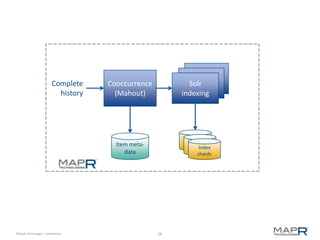
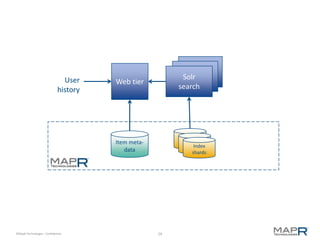
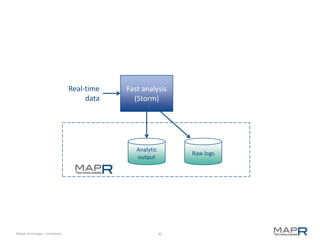
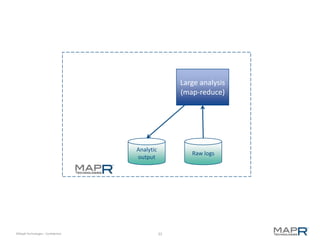
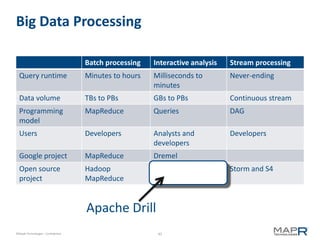
The document discusses the transformative power of Hadoop in business, outlining its past, present, and future capabilities. It highlights the evolution of Hadoop from a basic batch processing model to integrating real-time processing and advanced analytics while showcasing examples of successful implementations. MapR Technologies is emphasized as a key player in this space, providing innovative solutions and support for Apache Drill.































![Logical Plan Syntax:
query:[
{
op:"sequence", do:[
{ op: "scan",
memo: "initial_scan",
ref: "donuts",
source: "local-logs",
selection: {data: "activity"}
},
{ op: "transform",
transforms: [ { ref: "donuts.quanity", expr: "donuts.sales”} ]
},
{ op: "filter",
expr: "donuts.ppu < 1.00"
},
…
©MapR Technologies - Confidential 46](https://image.slidesharecdn.com/hcj-2013-01-21-130120212140-phpapp02/85/Hcj-2013-01-21-45-320.jpg)
![Logical Streaming Example
01
23
4
{ @id: <refnum>, op: “window-frame”,
input: <input>,
keys: [ 0
<name>,... 01
], 012
ref: <name>, 123
before: 2, 234
after: here
}
©MapR Technologies - Confidential 47](https://image.slidesharecdn.com/hcj-2013-01-21-130120212140-phpapp02/85/Hcj-2013-01-21-46-320.jpg)
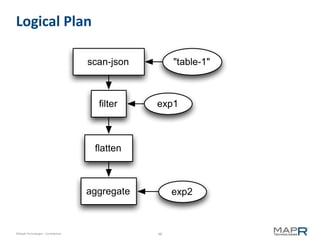
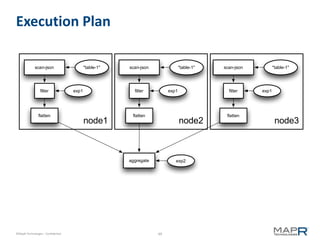
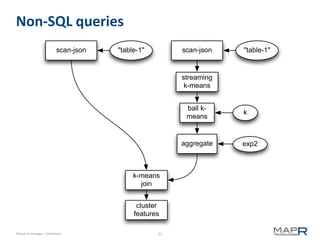
![Representing a DAG
18
aggregate exp2
19
{ @id: 19, op: "aggregate",
input: 18,
type: <simple|running|repeat>,
keys: [<name>,...],
aggregations: [
{ref: <name>, expr: <aggexpr> },...
]
}
©MapR Technologies - Confidential 50](https://image.slidesharecdn.com/hcj-2013-01-21-130120212140-phpapp02/85/Hcj-2013-01-21-49-320.jpg)