Downloaded 10 times


![[ 3 ]
The 4th Gen Internet2 Network
Internet2 Network
by the numbers
17 Juniper MX960 nodes
31 Brocade and Juniper
switches
49 custom colocation facilities
250+ amplification racks
15,717 miles of newly
acquired dark fiber
2,400 miles of partnered
capacity with Zayo
Communications
8.8 Tbps of optical capacity
100 Gbps of hybrid Layer 2
and Layer 3 capacity
300+ Ciena ActiveFlex 6500
network elements](https://image.slidesharecdn.com/237b837b-e9e0-4732-8bc9-3d90953c0b01-160830162408/75/Internet2-Bio-IT-2016-v2-3-2048.jpg)

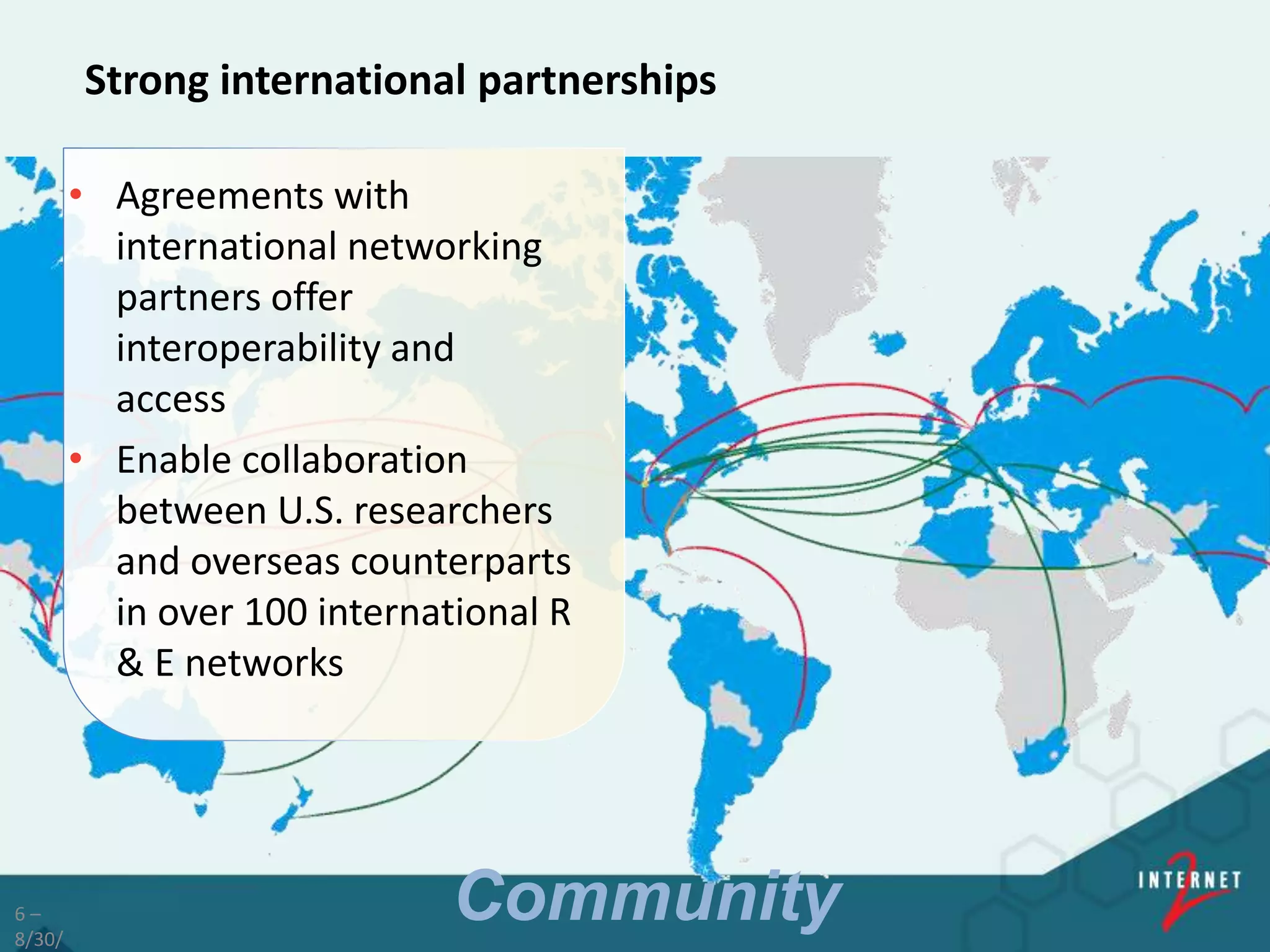
![[ 5 ]
Internet2 Members and Partners
255 Higher Education members
67 Affiliate members
41 R&E Network members
82 Industry members
65+ Int’l partners reaching over
100 Nations
93,000+ Community anchor institutions
Focused on member technology needs
since 1996
"The idea of being
able to collaborate
with anybody,
anywhere, without
constraint…"
—Jim Bottum, CIO,
Clemson University
Community](https://image.slidesharecdn.com/237b837b-e9e0-4732-8bc9-3d90953c0b01-160830162408/75/Internet2-Bio-IT-2016-v2-5-2048.jpg)

![[ 8 ]
*Routers
Stanford
Computer
Workstations
Berkeley, Stanford
Security
Systems
Univ of Michigan
Security
Systems
Georgia Tech
Social
Media
Harvard
Network
Caching
MIT
Search
Stanford](https://image.slidesharecdn.com/237b837b-e9e0-4732-8bc9-3d90953c0b01-160830162408/75/Internet2-Bio-IT-2016-v2-8-2048.jpg)
![[ 9 ]
The Route
to Innovation
August 30, 2016 © 2016 Internet2
Abundant Bandwidth
• Raw capacity now available on
Internet2 Network a key imagination enabler
• Incent disruptive use of new, advanced
capabilities
Software Defined Networking
• Open up network layer itself to innovation
• Let innovators communicate with and program
the network itself
• Allow developers to optimize the network for
specific applications
Science DMZ
• Architect a special solution to allow
higher-performance data flows
• Include end-to-end performance monitoring
server and software
• Include SDN server to support programmability](https://image.slidesharecdn.com/237b837b-e9e0-4732-8bc9-3d90953c0b01-160830162408/75/Internet2-Bio-IT-2016-v2-9-2048.jpg)


![Change
[ 12 ]](https://image.slidesharecdn.com/237b837b-e9e0-4732-8bc9-3d90953c0b01-160830162408/75/Internet2-Bio-IT-2016-v2-12-2048.jpg)

![Networking
[ 14 ]](https://image.slidesharecdn.com/237b837b-e9e0-4732-8bc9-3d90953c0b01-160830162408/75/Internet2-Bio-IT-2016-v2-14-2048.jpg)
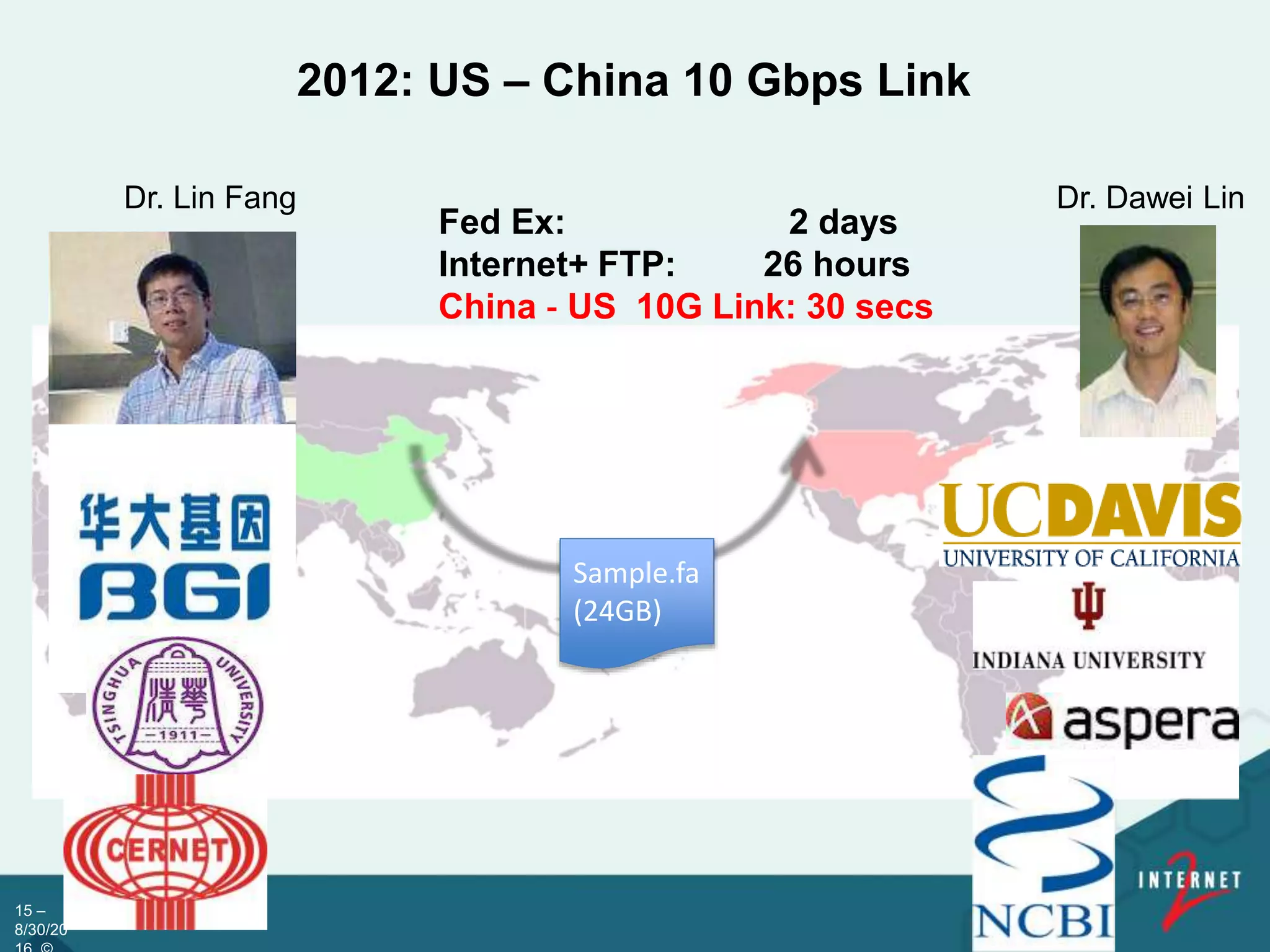
![NCBI/UC-Davis/BGI : First ultra high speed transfer of
genomic data between China & US, June 2012
“The 10 Gigabit network connection is even
faster than transferring data to most local hard
drives,” said Dr. Lin [of UC, Davis]. “The use of
a 10 Gigabit network connection will be
groundbreaking, very much like email
replacing hand delivered mail for
communication. It will enable scientists in the
genomics-related fields to communicate and
transfer data more rapidly and conveniently,
and bring the best minds together to better
explore the mysteries of life science.” (BGI
press release)
Life Sciences Engagement
16 Community](https://image.slidesharecdn.com/237b837b-e9e0-4732-8bc9-3d90953c0b01-160830162408/75/Internet2-Bio-IT-2016-v2-16-2048.jpg)

![[ 18 ]
USDA Agriculture Research Services Science Network
• USDA scope is far beyond human](https://image.slidesharecdn.com/237b837b-e9e0-4732-8bc9-3d90953c0b01-160830162408/75/Internet2-Bio-IT-2016-v2-18-2048.jpg)

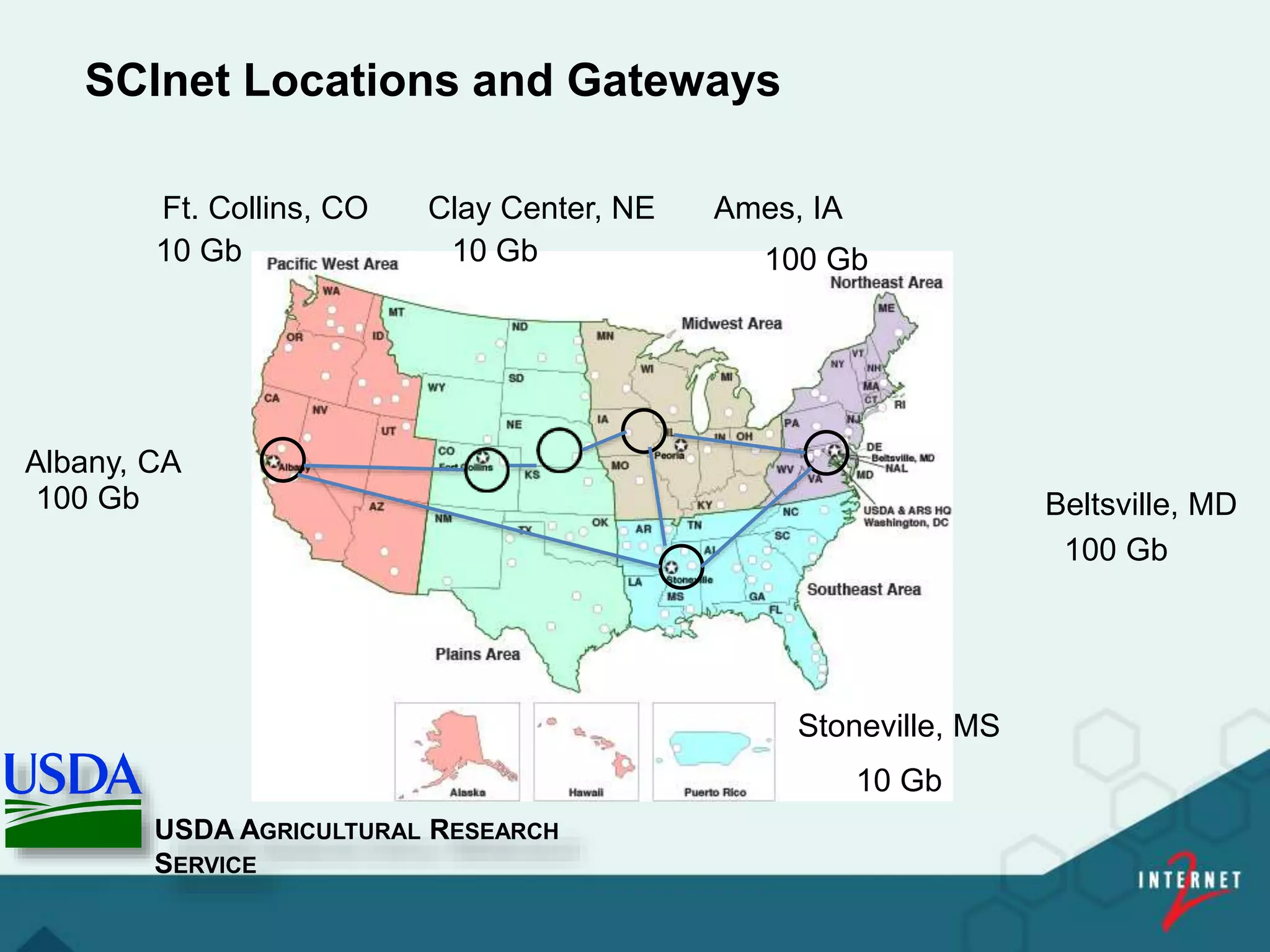
![[ 20 ]
ARS Big Data Initiative
Big Data Workshop Recommendations,
(February 2013)
Three Pillars of the ARS Big Data Implementation
Plan – Network, HPC, Virtual Research Support
(April, 2014)
• Develop a Science DMZ
• Enable high-speed, low-latency transfer of
research data to HPC and storage from ARS
locations
• Virtual Researcher Support
Implementation Complete (Nov. 2015)
Clay Center, NE; Albany, CA; Beltsville
Labs/Nat’l Ag. Library, Beltsville, MD
Stoneville, MS; Ft. Collins, CO
Ames/NADC, IA
• ARS Scientific Computing
Assessment
• Final Report March 2014](https://image.slidesharecdn.com/237b837b-e9e0-4732-8bc9-3d90953c0b01-160830162408/75/Internet2-Bio-IT-2016-v2-20-2048.jpg)
![Cloud & Distributed Research Computing
@Scale
[ 22 ] Community
Internet2 Approach :
Agile scaling of resources and capacity
Access to multi-domain, multi-discipline expertise in one dynamic global community
Offer a bottomless toolbox for Innovation for the researcher](https://image.slidesharecdn.com/237b837b-e9e0-4732-8bc9-3d90953c0b01-160830162408/75/Internet2-Bio-IT-2016-v2-22-2048.jpg)
![[ 23 ]
New High Speed Cloud Collaborations
8/30/20
16
23
10, x10G, x100G](https://image.slidesharecdn.com/237b837b-e9e0-4732-8bc9-3d90953c0b01-160830162408/75/Internet2-Bio-IT-2016-v2-23-2048.jpg)




![“I want to be 15 minutes behind NCSA and 6
months ahead of my competition”
- Keith Gray, BP
[ 28 ]
National Center for Supercomputing
Applications](https://image.slidesharecdn.com/237b837b-e9e0-4732-8bc9-3d90953c0b01-160830162408/75/Internet2-Bio-IT-2016-v2-28-2048.jpg)
![[ 29 ]
*Better Designed* *More Durable* *Available Sooner*
Theoretical &
Basic Research
Prototyping &
Development
Optimization &
Robustification
Commercialization](https://image.slidesharecdn.com/237b837b-e9e0-4732-8bc9-3d90953c0b01-160830162408/75/Internet2-Bio-IT-2016-v2-29-2048.jpg)
![[ 30 ]
NCSA Mayo Clinic @Scale Genome-Wide
Association Study
for Alzheimer’s disease
• NCSA Private Sector Program
– UIUC HPCBio
– Mayo Clinic
• BlueWatersteam and Swiss Institute of Bioinformatics
worked together to identify which genetic variants
interact to influence gene expression patterns that
may associate with Alzheimer’s disease](https://image.slidesharecdn.com/237b837b-e9e0-4732-8bc9-3d90953c0b01-160830162408/75/Internet2-Bio-IT-2016-v2-30-2048.jpg)
![[ 31 ]
Big Data and Big Compute Problem
• 50,011,495,056 pairs of variants
• Each variant pair is tested against
181 subjects and 24,544 genic regions
• Computationally large problem,
PLINK: ~ 2 years at Mayo FastEpistasis: ~ 6 hours on BlueWaters
• Can be a big data problem:
- 500 PB if keep all results
- 4 TB when using a conservative cutoff](https://image.slidesharecdn.com/237b837b-e9e0-4732-8bc9-3d90953c0b01-160830162408/75/Internet2-Bio-IT-2016-v2-31-2048.jpg)

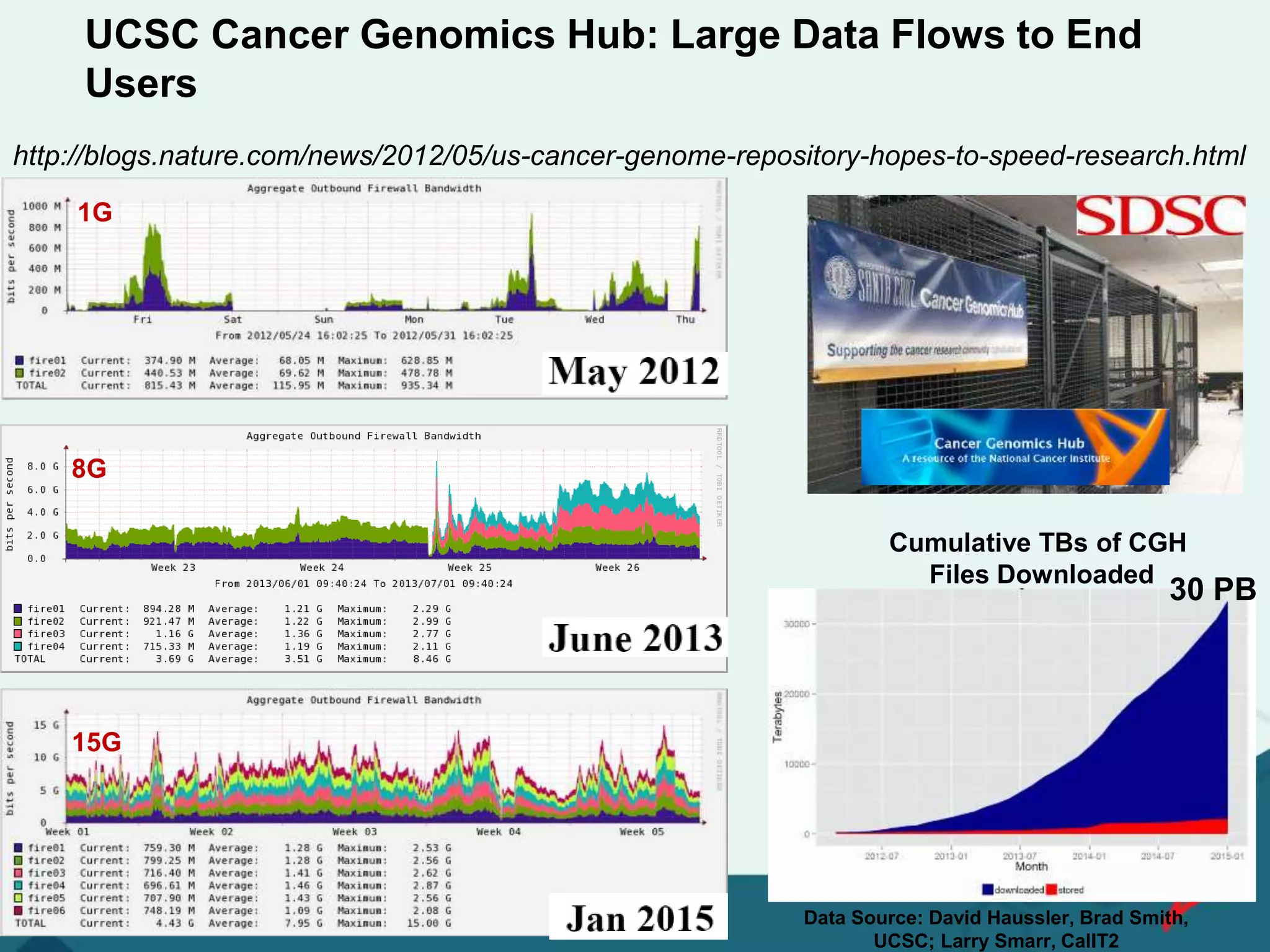
![[ 34 ]
SDSC Protein Data Base Archive
• Repository of atomic coordinates and other information describing proteins and other
important biological macromolecules. Structural biologists use methods such as X-ray
crystallography, NMR spectroscopy, and cryo-electron microscopy to determine
the location of each atom relative to each other in the molecule. Information is
annotated and publicly released into the archive by the wwPDB.](https://image.slidesharecdn.com/237b837b-e9e0-4732-8bc9-3d90953c0b01-160830162408/75/Internet2-Bio-IT-2016-v2-34-2048.jpg)


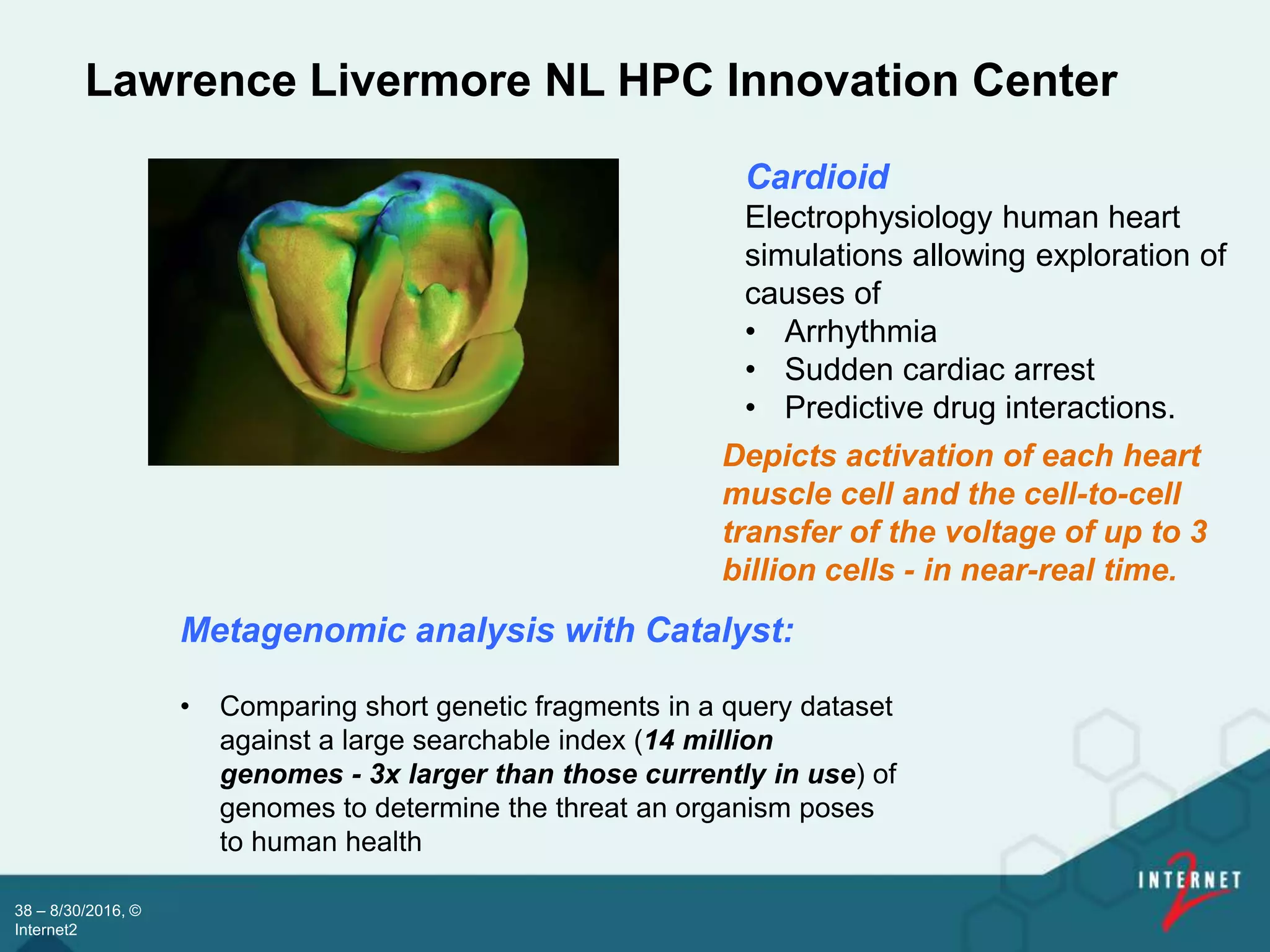
![Lawrence Livermore National Lab
[ 37 ]](https://image.slidesharecdn.com/237b837b-e9e0-4732-8bc9-3d90953c0b01-160830162408/75/Internet2-Bio-IT-2016-v2-37-2048.jpg)
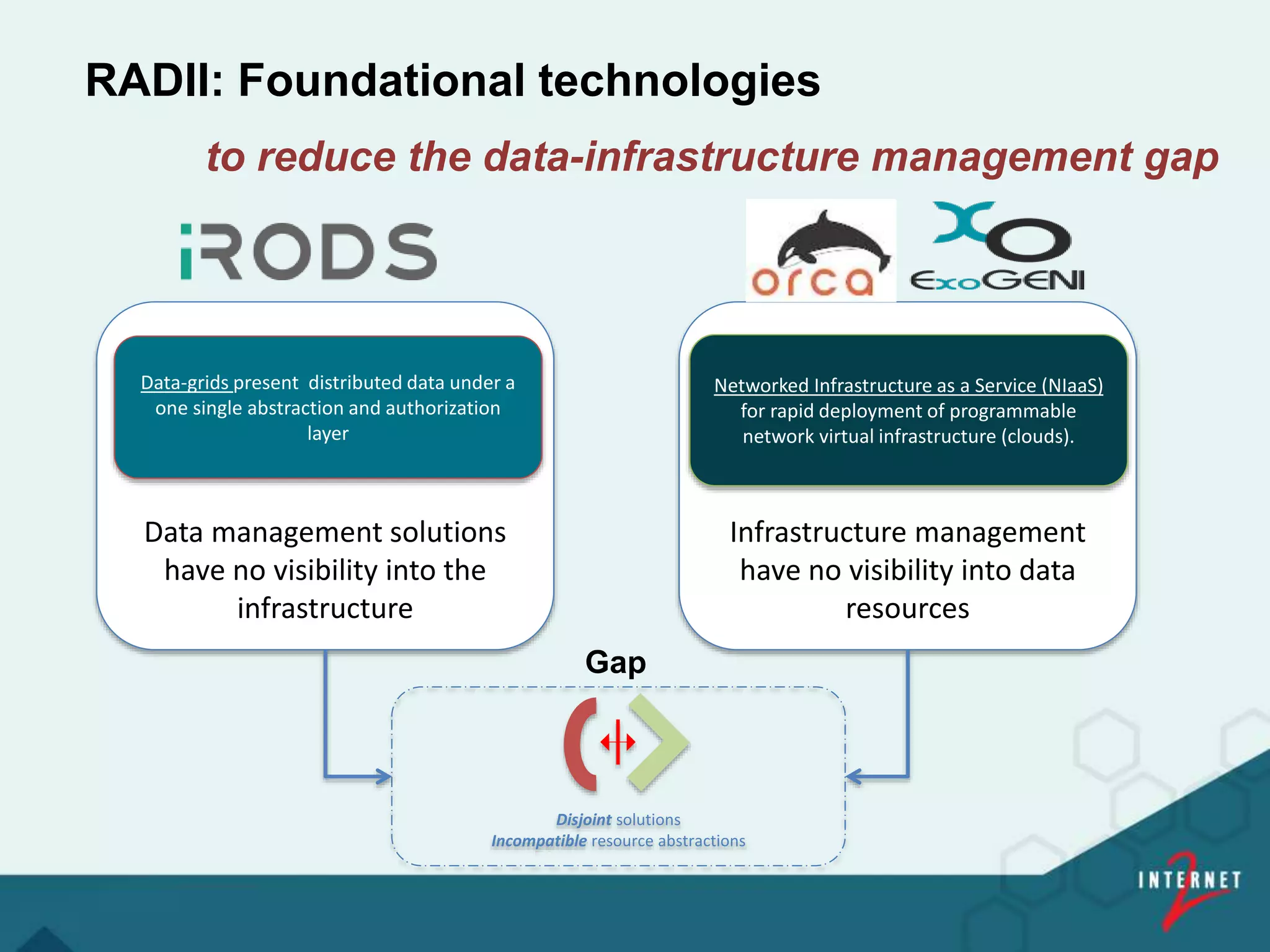
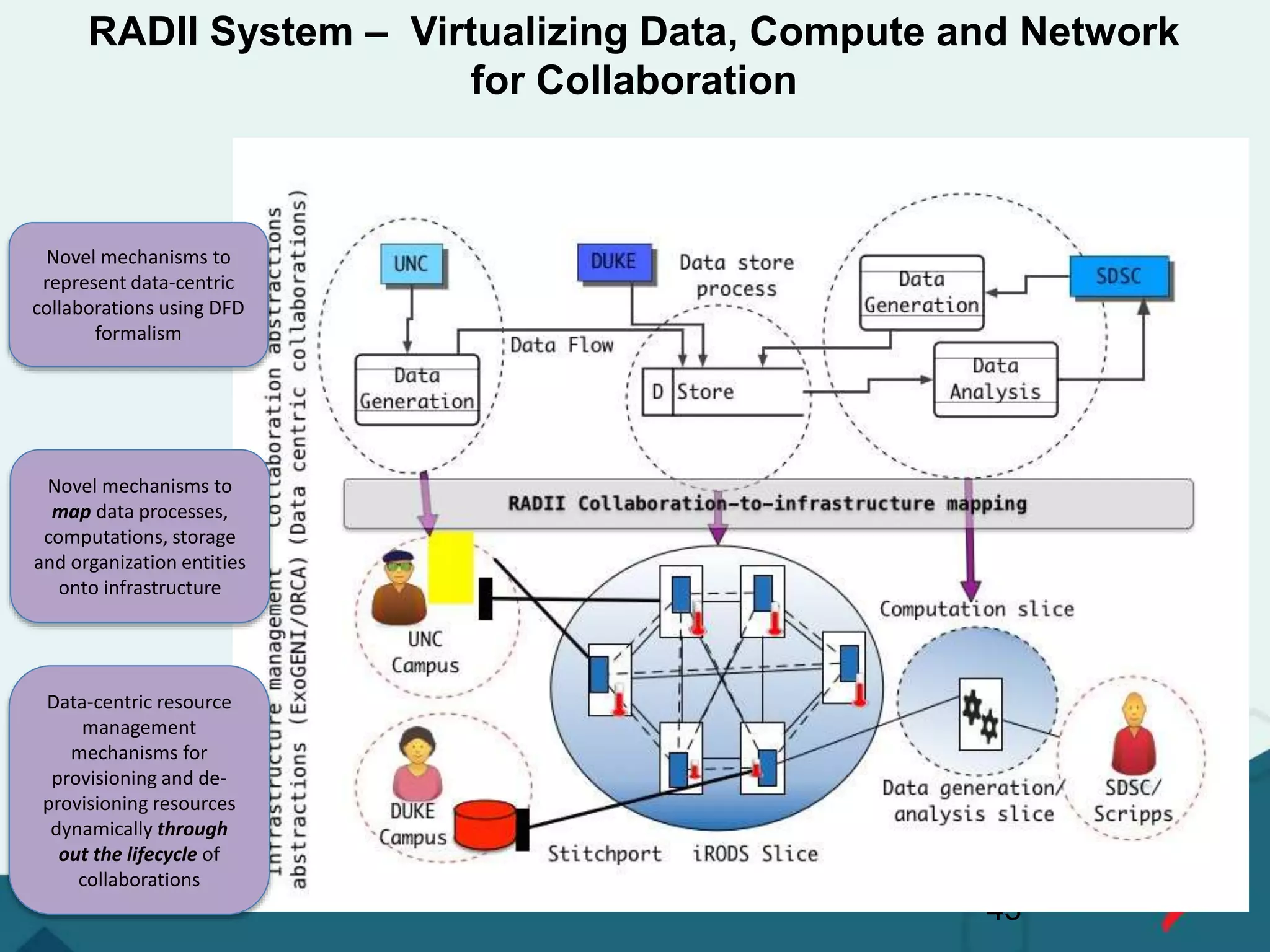
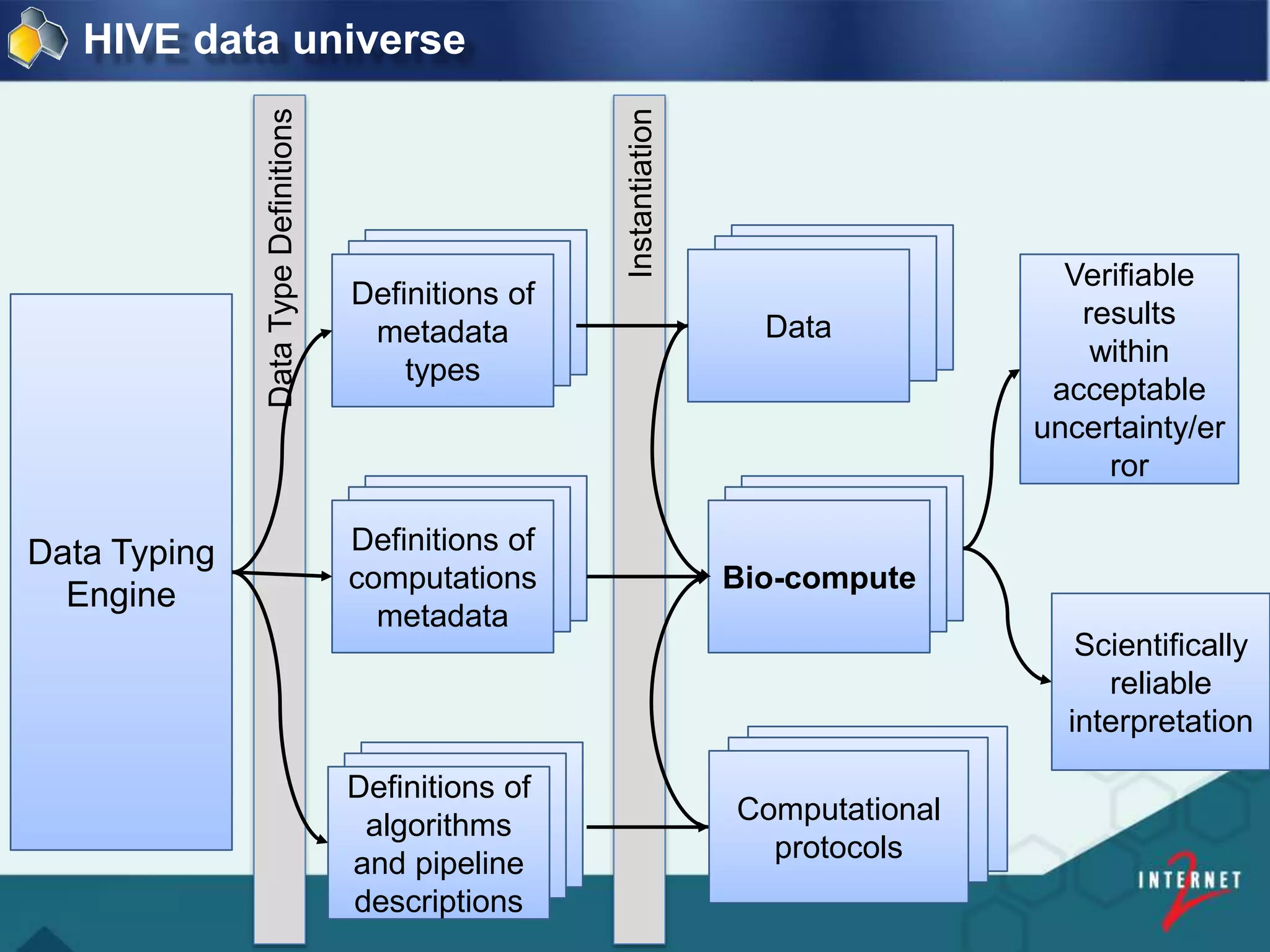
![Community Data Science Resources
renci RADII and GWU HIVE
Driving Infrastructure Virtualization
Enabling Reproducibility For FDA Submissions
[ 39 ]](https://image.slidesharecdn.com/237b837b-e9e0-4732-8bc9-3d90953c0b01-160830162408/75/Internet2-Bio-IT-2016-v2-39-2048.jpg)


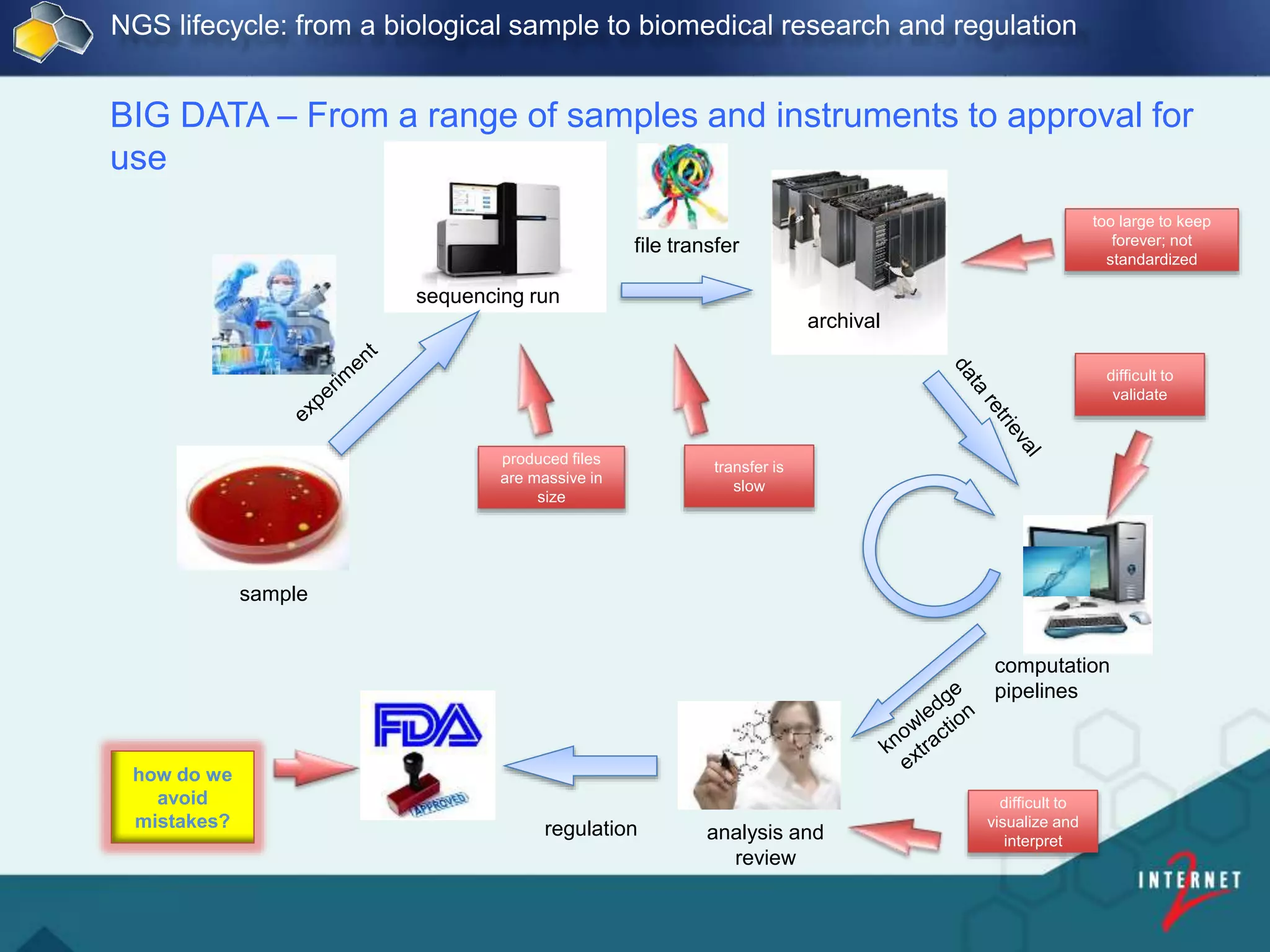
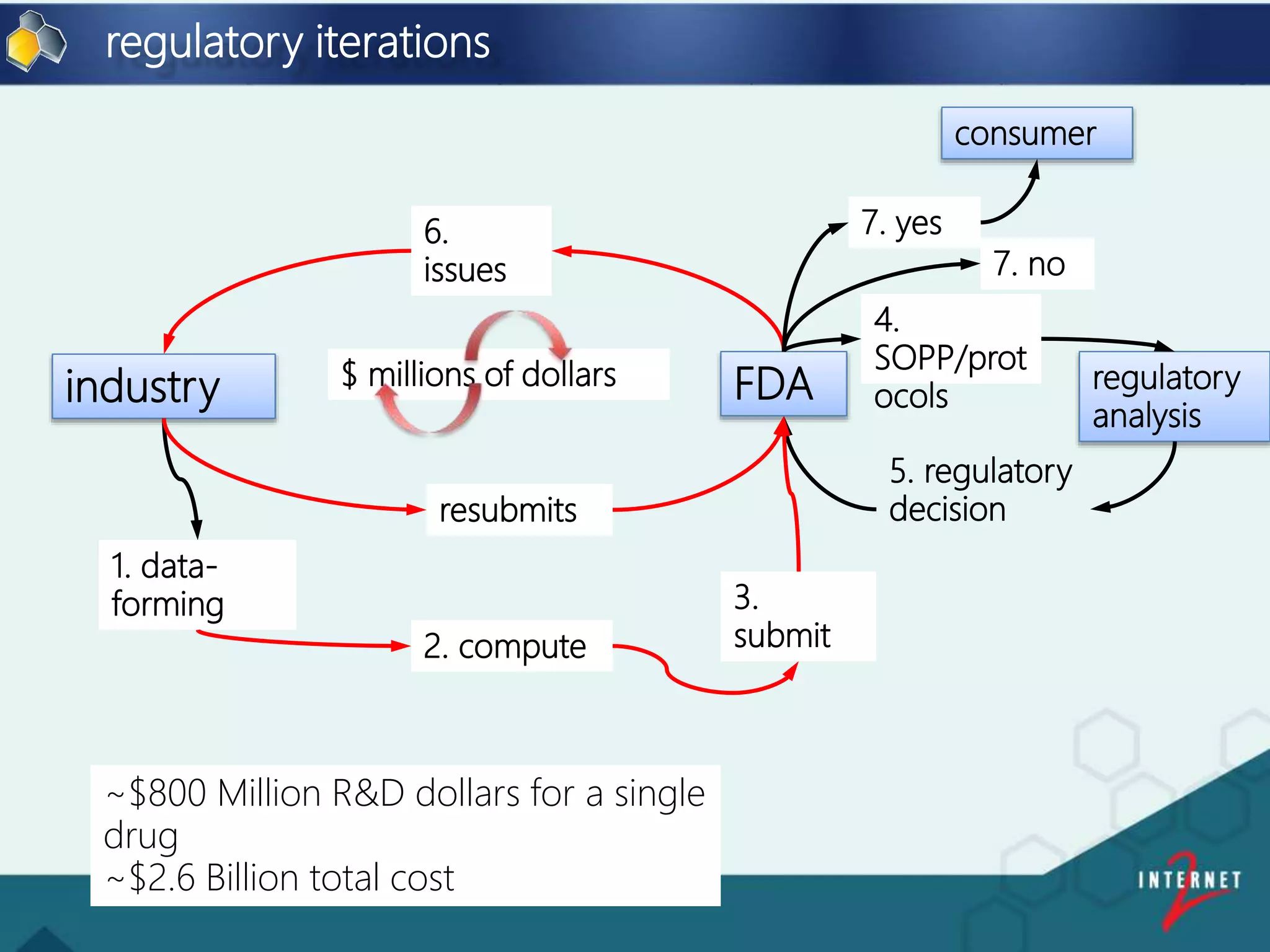
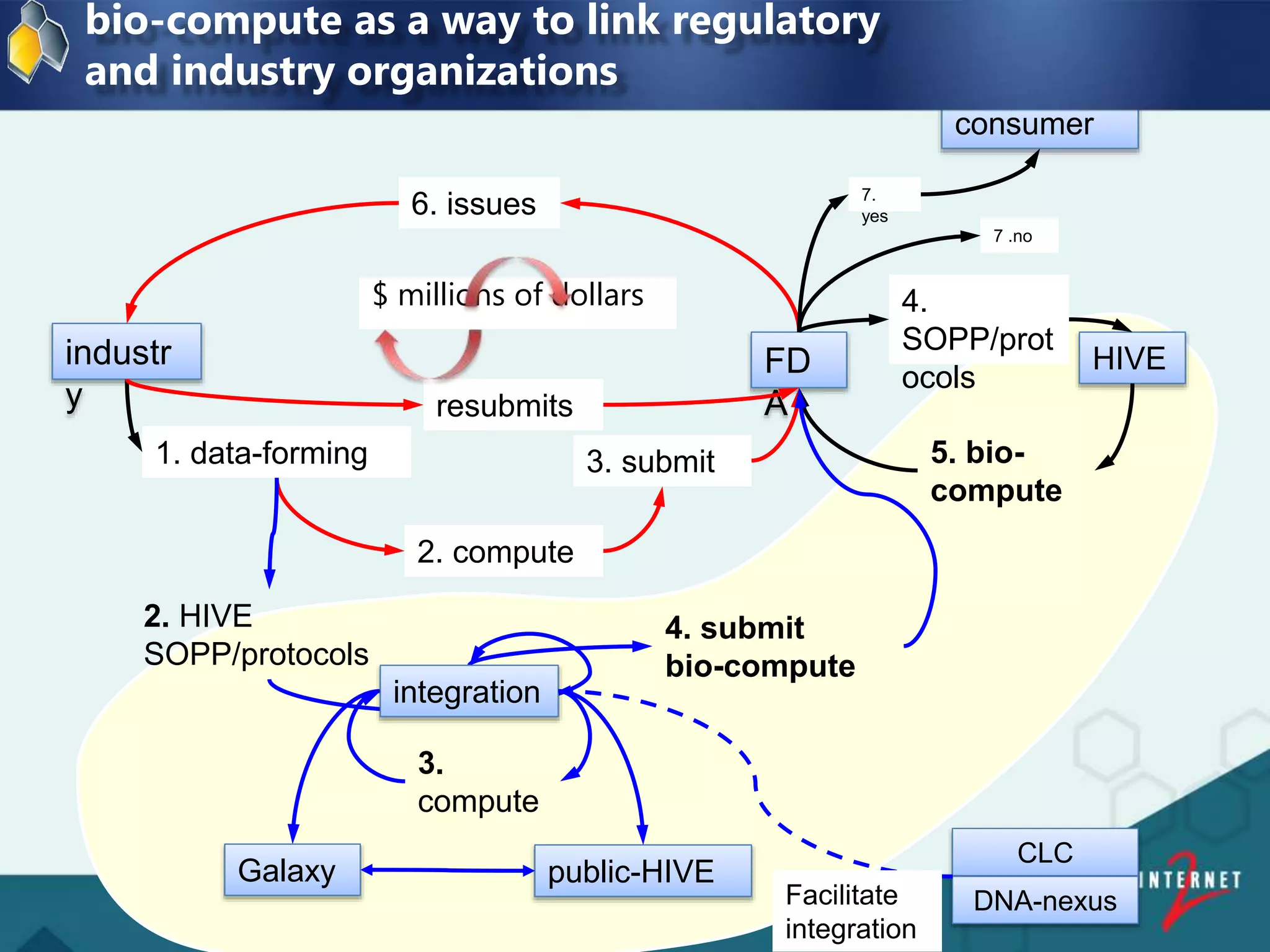
![FDA and George Washington University
Big Data Decisions:
Linking Regulatory and Industry
Organizations with
HIVE Bio-Compute Objects
[ 44 ]
Presented by: Dan Taylor, Internet 2 | Bio IT | Boston | 2016](https://image.slidesharecdn.com/237b837b-e9e0-4732-8bc9-3d90953c0b01-160830162408/75/Internet2-Bio-IT-2016-v2-44-2048.jpg)



![Federated Identity
[ 52 ]](https://image.slidesharecdn.com/237b837b-e9e0-4732-8bc9-3d90953c0b01-160830162408/75/Internet2-Bio-IT-2016-v2-52-2048.jpg)
![[ 53 ]
Community-developed framework of
trust enables:
• Secure, streamlined sharing of
protected resources
• Consolidated management of user
identities and access
• Delivery of an integrated portfolio of
community-developed solutions
[ 53 ]
Trusted Identity in Research
The standard for over
600 higher education
institutions—and
counting!](https://image.slidesharecdn.com/237b837b-e9e0-4732-8bc9-3d90953c0b01-160830162408/75/Internet2-Bio-IT-2016-v2-53-2048.jpg)
![[ 54 ]
15 425+
2 160+
0 2000+
7.8 million
Academic
Participants
Sponsored
Partners
Registered
Service Providers
Individuals served
by federated IdM
Foundation for Trust & Identity
54
®](https://image.slidesharecdn.com/237b837b-e9e0-4732-8bc9-3d90953c0b01-160830162408/75/Internet2-Bio-IT-2016-v2-54-2048.jpg)
![• Eric Boyd, Internet2
• Stephen Wolff, Internet2
• Stephen Goff, PhD, CyVERSE/iPlant, University of Arizona
• Chris Dagdigian, BioTeam
• Daiwei Lin, PhD, NIAID, NIH
• Paul Gibson, USDA ARS
• Paul Travis, Syngenta
• Evan Burness, NCSA
• Sandeep Chandra, SDSC
• Jonathan Allen, PhD, Lawrence Livermore National Lab
• Claris Castillo, PhD, RENCI
• Vahan Simonyan, PhD, FDA
• Raja Mazumder, PhD, George Washington University
• Eli Dart, ESNET, US Department of Energy
• BGI
• Nature
[ 55 ]
Acknowledgements](https://image.slidesharecdn.com/237b837b-e9e0-4732-8bc9-3d90953c0b01-160830162408/75/Internet2-Bio-IT-2016-v2-55-2048.jpg)

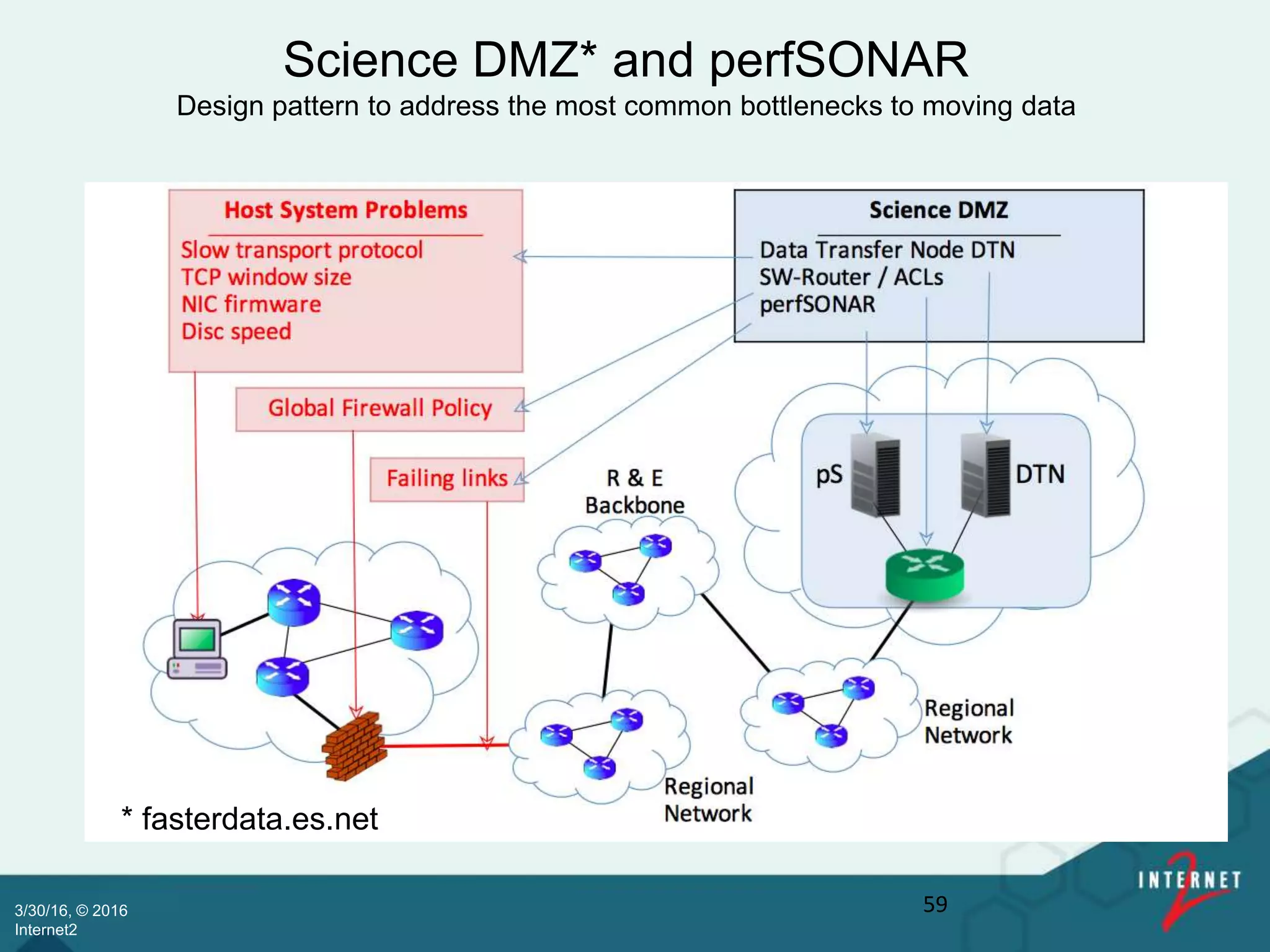
![Back up slides
Science DMZ
[ 57 ]](https://image.slidesharecdn.com/237b837b-e9e0-4732-8bc9-3d90953c0b01-160830162408/75/Internet2-Bio-IT-2016-v2-57-2048.jpg)
![[ 58 ]
Rising expectations
Network throughput required to move y bytes in x time.
(US Dept of Energy - http://fasterdata.es.net).
should
be easy
This
year](https://image.slidesharecdn.com/237b837b-e9e0-4732-8bc9-3d90953c0b01-160830162408/75/Internet2-Bio-IT-2016-v2-58-2048.jpg)

The document discusses Internet2, an advanced networking consortium that operates a 15,000 mile fiber optic network for research and education. It provides very high speed connectivity and collaboration technologies to facilitate large data sharing and frictionless research. Examples are given of life sciences projects utilizing Internet2's high-speed network for genomic research and agricultural applications involving terabytes of satellite and sensor data. The network is expanding to include cloud computing resources and supercomputing centers to enable global-scale distributed scientific computing and collaboration.



































































