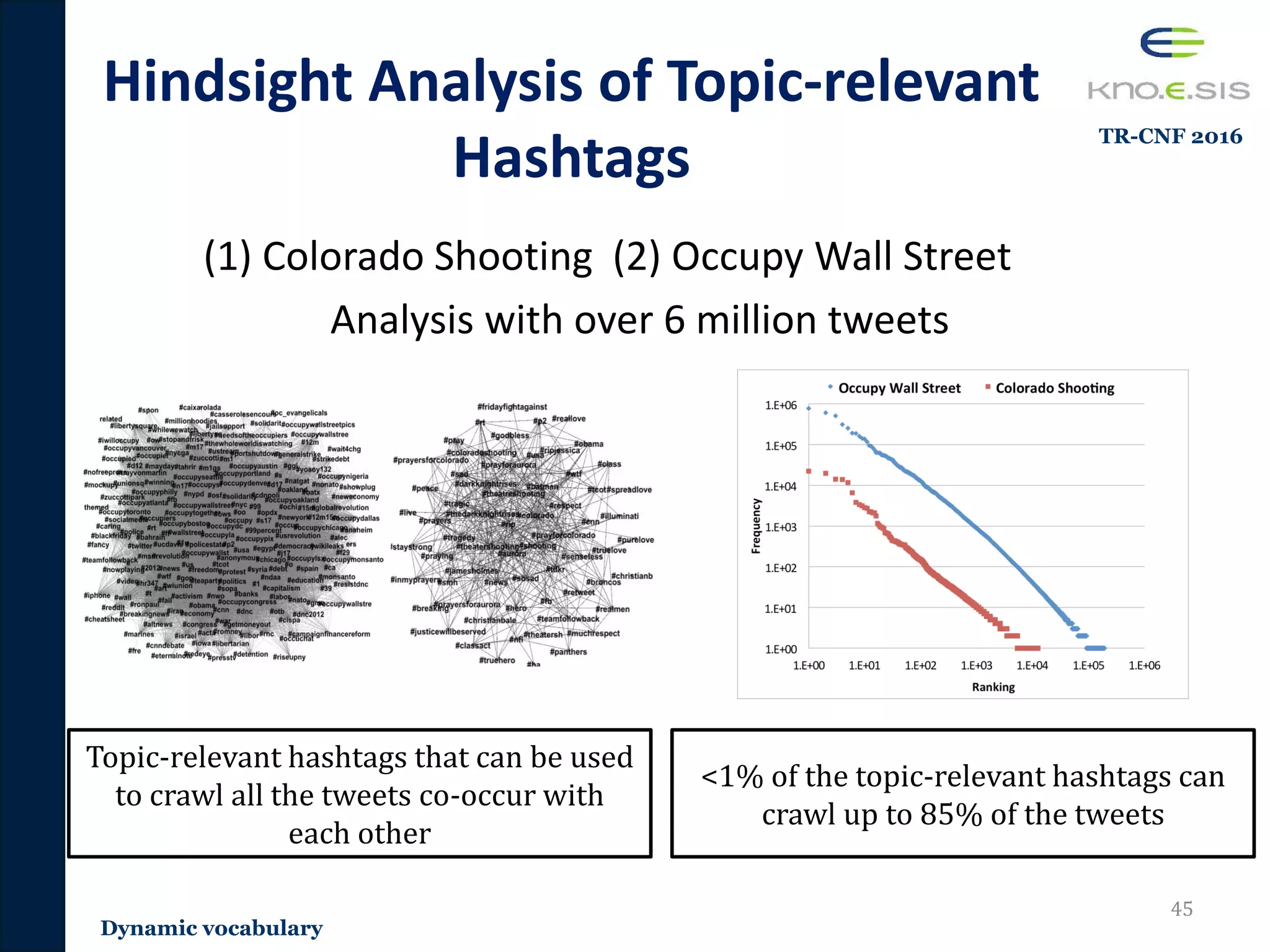
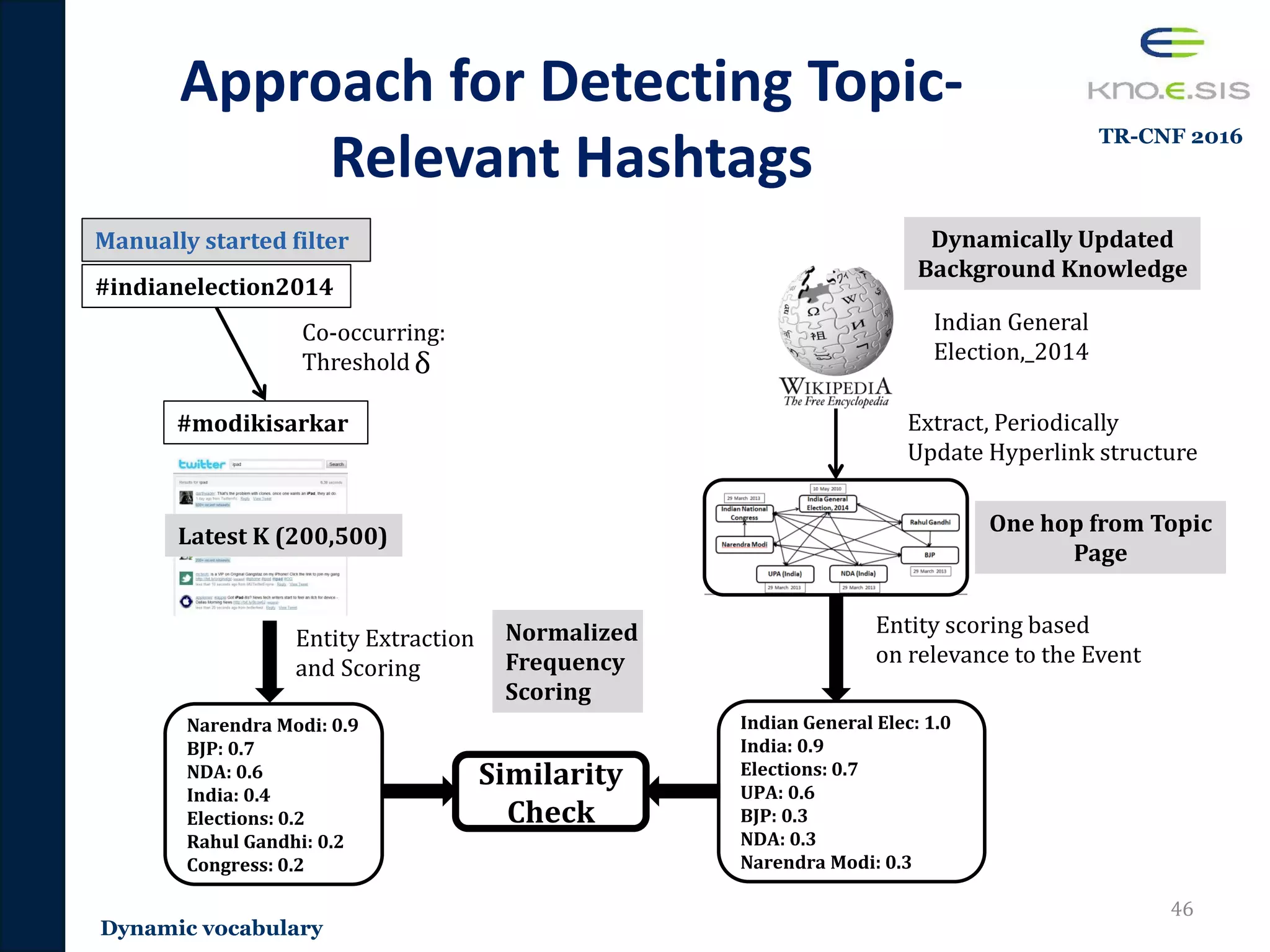
• Real-time and dynamic nature: Continuously changing
vocabulary
– A novel methodology that utilizes the evolving Wikipedia hyperlink
structure to detect topic-relevant hashtags for continuous filtering
– Publications [TR-CNF 2016, ESWC 2015]
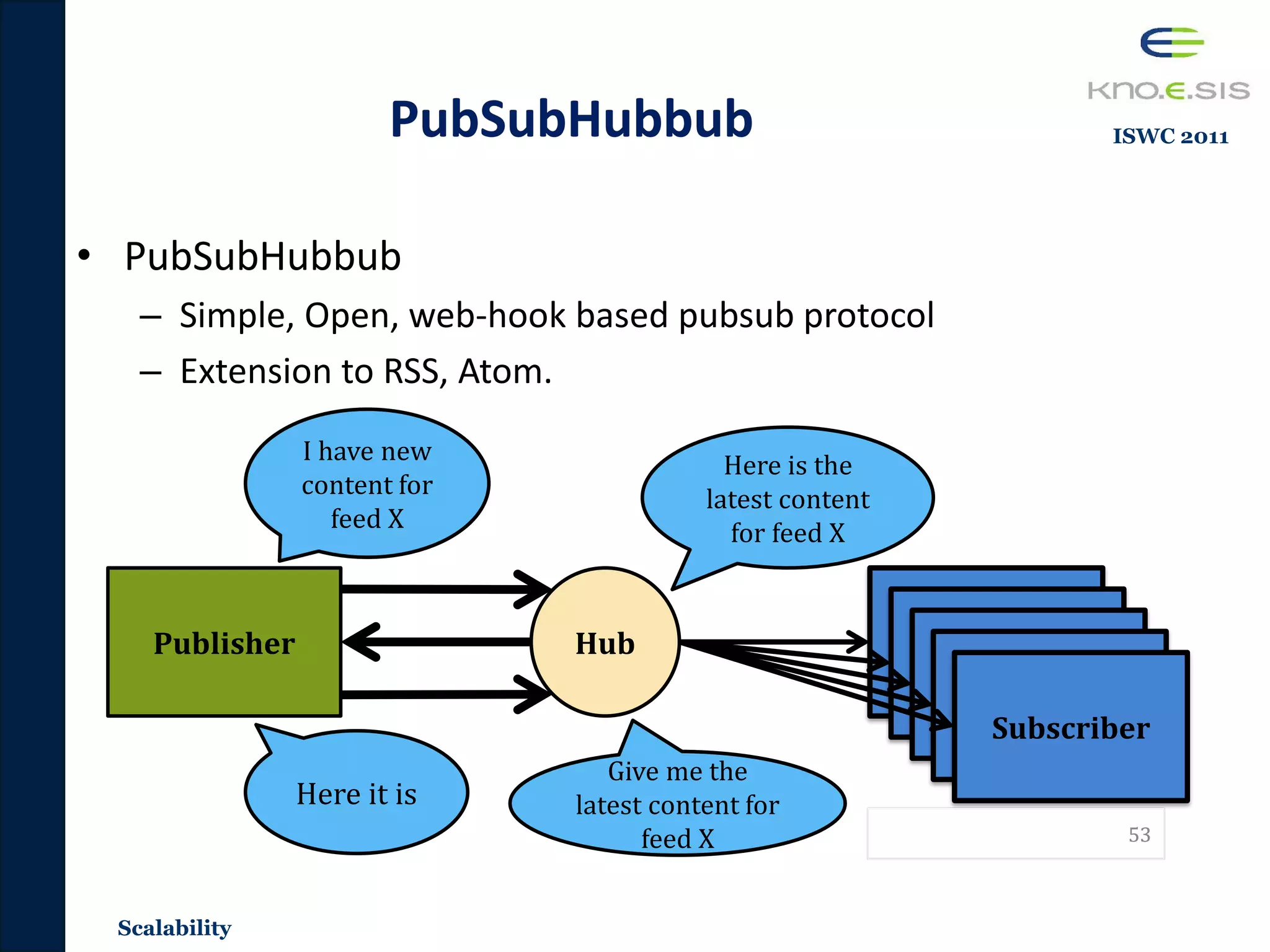
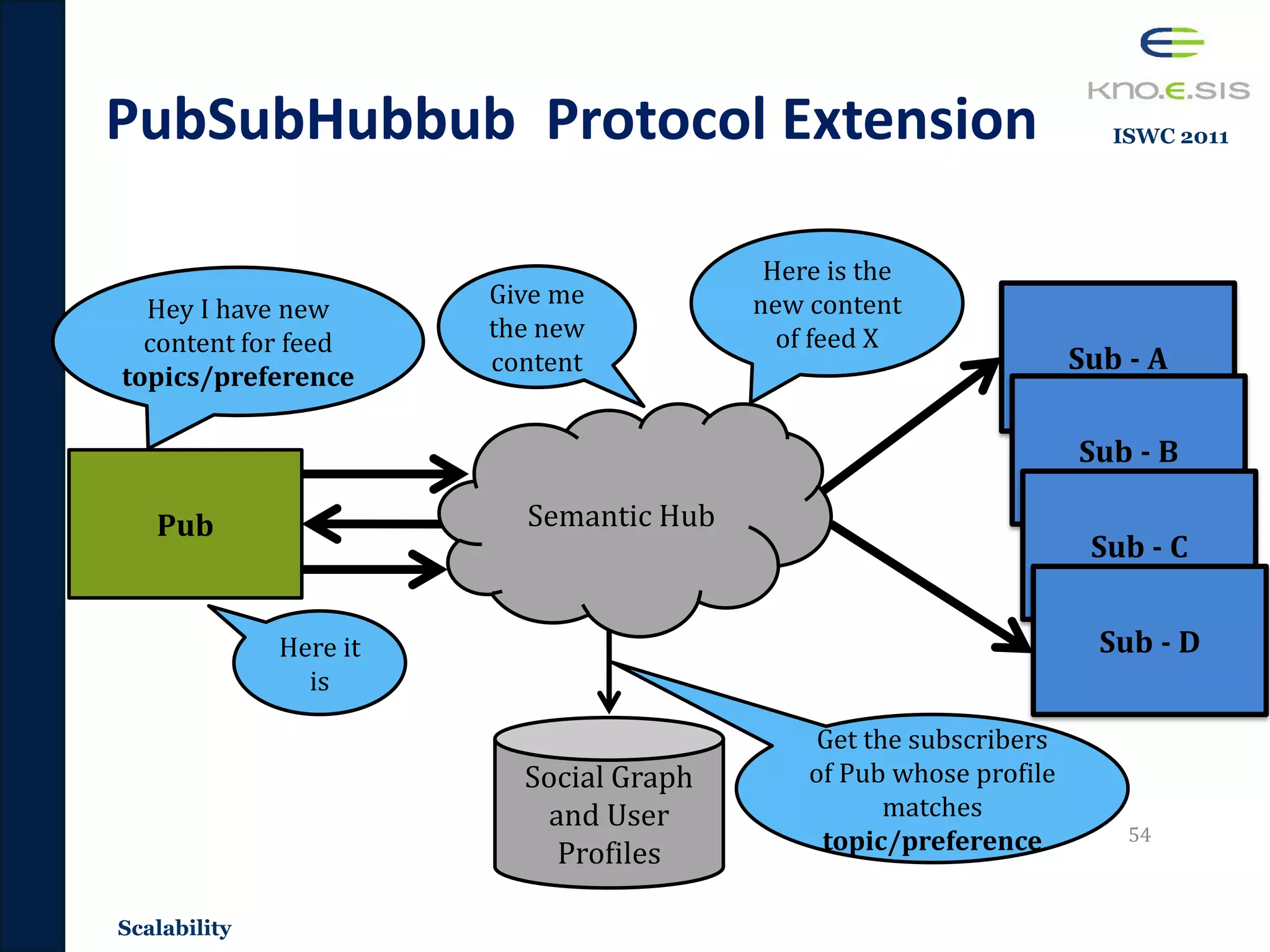
• Popularity: Scalability
– Scalable distributed dissemination system that utilizes Sematic Web
technologies.
– Publications [ISWC 2011, SPIM 2011, ISWCDEM 2011]
17
Introduction](https://image.slidesharecdn.com/pavan-defense-slideshare-160427152038/75/Personalized-and-Adaptive-Semantic-Information-Filtering-for-Social-Media-Pavan-Kapanipathi-s-Defense-17-2048.jpg)

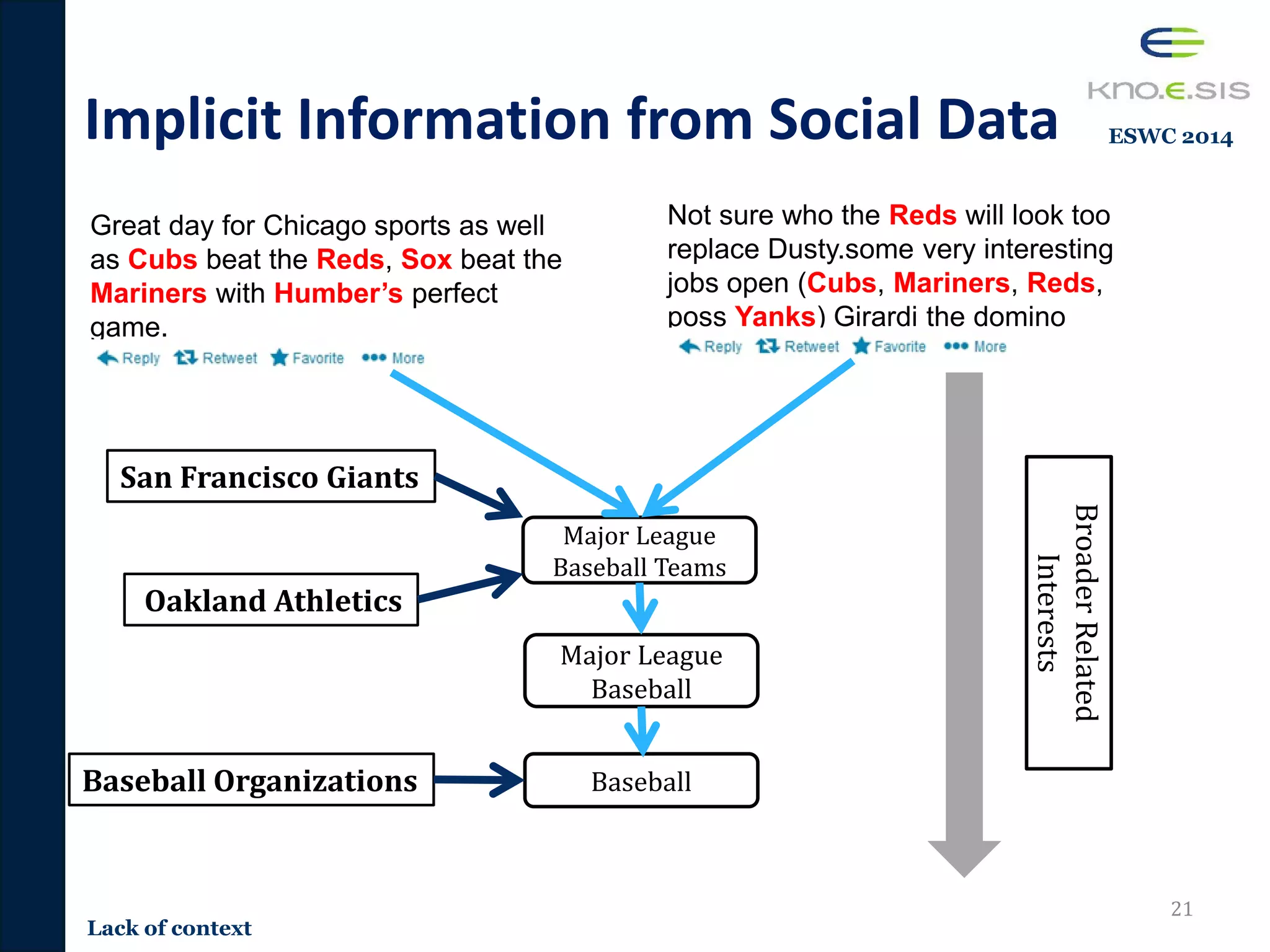
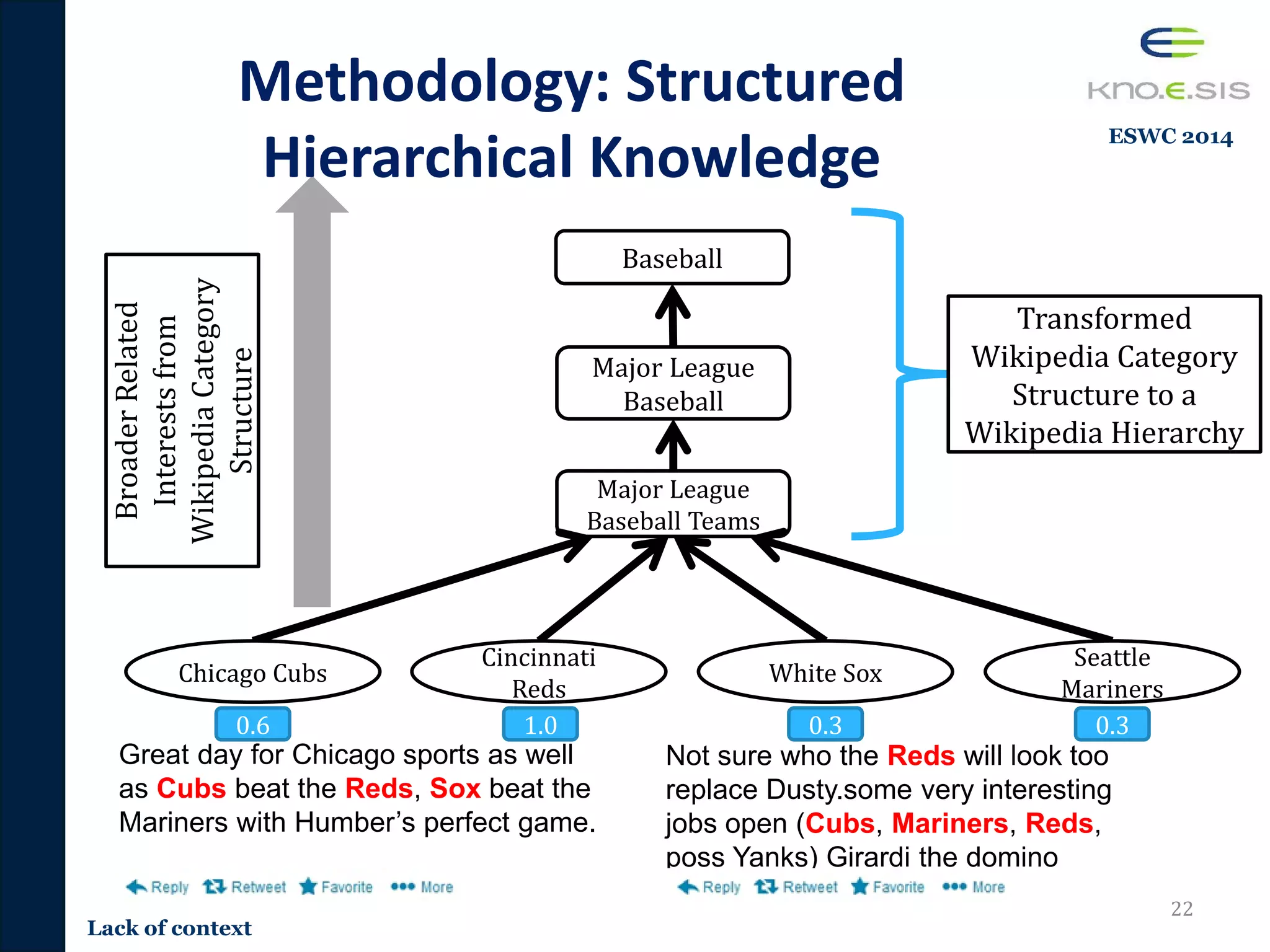
![Content Based User Interests
Identification from Social Data
20Semantics
Term Frequency
Based
Techniques
Lower Dim Space
as latent
semantics
Entity Based
Techniques
[Tao 2012][Ramage 2010]
Great day for Chicago sports as well
as Cubs beat the Reds, Sox beat the
Mariners with Humber’s perfect game.
Not sure who the Reds will look too
replace Dusty.some very interesting
jobs open (Cubs, Mariners, Reds, poss
Yanks) Girardi the domino sports
[Yan 2012]
Term Freq
great 1
day 1
sports 2
cubs 2
…
Dim Dist
1dim 0.3
2dim 0.2
3dim 0.2
4dim 0.1
5dim 0.4
Wiki-Entities Freq
Chicago Cubs 2
Cinci Reds 2
White Sox 1
NY Yankees 1
…
Knowledge
Enabled
Approaches
Lack of context
ESWC 2014](https://image.slidesharecdn.com/pavan-defense-slideshare-160427152038/75/Personalized-and-Adaptive-Semantic-Information-Filtering-for-Social-Media-Pavan-Kapanipathi-s-Defense-20-2048.jpg)
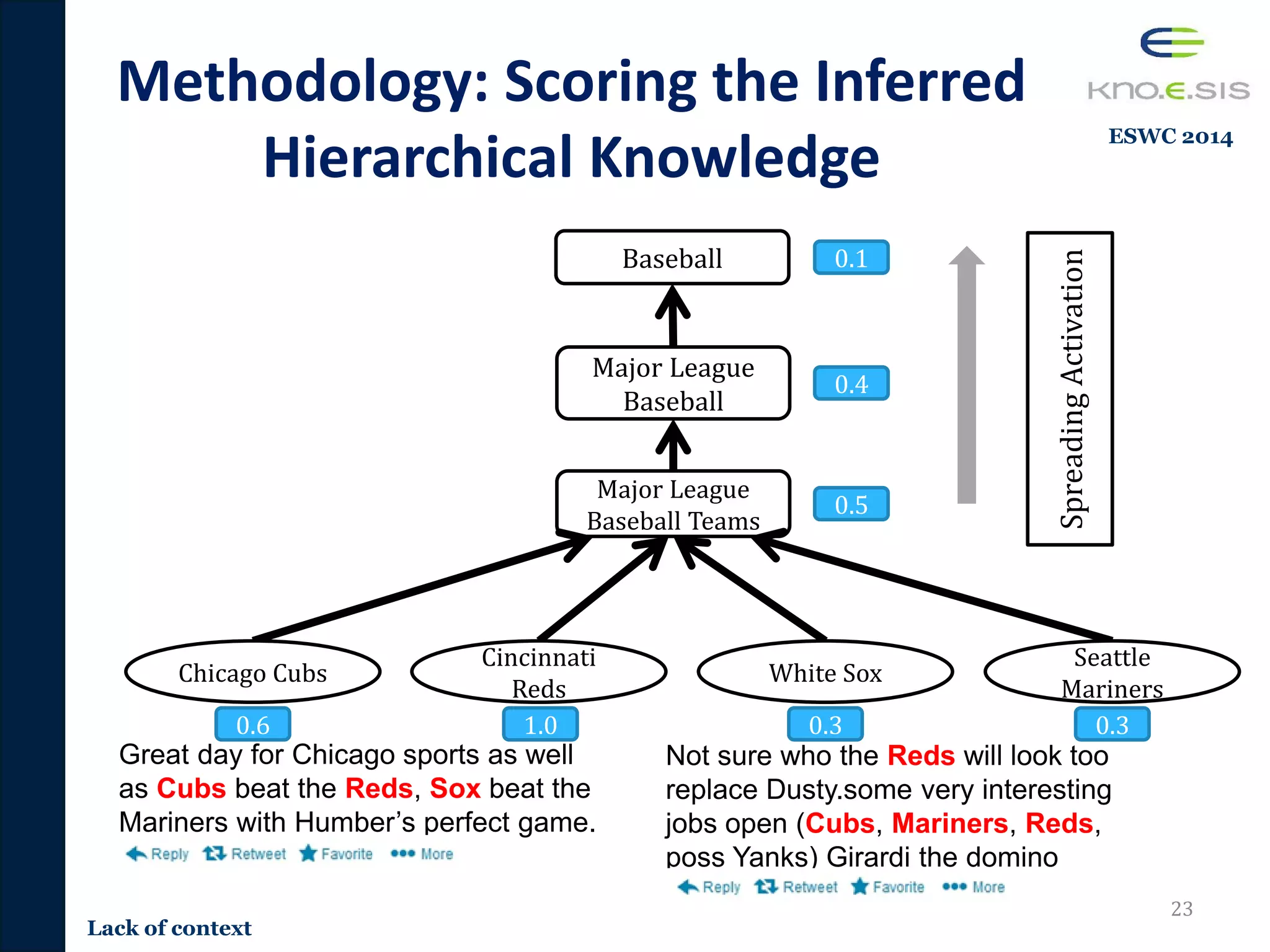


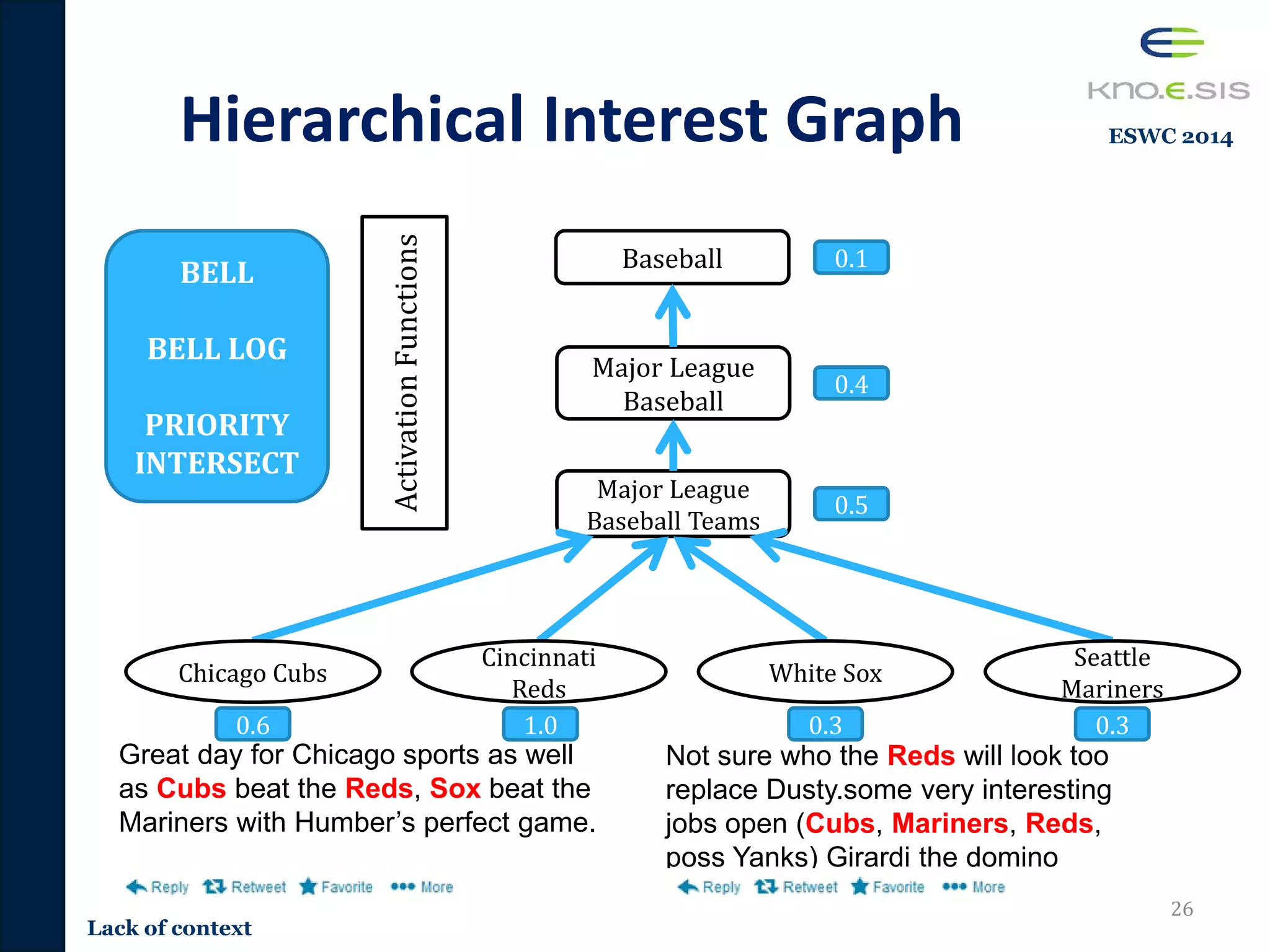
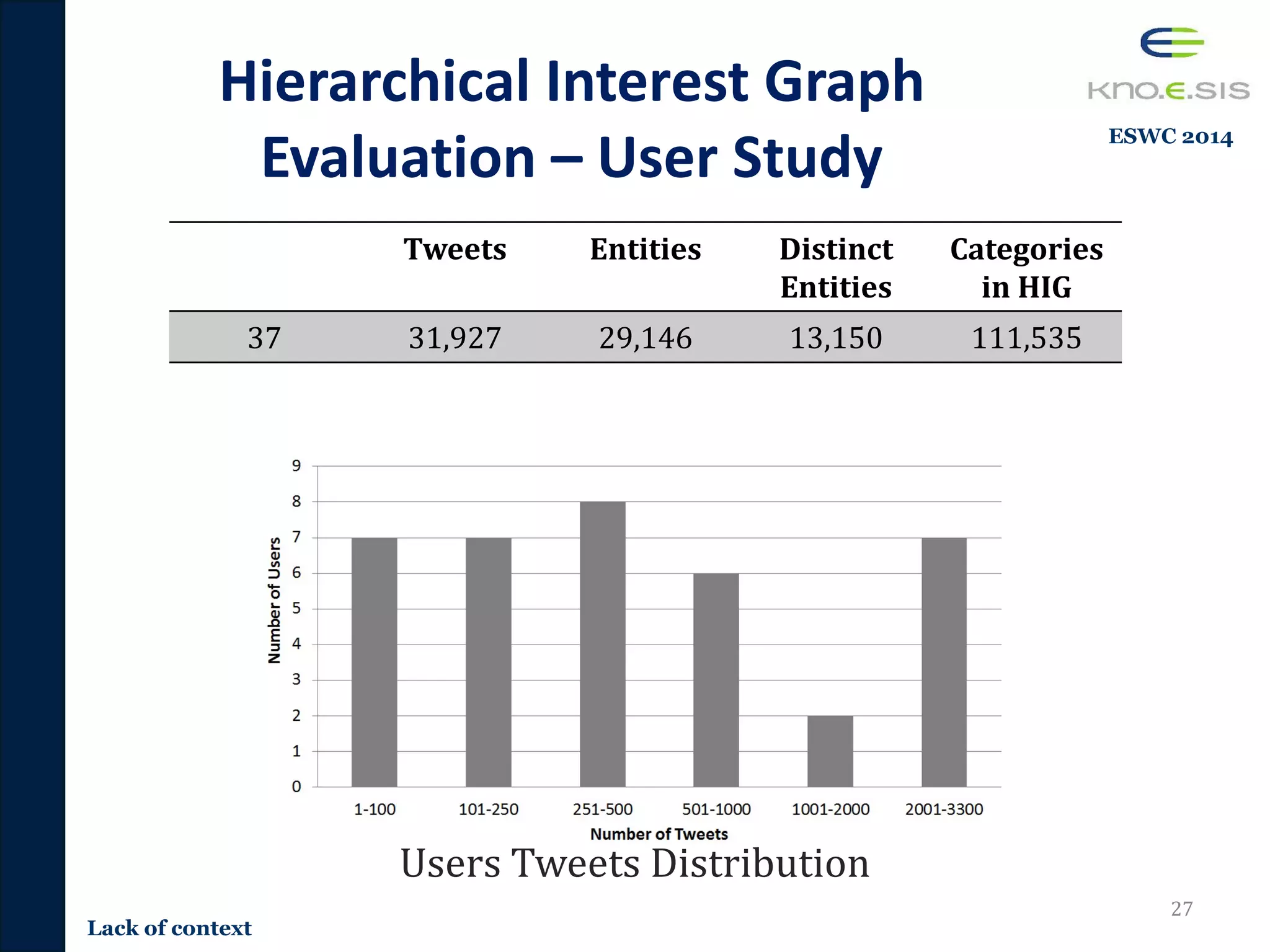
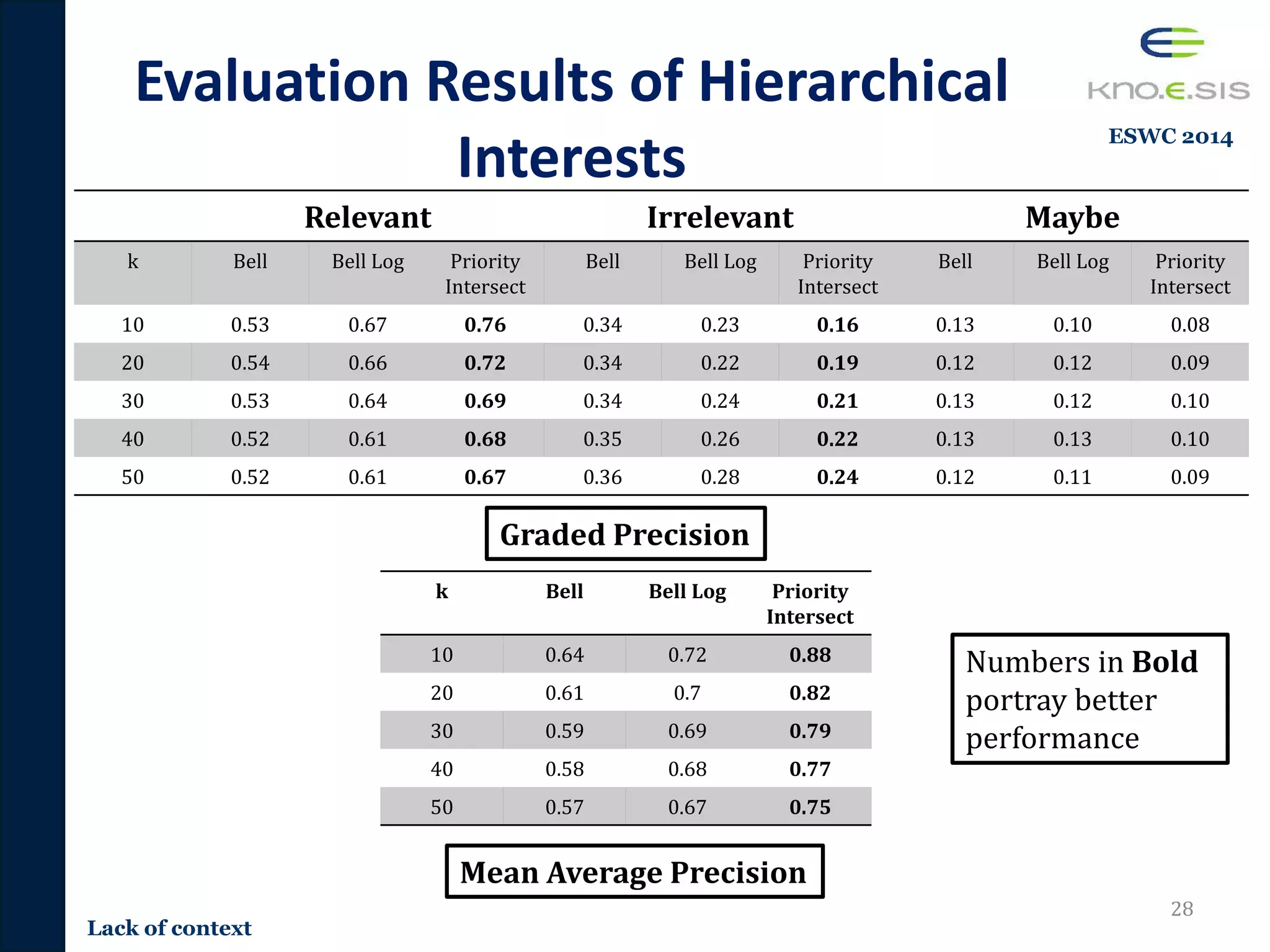

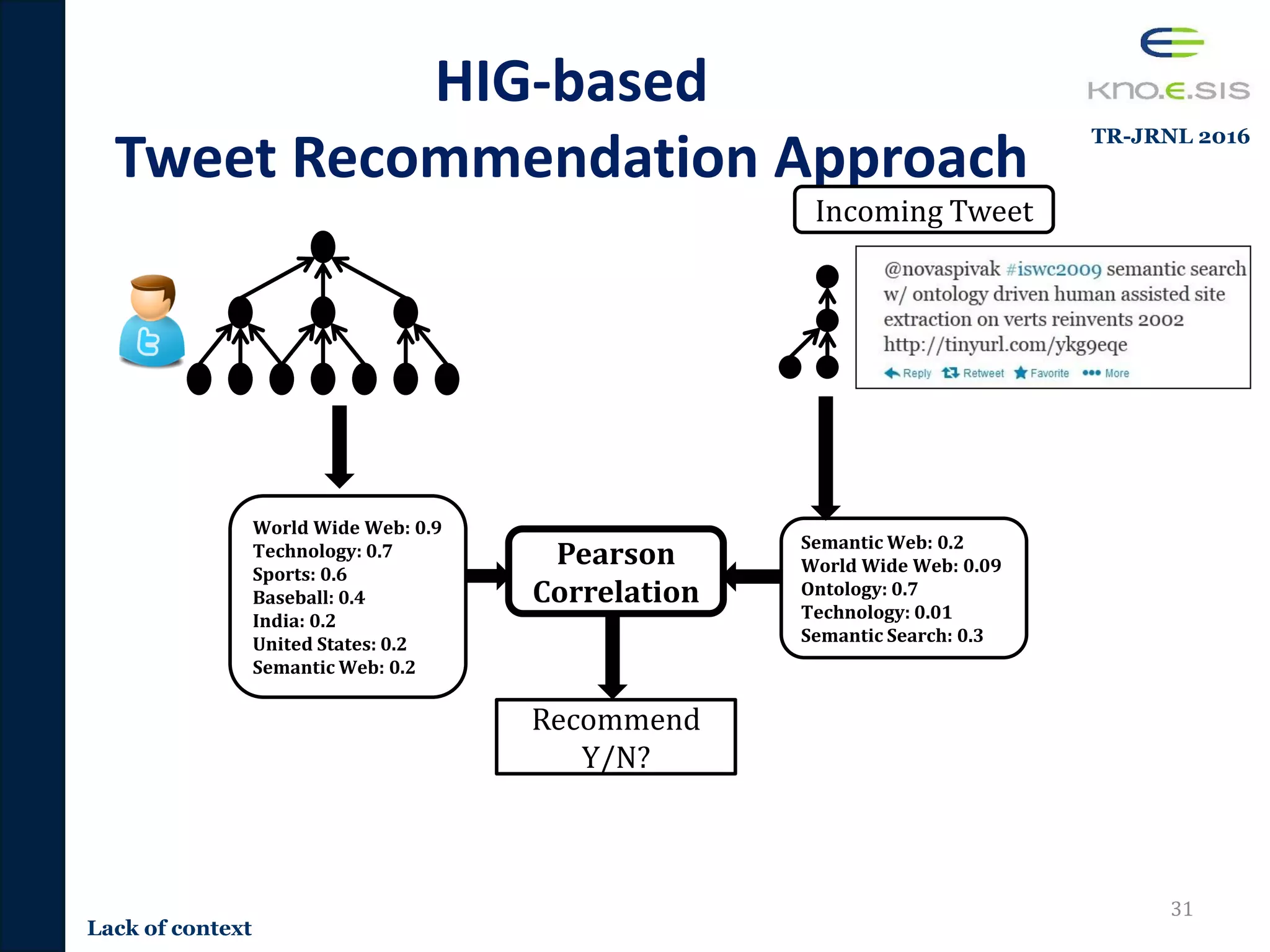
![Content-based Tweet
Recommendation Approaches
• Term Frequency based approaches
– User profiles: Built on scoring important terms
• TF, TF-IDF
• Entity Frequency [Tao 2012]
– User profiles: Built on scoring important entities
• Wikipedia Entities
• Extracted using Zemanta
• Support Vector Machines (SVMrank) [Duan 2010]
– User Models built using content and tweet based features
– Tweet content features: Similarity to users tweets, similarity of hashtags,
tweet length, mention of URLs, mention of hashtags.
• Latent Dirichlet Allocation [Ramage 2010]
– User profiles: Distribution of 5 latent topics.
32
Lack of context
TR-JRNL 2016](https://image.slidesharecdn.com/pavan-defense-slideshare-160427152038/75/Personalized-and-Adaptive-Semantic-Information-Filtering-for-Social-Media-Pavan-Kapanipathi-s-Defense-32-2048.jpg)

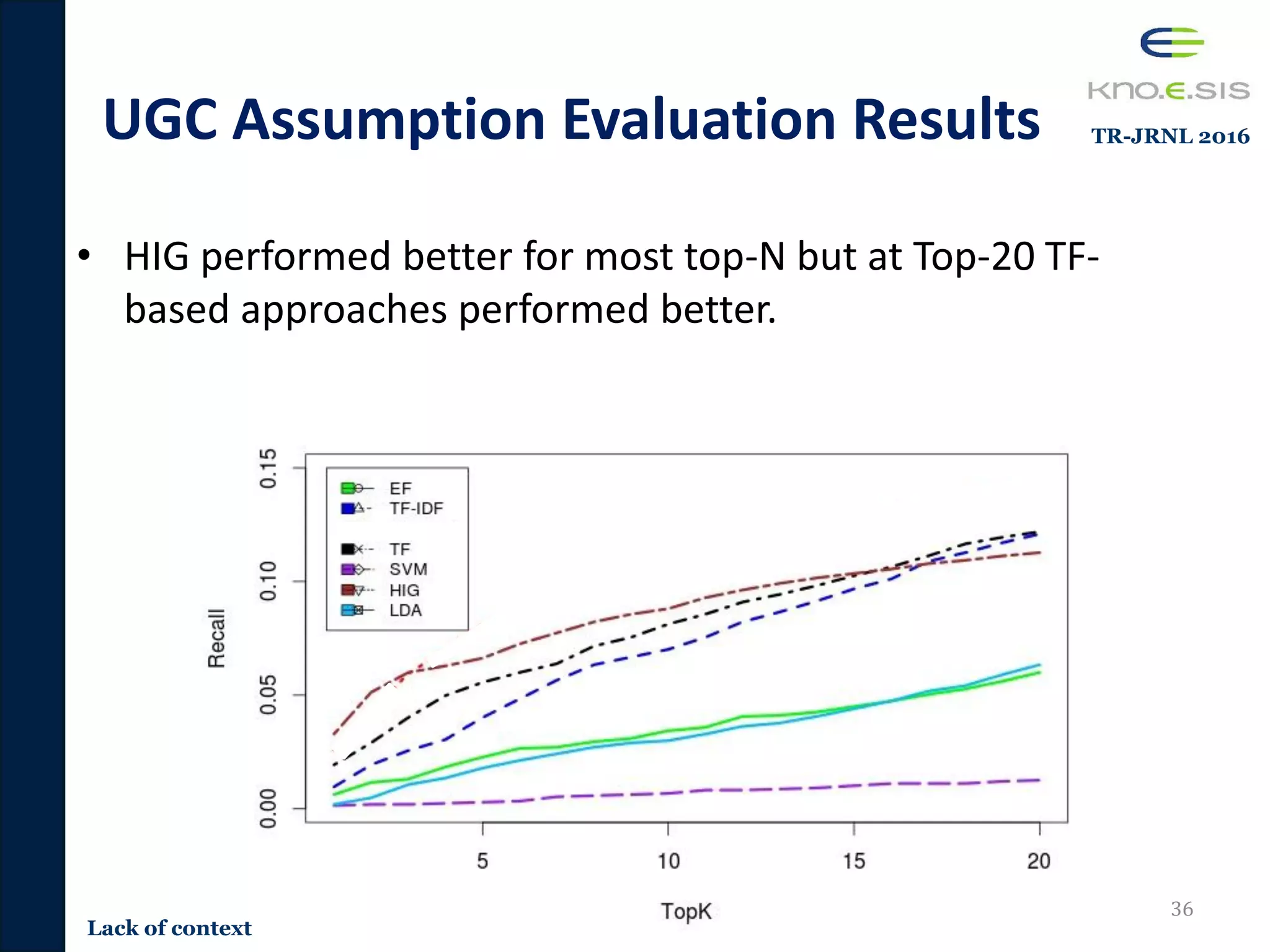
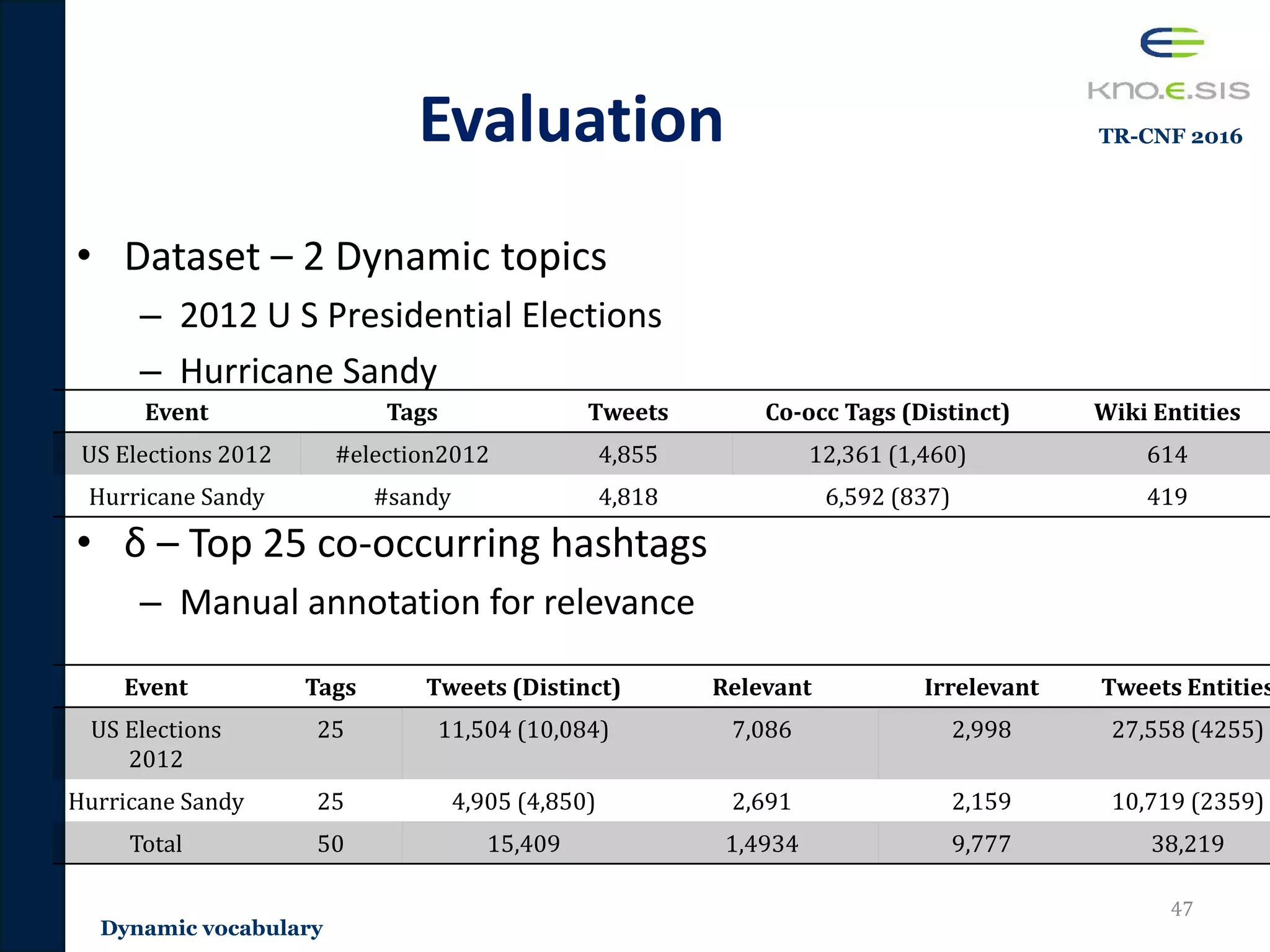
![Evaluation Methodology
• Transformed to a top-N recommendation evaluation
– Popular top-N evaluation methodology by Cremonesi et al. [Cremonesi
2010] for Precision/Recall
• Methodology
– For every test tweet – pick random 1000 tweets not tweeted/retweeted
by the author of the test tweet
• Random tweets are considered to be irrelevant to the user
– Score and rank the test tweet with the 1000 random tweets using the
recommendation algorithm
• TF, TFIDF, Entity-based, SVMrank, LDA, and HIG
– If the test tweet is within the top-N, its considered to be a hit otherwise
not ( T is the total number of test tweets)
𝑟𝑒𝑐𝑎𝑙𝑙 = ℎ𝑖𝑡𝑠 𝑇
34
Lack of context
TR-JRNL 2016](https://image.slidesharecdn.com/pavan-defense-slideshare-160427152038/75/Personalized-and-Adaptive-Semantic-Information-Filtering-for-Social-Media-Pavan-Kapanipathi-s-Defense-34-2048.jpg)
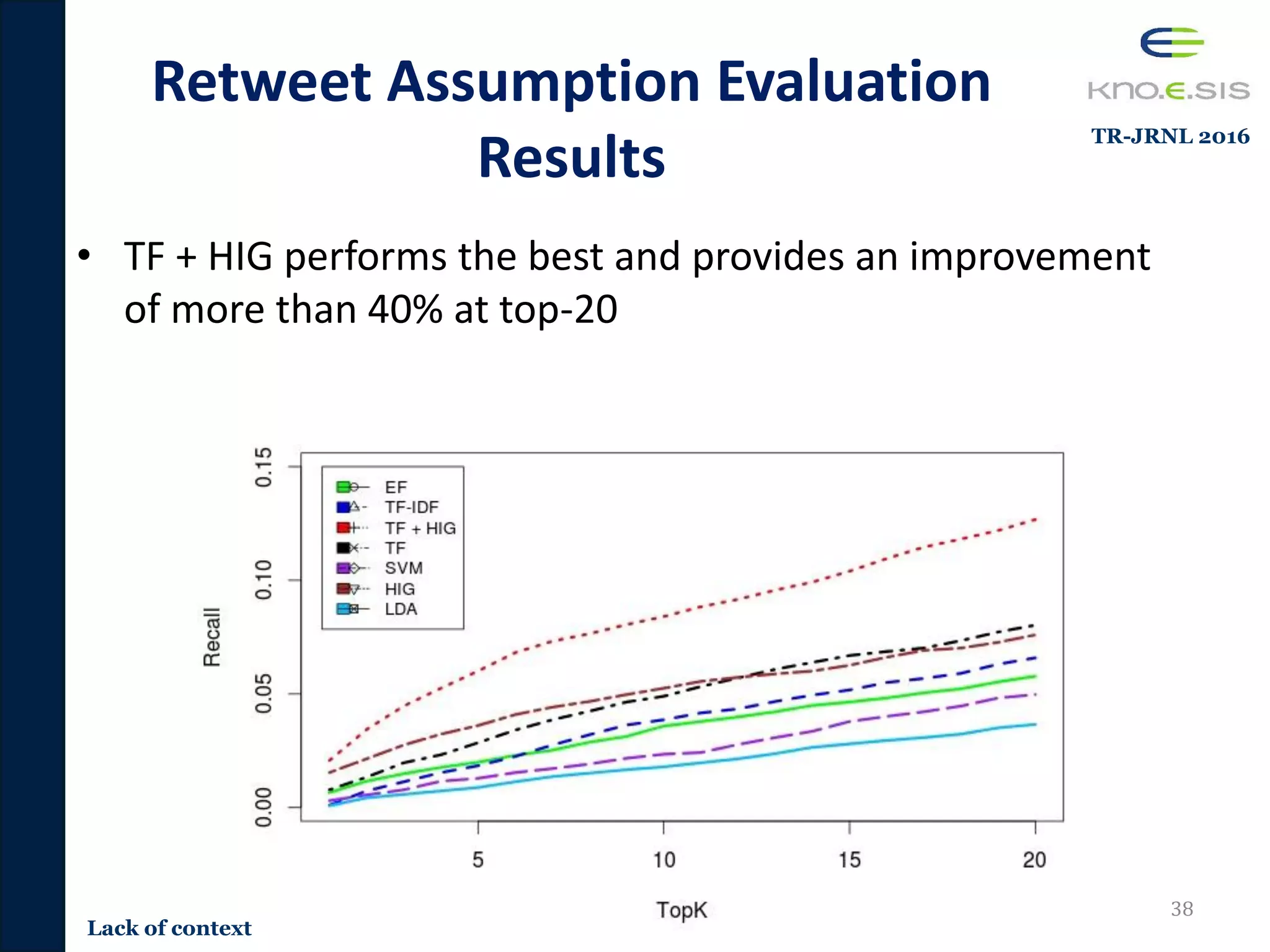
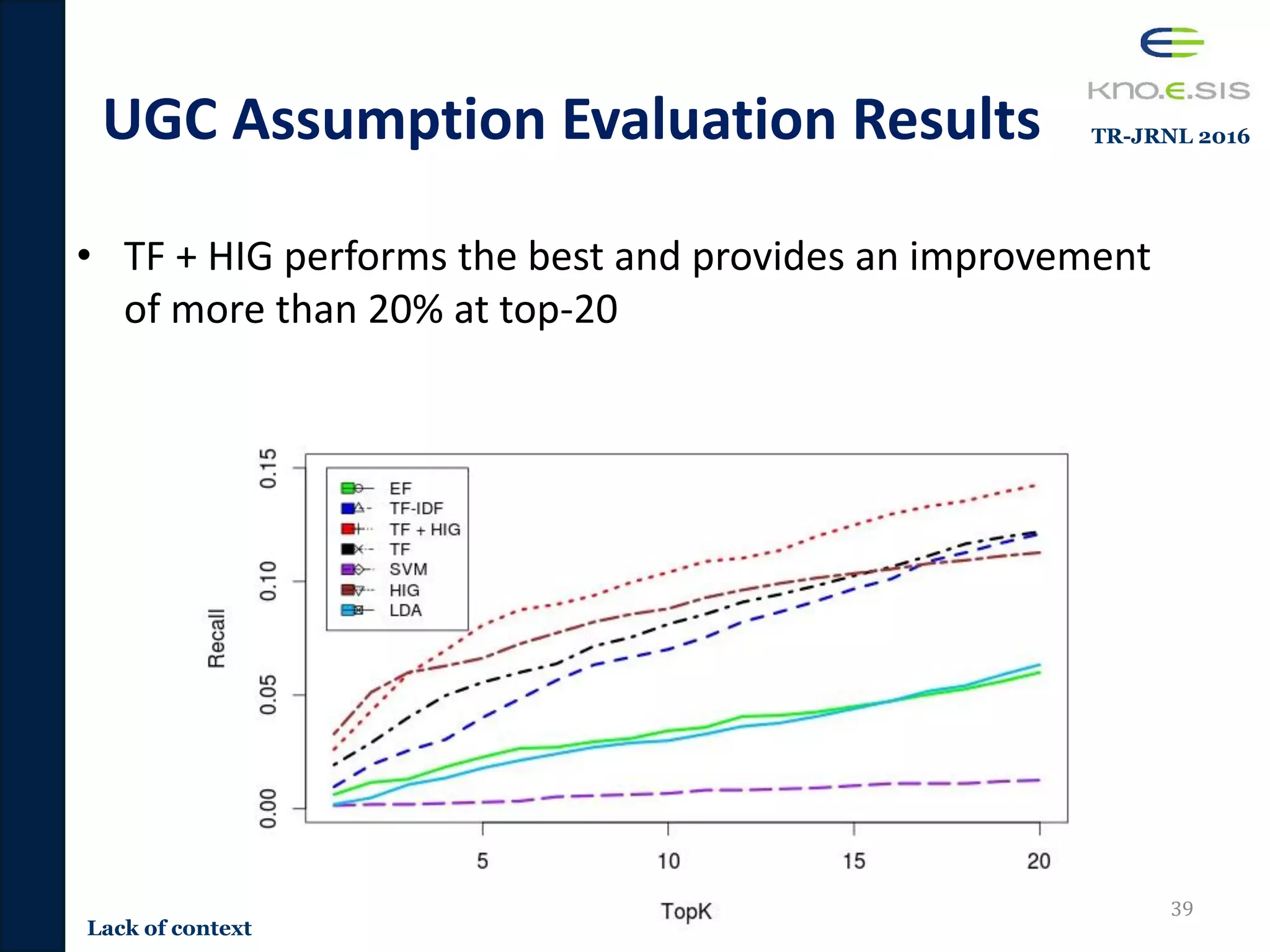
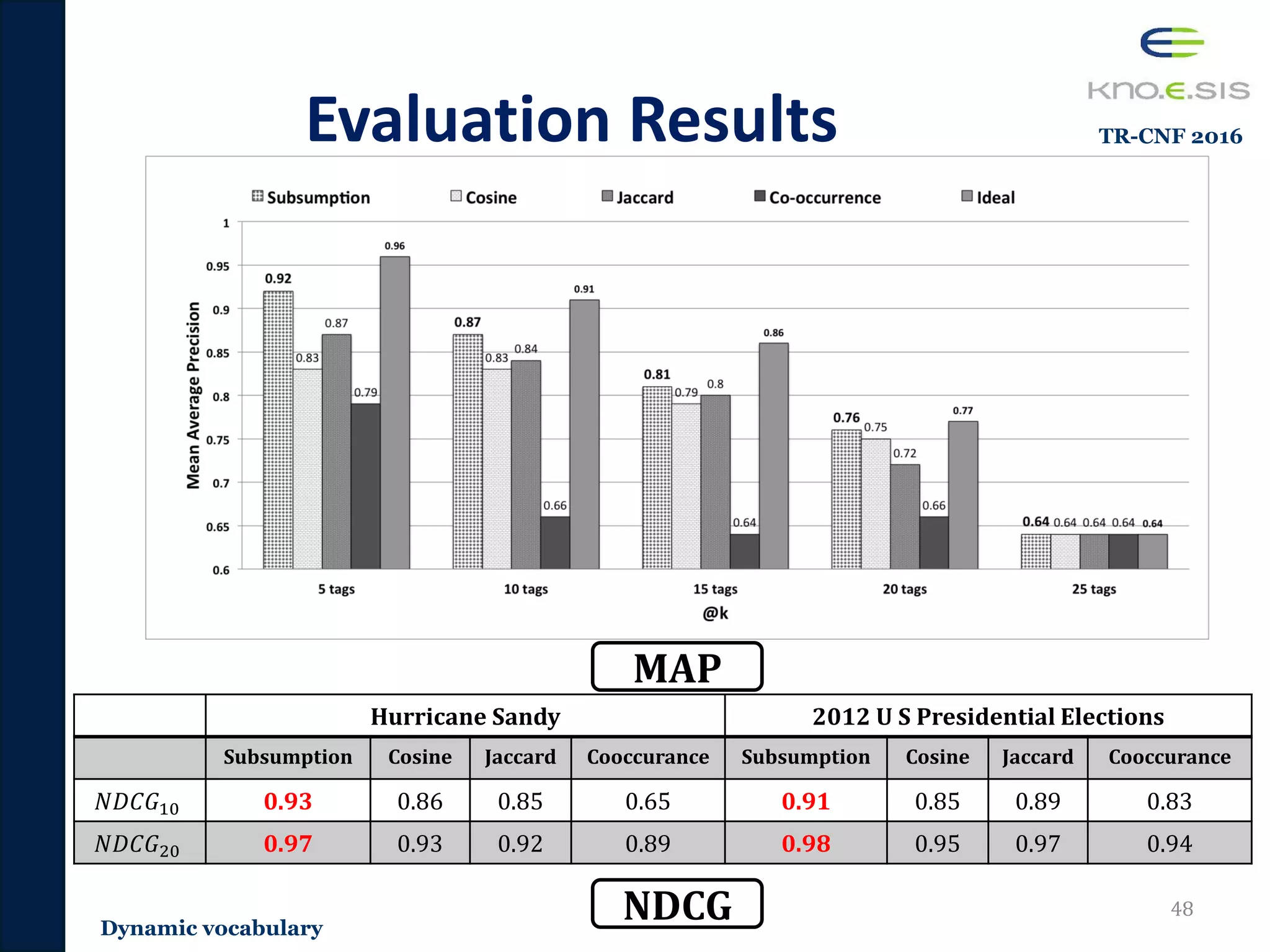
![Retweet Assumption Evaluation
Results
• Term frequency performs the best for recommending
retweets tweets [Ramage et al 2010]
35
Lack of context
TR-JRNL 2016](https://image.slidesharecdn.com/pavan-defense-slideshare-160427152038/75/Personalized-and-Adaptive-Semantic-Information-Filtering-for-Social-Media-Pavan-Kapanipathi-s-Defense-35-2048.jpg)














![Publications
• [NOISE 2015] Raghava Mutharaju, and Pavan Kapanipathi. Are We Really Standing on the
Shoulders of Giants? 1st Workshop on Negative or Inconclusive Results in Semantic Web
2015, ESWC, 2015.
• [KNOW 2015] Siva Kumar Chekula, Pavan Kapanipathi, Derek Doran, Amit Sheth. Entity
Recommendations Using Hierarchical Knowledge Bases. 4th International Workshop on
Knowledge Discovery and Data Mining Meets Linked Open Data, 2015.
• [ESWC 2015] Pavan Kapanipathi, Revathy Krishnamurthy (Joint first author), Amit Sheth,
Krishnaprasad Thirunarayan. Knowledge Enabled Approach to Predict the Location of Twitter
Users. In Extended Semantic Web Conference, 2015. (acceptance rate 23%).
• [ESWC 2014] Pavan Kapanipathi, Prateek Jain, Chitra Venkataramani, Amit Sheth. User
Interests Identification on Twitter Using a Hierarchical Knowledge Base. In Extended Semantic
Web Conference 2014, Crete Greece. (acceptance rate 23%)
• [WWWComp 2014] Pavan Kapanipathi, Prateek Jain, Chitra Venkataramani, Amit Sheth.
Hierarchical Interest Graph from Twitter. 23rd International conference on World Wide Web
companion 2014 (WWW companion 2014), Seoul, South Korea.
• [WI 2013] Fabrizio Orlandi, Pavan Kapanipathi, Alexandre Passant, Amit Sheth. Characterising
concepts of interest leveraging Linked Data and the Social Web. The 2013 IEEE/WIC/ACM
International Conference on Web Intelligence, Atlanta, USA, United States, 2013.
• [SPIM 2011] Pavan Kapanipathi, Fabrizio Orlandi, Amit Sheth, Alexandre Passant.
Personalized Filtering of the Twitter Stream. 2nd workshop on Semantic Personalized
Information Management at ISWC 2011, September 2011.
• [ISWC 2011] Pavan Kapanipathi, Julia Anaya, Amit Sheth, Brett Slatkin, Alexandre Passant.
Privacy-Aware and Scalable Content Dissemination in Distributed Social Network. 10th
International Semantic Web Conference 2011, Bonn, Germany, September 2011. (acceptance
rate 22%)
61
Conclusion](https://image.slidesharecdn.com/pavan-defense-slideshare-160427152038/75/Personalized-and-Adaptive-Semantic-Information-Filtering-for-Social-Media-Pavan-Kapanipathi-s-Defense-61-2048.jpg)
![Conclusion
Publications• [ISWCDEM 2011] Pavan Kapanipathi, Julia Anaya, Alexandre Passant . SemPuSH: Privacy-
Aware and Scalable Broadcasting for Semantic Microblogging. 10th International Semantic
Web Conference 2011,
• [FSWE 2011] Pavan Kapanipathi. SMOB: The Best of Both Worlds. Federated Social Web
Europe Conference, Berlin, June 3rd -5th 2011.
• [WEBSCI 2011] Alexandre Passant, Owen Sacco, Julia Anaya, Pavan Kapanipathi. Privacy-By-
Design in Federated Social Web Applications, Websci 2011, Koblenz, Germany June 14-17,
2011.
• [ISEM 2010] Pablo Mendes, Pavan Kapanipathi, Alexandre Passant. Twarql: Tapping into the
Wisdom of the Crowd. Triplification Challenge 2010 at 6th International Conference on
Semantic Systems (I-SEMANTICS), [WI 2010]
• [WI 2010] Pablo Mendes, Alexandre Passant, Pavan Kapanipathi, Amit Sheth. Linked Open
Social Signals.WI2010 IEEE/WIC/ACM International Conference on Web Intelligence (WI-10),
• [WEBSCI 2010] Pablo Mendes, Pavan Kapanipathi, Delroy Cameron, Amit Sheth. Dynamic
Associative Relationships on the Linked Open Data Web. In Proceedings of the WebSci10:
Extending the Frontiers of Society On-Line
• [TR-CNF 2016] Pavan Kapanipathi, Krishnaprasad Thirunarayan, Fabrizio Orlandi, Amit Sheth,
Pascal Hitzler. A Real-Time #approach for Continuous Crawling of Events on Twitter by
Leveraging Wikipedia. Technical Report.
• [TR-JRNL 2016] Pavan Kapanipathi, Siva Kumar, Derek Doran, Prateek Jain, Chitra
Venkataramani, Amit Sheth. Hierarchical Knowledge Base enabled Twitter User Modeling and
Recommendation. (Journal).
• [TR-CNFC 2016] Siva Kumar, Pavan Kapanipathi, Derek Doran, Prateek Jain, Amit Sheth.
Exploring Taxonomical Interests for Entity Recommendations. Technical report, 2015.
• [TR-CNFC 2016] Sarasi Sarangi, Pavan Kapanipathi, Amit Sheth. Domain-specific Sub graph
Generation. Technical report, 2015. 62](https://image.slidesharecdn.com/pavan-defense-slideshare-160427152038/75/Personalized-and-Adaptive-Semantic-Information-Filtering-for-Social-Media-Pavan-Kapanipathi-s-Defense-62-2048.jpg)
![Conclusion
References
• [1] How Do People Use Social Media for Business/Finance News?
http://blog.marketwired.com/2013/11/12/how-do-people-use-social-media-for-businessfinance-news/
• [2] What is the role of social media in healthcare? http://worldofdtcmarketing.com/role-social-media-
healthcare/social-media-and-healthcare/
• [3] Social media use during disaster management http://www.emergency-management-degree.org/crisis/
• [Tao 2012] Tao, K., Abel, F., Gao, Q., and Houben, G.-J. (2012a). Tums: Twitter-based user
modeling service.
• [Ramage 2010] Ramage, D., Dumais, S., and Liebling, D. (2010). Characterizing microblogs with
topic models. AAAI’ 10.
• [Yan 2012] Yan, R., Lapata, M., and Li, X. (2012). Tweet recommendation with graph co-ranking. In
Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics.
• [Duan 2010] Duan, Y., Jiang, L., Qin, T., Zhou, M., and Shum, H.-Y. (2010). An empirical study on
learning to rank of tweets. COLING ’10
• [Cremonesi 2010]Cremonesi, P., Koren, Y., and Turrin, R. (2010). Performance of recommender
algorithms on top-n recommendation tasks. RecSys2010
• [Sriram 2010] Sriram, B., Fuhry, D., Demir, E., Ferhatosmanoglu, H., and Demirbas, M. (2010).
Short text classification in twitter to improve information filtering. SIGIR ’10
• [Derczynsk 2013] Derczynski, L., Maynard, D., Aswani, N., and Bontcheva, K. (2013). Microblog-
genre noise and impact on semantic annotation accuracy. HT ’13,
• [Ferron 2011] Ferron, M. and Massa, P. (2011). Collective memory building in wikipedia: the case
of north african uprisings. WikiSys2011 63](https://image.slidesharecdn.com/pavan-defense-slideshare-160427152038/75/Personalized-and-Adaptive-Semantic-Information-Filtering-for-Social-Media-Pavan-Kapanipathi-s-Defense-63-2048.jpg)



The document discusses the development of a personalized and adaptive information filtering system for social media, addressing challenges such as information overload, the lack of context in short-text posts, and the dynamic nature of vocabulary on platforms like Twitter and Facebook. It proposes utilizing background knowledge and semantic web technologies, specifically leveraging Wikipedia, to enhance user interest modeling and improve relevance in information delivery. The thesis focuses on creating a scalable and effective filtering system that adapts to user interests and real-time changes in social media content.






















































































