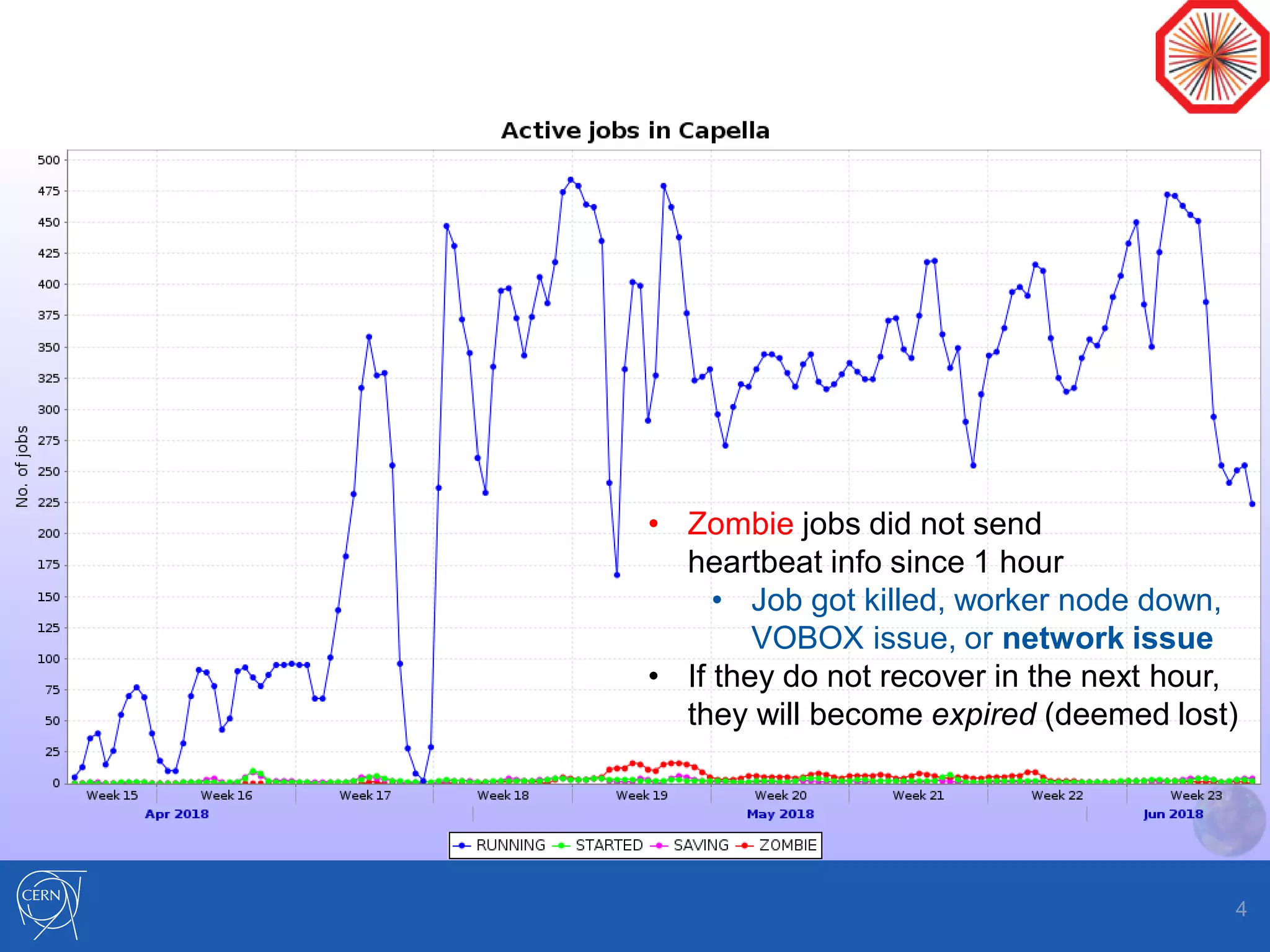
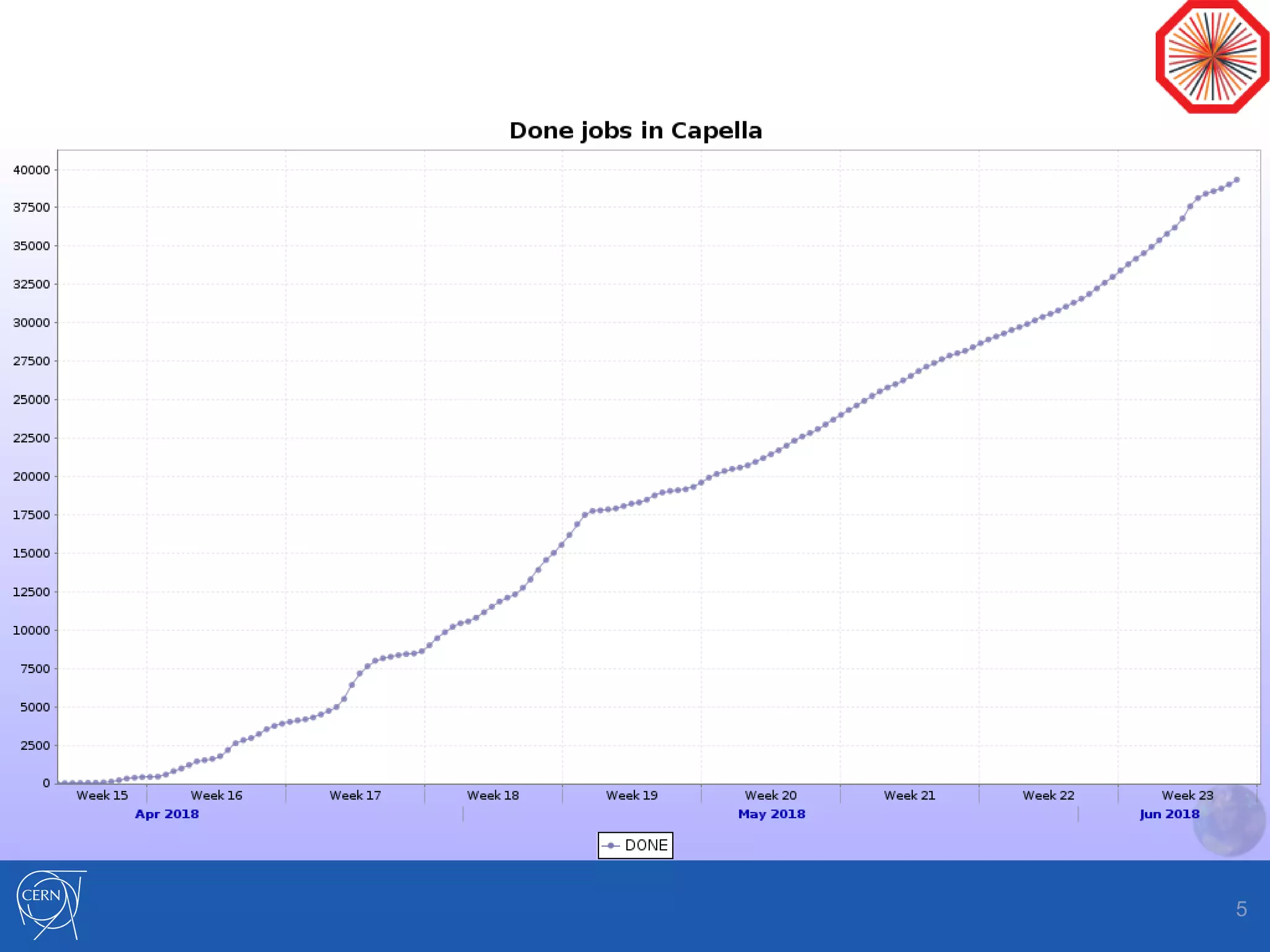
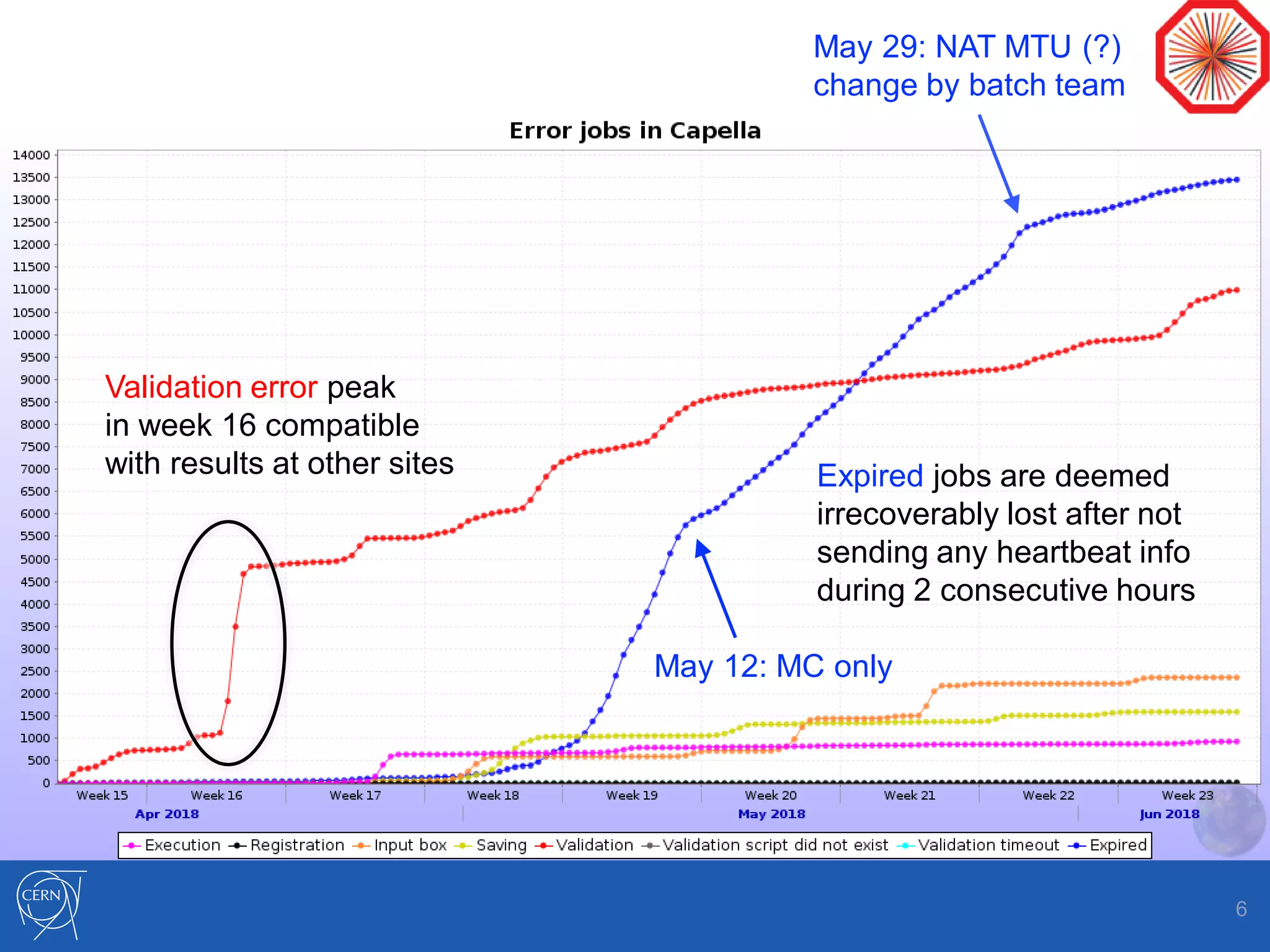
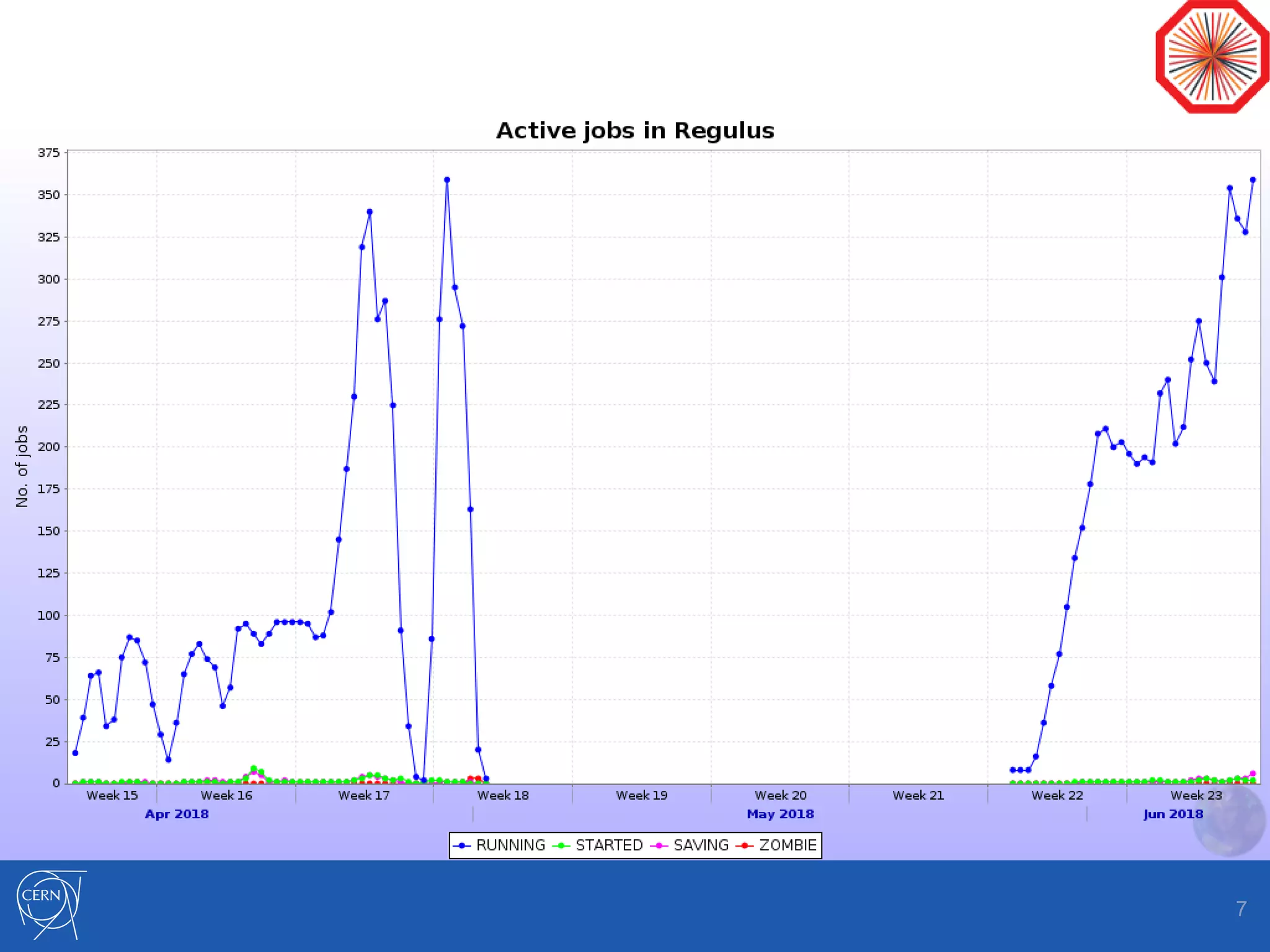
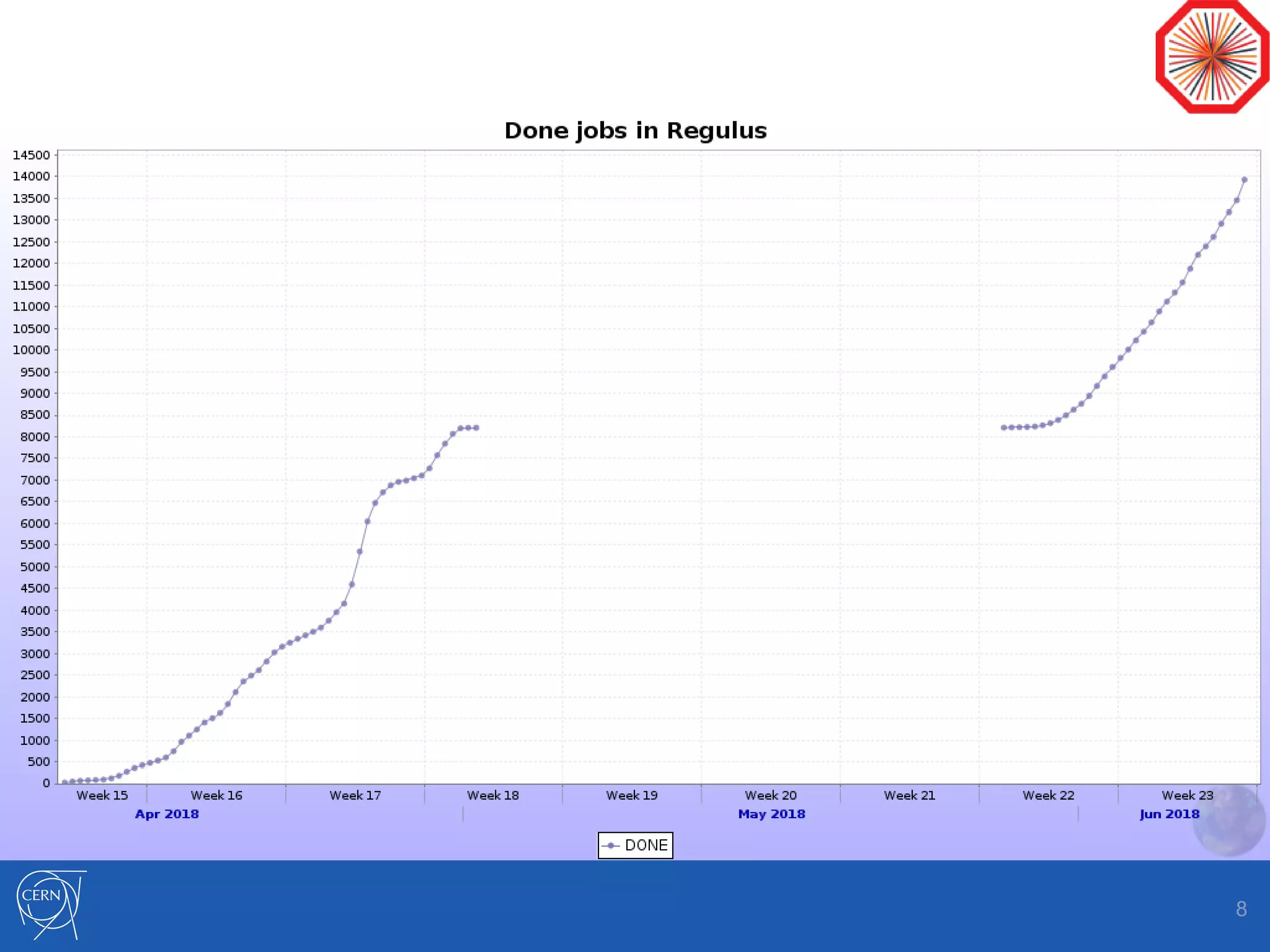
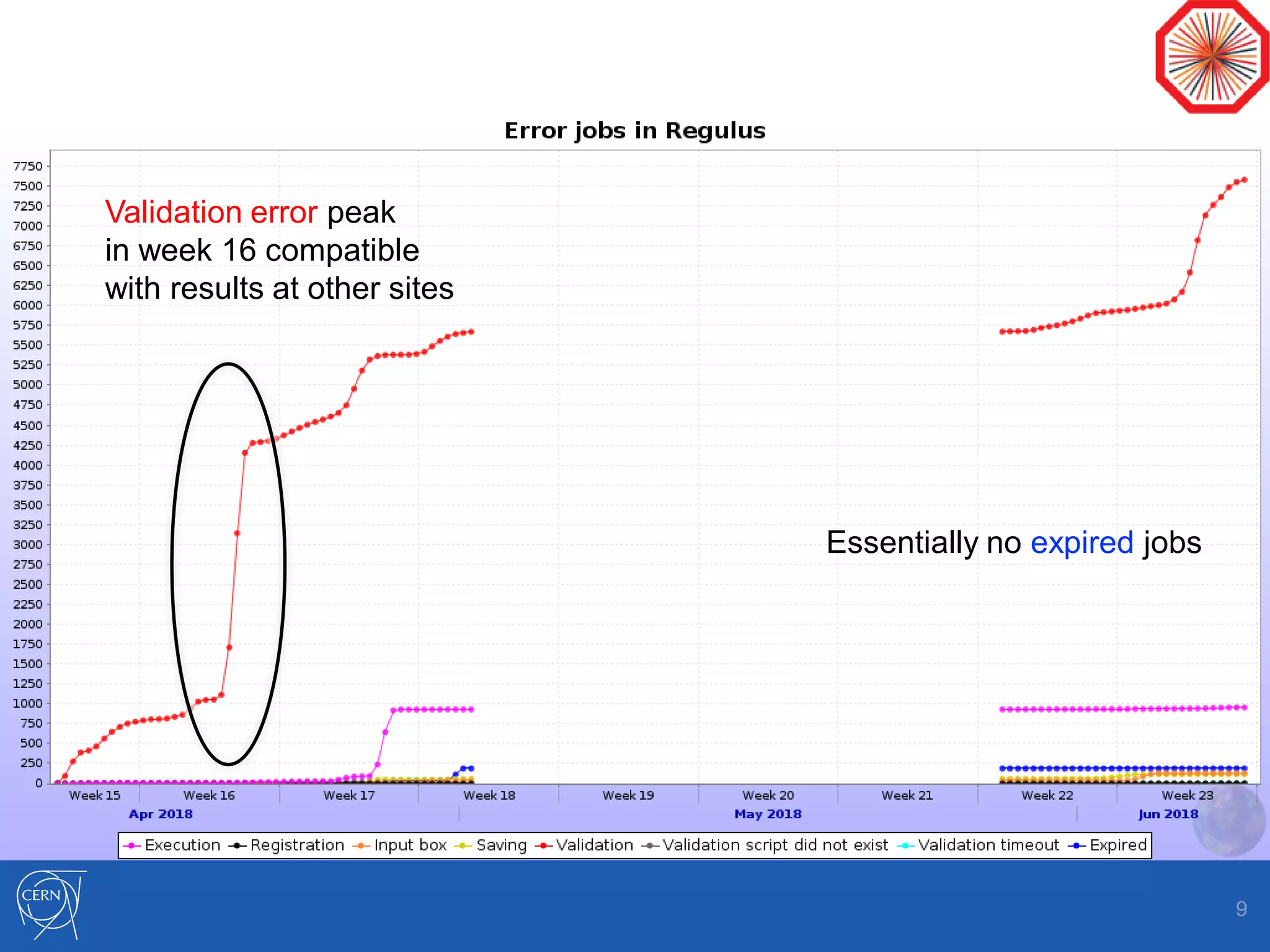
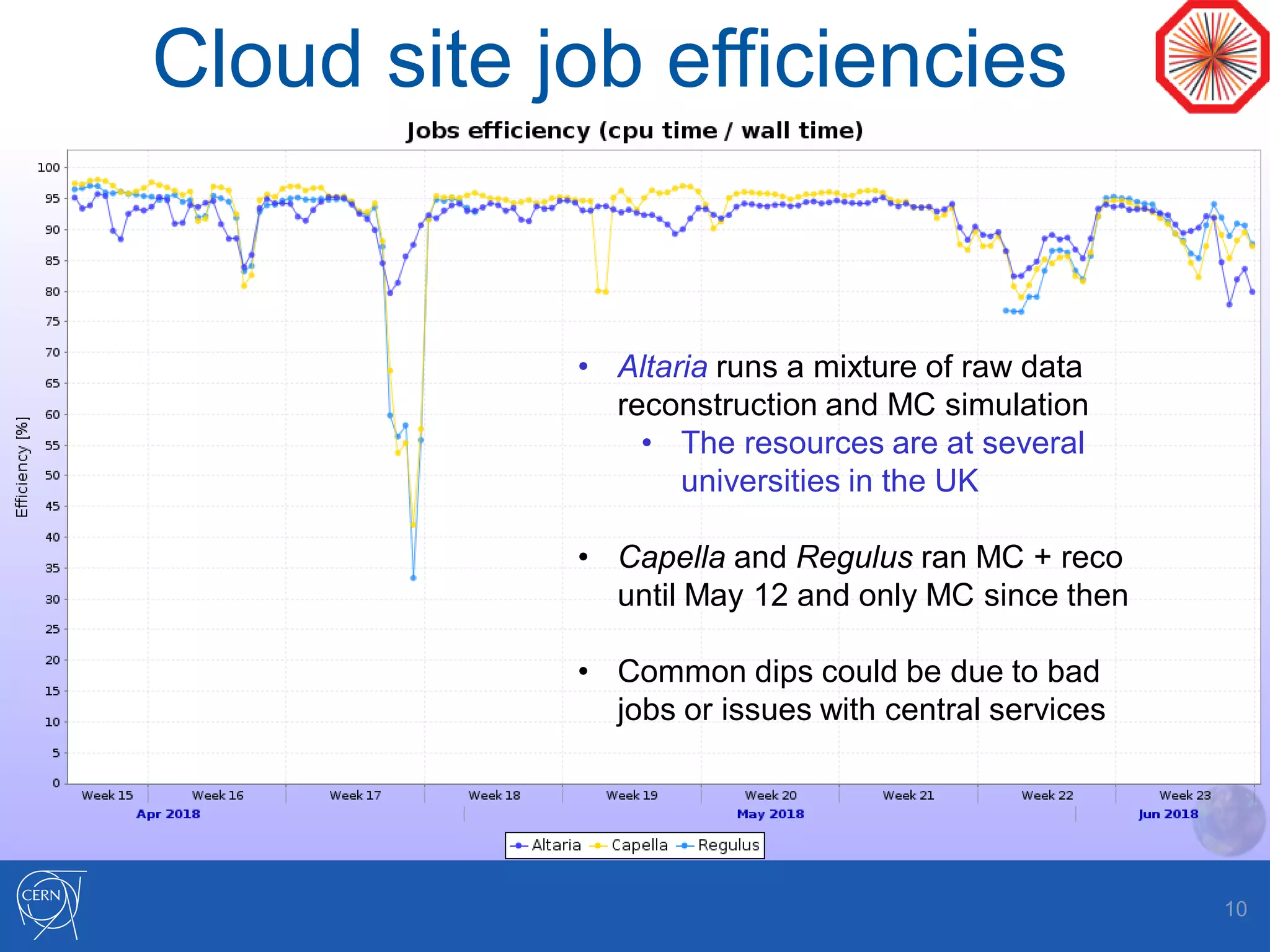
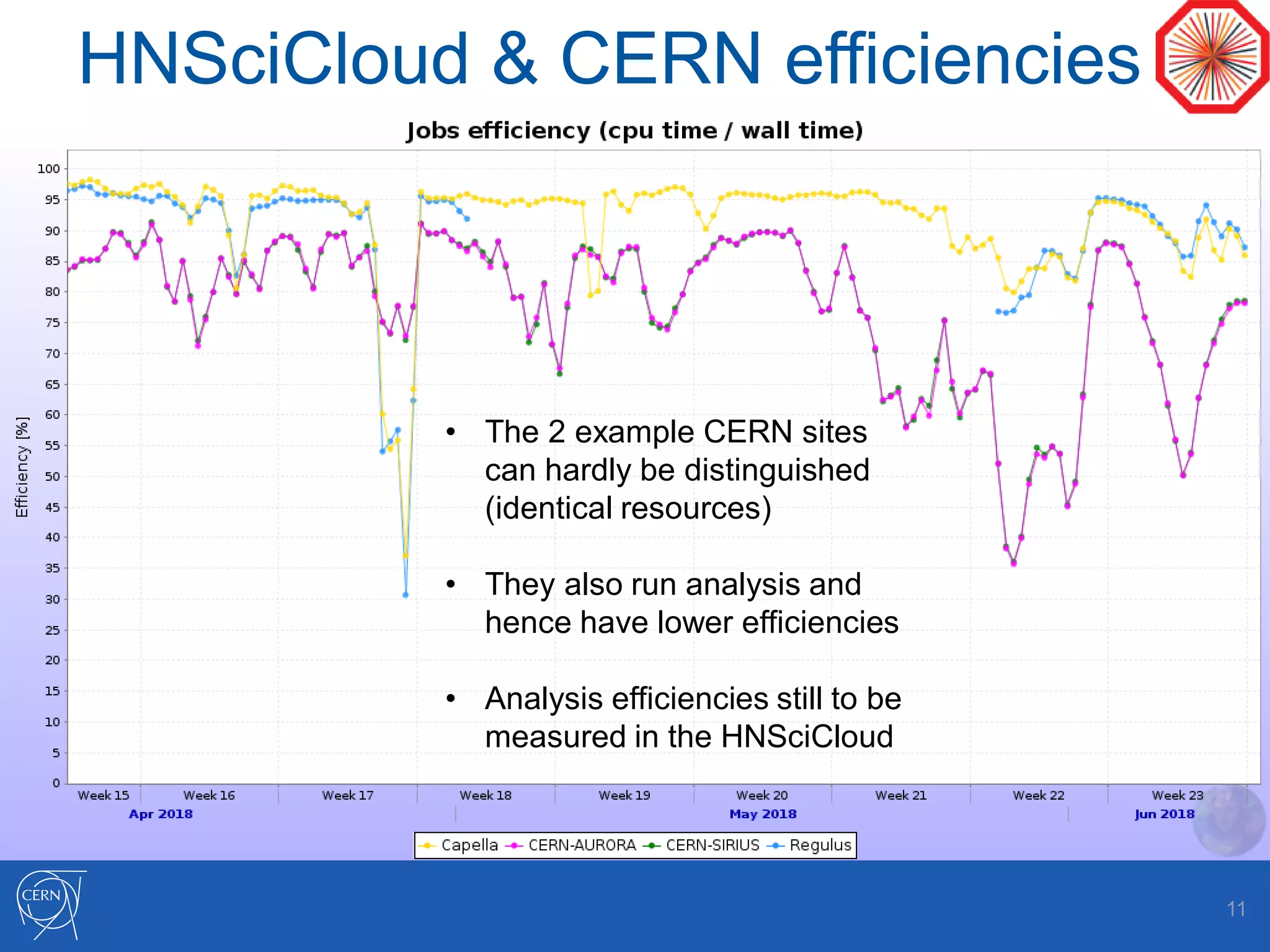
Helix Nebula Science Cloud is providing computing resources for the ALICE experiment through two virtual sites - Capella and Regulus. Jobs submitted to these sites are directed to T-Systems or RHEA cloud resources. Since starting in April 2018, ALICE has been able to run Monte Carlo simulations on the cloud resources, though reconstruction jobs saw high failure rates until being restricted to simulations in May. While efficiencies still need measurement for other job types, the cloud resources have shown efficiencies comparable to CERN sites for simulations. Further optimization is needed to address expired jobs and improve performance of I/O-intensive workloads.