How to setuphadoop
아꿈사
Cecil
(hyeonseok.c.choi@gmail.com)
13년 8월 16일 금요일
2.
Hadoop의 기본 구성
•Hadoop Common(Core)
• 다른 Hadoop 모듈을 위한 기본 유틸리티
• HDFS(Hadoop File System)
• 대용량 데이터 저장을 위한 분산 파일 시스템
• YARN (2.0 이상 버전)
• 잡 스케쥴링 및 클러스터 리소스 관리를 위한 프레임워크
• Map Reduce
• 대용량 데이터를 병렬로 처리하는 모듈(YARN 기반)
• But, 각각을 설치하는 것이 아니라 기본 배포판에 모두 포함되어 있음.
13년 8월 16일 금요일
3.
설치를 위한 기본준비
• JDK (Java Development Kit)
• 1.6 버전 이상 필요
• Java SE Development Kit 6u45 사용
• URL: http://www.oracle.com/technetwork/java/
javasebusiness/downloads/java-archive-downloads-
javase6-419409.html#jdk-6u45-oth-JPR
• Hadoop 배포 버전
• Hadoop Release 1.2.1 (last stable version)
• URL: http://mirror.apache-kr.org/hadoop/common/
hadoop-1.2.1/
13년 8월 16일 금요일
4.
설치
• JDK (JavaDevelopment Kit)
• Linux
• rpm 파일을 이용하여 설치: rpm -Uvm jdk-xxxx-bin.rpm
• 기본 설치 경로: /usr/java/jdk-버전
• Mac
• 기본적으로 설치되어 있음, 없을 경우 콘솔에서 javac 입력시 자동으로 설치됨
• 설치 경로: /System/Library/Frameworks/JavaVM.framework/Versions/버전/Home
• 기본 설치 경로를 JAVA_HOME으로 설정
• Hadoop 배포 버전
• Hadoop Release 1.2.1 (last stable version)
• URL: http://mirror.apache-kr.org/hadoop/common/hadoop-1.2.1/hadoop-1.2.1-bin.tar.gz
• tar -xvzf hadoop-1.2.1-bin.tar.gz
13년 8월 16일 금요일
5.
환경 설정
• JAVA_HOME
•사용자 환경 변수로 설정
• export JAVA_HOME=<jdk 설치 경로>
• hadoop-env.sh 수정
• <하둡 설치 경로>/conf/hadoop-env.sh의 JAVA_HOME 경로를 수정
• HADOOP_INSTALL
• export HADOOP_INSTALL=<하둡 설치 경로>
• PATH
• export PATH=$PATH:$HADOOP_INSTALL/bin:HADOOP_INSTALL/sbin
• 설치 확인
• > hadoop version
13년 8월 16일 금요일
6.
Hadoop 실행 모드
•독립 실행 모드(Standalone)
• 모든 것이 하나의 JVM 내에서 동작, 별도의 프로세스 기동 없음.
• 개발하는 동안 맵리듀스 프로그램을 실행하기에 적합, 테스트와 디버깅이 쉬움
• 별도의 설정이 필요 없음
• 의사 분산 모드(Pseudo-distributed mode)
• 하둡 데몬 프로세스가 로컬 컴퓨터에서 동작.
• 작은 규모의 클러스터를 시뮬레이션 가능
• 완전 분산 모드(Fully distributed mode)
• 실제 Production 환경
• 하둡 데몬 프로세스는 다수 컴퓨터로 구성된 그룹 상에서 동작.
13년 8월 16일 금요일
7.
Hadoop 설정 파일
•<하둡 설치 디렉토리>/conf에 위치
• hadoop-evn.sh
• 하둡을 구동하는 스크립트에서 사용하는 환경 변수(JAVA_HOME 등..)
• core-site.xml
• HDFS와 Map-Reduce에서 공통적으로 사용되는 IO 설정 같은 하둡 코어를 위한 환경 설정
• hdfs-site.xml
• HDFS 데몬을 위한 환경 설정(네임노드, 보조 네임노드, 데이터 노드 등..)
• mapred-site.xml
• 맵 리듀스 데몬의 위한 환경 설정(잡 트래커, 태스크 트래커 등..)
• masters
• 보조 네임 노드를 구동 시킬 컴퓨터의 목록 (라인당 하나의 장비)
• 기본값: localhost (완전 분산 모드시 변경 필요)
• slaves
• 데이터 노드와 태스크 트래커를 구동시킬 컴퓨터 목록 (라인당 하나의 노드 장비)
• 기본값: localhost (완전 분산 모드시 변경 필요)
13년 8월 16일 금요일
P.105 예제 3-3[1]
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class FileSystemDoubleCat {
public static void main(String [] args) throws IOException {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
FSDataInputStream in = null;
try {
in = fs.open(new Path(uri));
IOUtils.copyBytes(in, System.out, 4096, false);
in.seek(0);
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
}
13년 8월 16일 금요일
11.
Compile
hadoop-core-1.1.2.jar 를 classpath에 추가
Compile Command
javac -cp ~/tools/hadoop-1.1.2/hadoop-core-1.1.2.jar
-d ../bin/ com/cecil/ch3/FileSystemDoubleCat.java
Javac option
-cp: class path 지정
-d: 컴파일 후 생성될 class file 경로
13년 8월 16일 금요일
12.
Execution
Why?
자바는 일반적으로 “java”명령어를 사용하여 실행
Hadoop을 실행하기 위해서는 필요한 환경을 설정해야하며
“hadoop” 명령어에 해당 스크립트가 포함되어 있음.
1. HADOOP_CLASSPATH에 생성된 class의 경로를 지정
2.“hadoop” 명령을 사용해서 실행
13년 8월 16일 금요일
13.
Execution command
export HADOOP_CLASSPATH=<생성된class file 경로>
hadoop <main class 명> <input file>
choiui-MacBook:bin hyeonseok$ export HADOOP_CLASSPATH=.
choiui-MacBook:bin hyeonseok$ hadoop com.cecil.ch3.FileSystemDoubleCat input.txt
2013-08-15 16:12:53.711 java[932:1203] Unable to load realm info from SCDynamicStore
hadoop test
hadoop test
bin 디렉토리 내에서 실행한 결과bin
bin/com
bin/com/cecil
bin/com/cecil/ch3
bin/com/cecil/ch3/FileSystemDoubleCat.class
bin/input.txt
src
src/com
src/com/cecil
src/com/cecil/ch3
src/com/cecil/ch3/FileSystemDoubleCat.java
디렉토리 구조
13년 8월 16일 금요일
14.
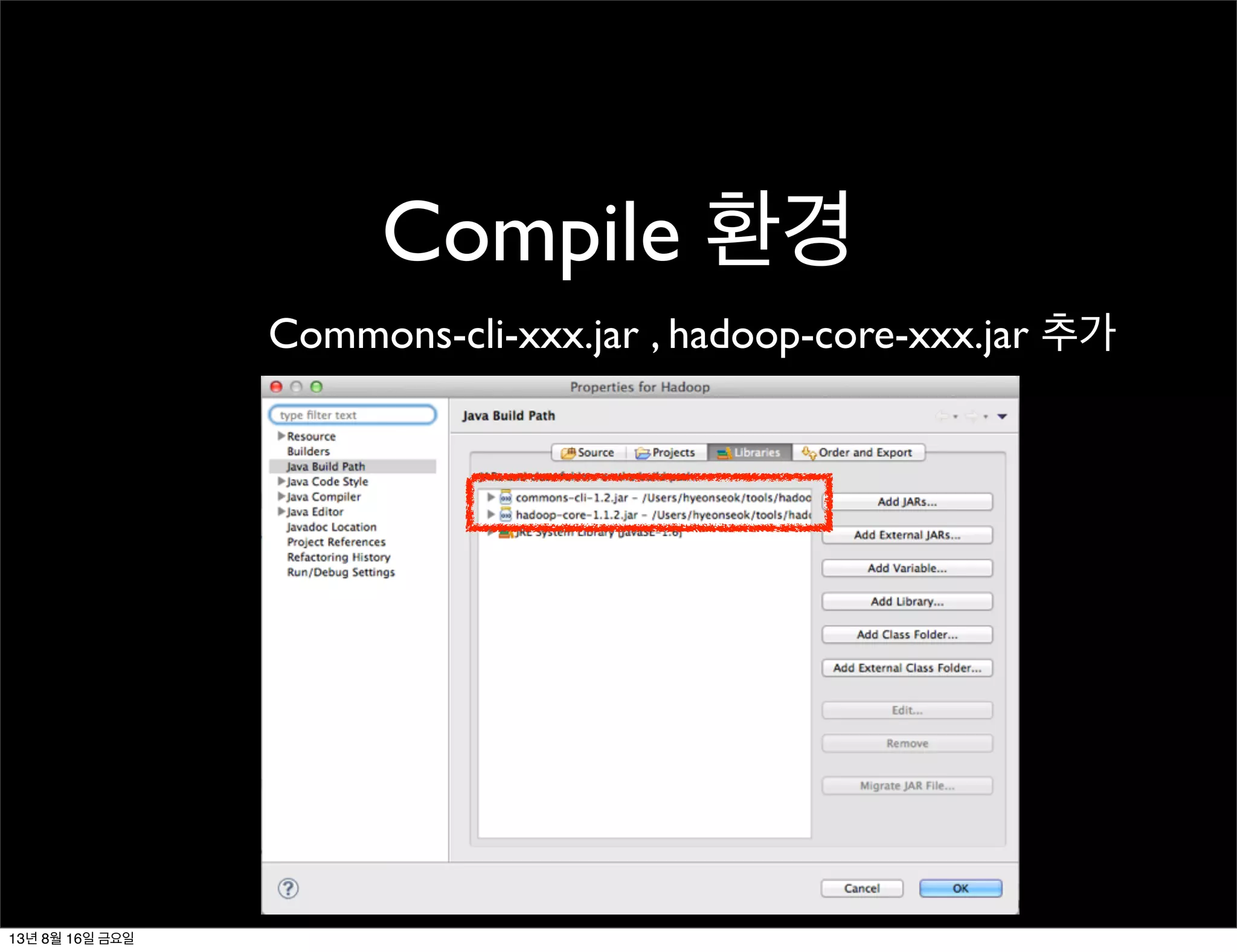
Compile in EclipseIDE
해당 project의 build path에 hadoop-core-xxx.jar 추가
13년 8월 16일 금요일
Hadoop 실행
1. 환경설정 파일 수정
• core-site.xml: 공통 설정 파일
• hdfs-site.xml: hdfs 설정 파일
• mapred-site.xml: map-reduce 설정파일
2. ssh 설정
• hadoop 시작 스크립트 실행시 data node 장비로 접속하여
스크립트를 실행(ssh 사용)
• 즉, start 스크립트 실행 측에서 다른 곳으로 ssh 접속이 필요
3. HDFS 파일 시스템 포멧
4. 데몬 프로세스 실행
13년 8월 16일 금요일
17.
환경 설정 파일수정
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost/</value> <!-- Pseudo-distributed -->
</property>
</configuration>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value> <!-- replication number -->
</property>
</configuration>
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:8025</value>
</property>
</configuration>
core-site.xml
hdfs-site.xml mapred-site.xml
13년 8월 16일 금요일
18.
ssh 설정
choiui-MacBook:hadoop-1.1.2 hyeonseok$ssh-keygen -t rsa <= ssh key 생성
Generating public/private rsa key pair.
Enter file in which to save the key (/Users/hyeonseok/.ssh/id_rsa): <= Enter: 기본값
/Users/hyeonseok/.ssh/id_rsa already exists.
Overwrite (y/n)? y
Enter passphrase (empty for no passphrase): <= Enter만 입력: 암호 미설정
Enter same passphrase again: <= Enter만 입력: 암호 확인
Your identification has been saved in /Users/hyeonseok/.ssh/id_rsa.
Your public key has been saved in /Users/hyeonseok/.ssh/id_rsa.pub.
The key fingerprint is:
05:75:6f:6b:72:b8:69:33:a7:7b:ba:17:9e:64:e0:3a hyeonseok@choiui-MacBook.local
The key's randomart image is:
+--[ RSA 2048]----+
| ... . |
| . . . |
| . o |
| . .o . |
| S .o.+ |
| .*+ |
| .*+.o |
| E. == |
| .=* |
+---------------------+
choiui-MacBook:hadoop-1.1.2 hyeonseok$ cat /User/hyeonseok/.ssh/id_rsa.pub >> ~/.ssh/authrized_keys <= 접속 허용 목록에 추가
ssh key file 생성
- Command를 실행 할 곳에서 key file을 생성하고, 모든 장비로 복사 (접속 계정에 주의)
ssh 접속 Test
choiui-MacBook:hadoop-1.1.2 hyeonseok$ ssh hyeonseok@localhost
Last login:Thu Aug 15 18:07:55 2013
choiui-MacBook:~ hyeonseok$
13년 8월 16일 금요일
19.
파일 시스템 format
choiui-MacBook:~hyeonseok$ hadoop namenode -format <= 파일 시스템 포멧
13/08/15 23:48:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = choiui-MacBook.local/192.168.100.5
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 1.1.2
STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.1 -r 1440782; compiled by 'hortonfo' on Thu Jan 31 02:03:24 UTC 2013
************************************************************/
13/08/15 23:48:55 INFO util.GSet:VM type = 64-bit
13/08/15 23:48:55 INFO util.GSet: 2% max memory = 19.9175 MB
13/08/15 23:48:55 INFO util.GSet: capacity = 2^21 = 2097152 entries
13/08/15 23:48:55 INFO util.GSet: recommended=2097152, actual=2097152
2013-08-15 23:48:55.787 java[6120:1603] Unable to load realm info from SCDynamicStore
13/08/15 23:48:56 INFO namenode.FSNamesystem: fsOwner=hyeonseok
13/08/15 23:48:56 INFO namenode.FSNamesystem: supergroup=supergroup
13/08/15 23:48:56 INFO namenode.FSNamesystem: isPermissionEnabled=true
13/08/15 23:48:56 INFO namenode.FSNamesystem: dfs.block.invalidate.limit=100
13/08/15 23:48:56 INFO namenode.FSNamesystem: isAccessTokenEnabled=false accessKeyUpdateInterval=0 min(s), accessTokenLifetime=0 min(s)
13/08/15 23:48:56 INFO namenode.NameNode: Caching file names occuring more than 10 times
13/08/15 23:48:56 INFO common.Storage: Image file of size 115 saved in 0 seconds.
13/08/15 23:48:56 INFO namenode.FSEditLog: closing edit log: position=4, editlog=/tmp/hadoop-hyeonseok/dfs/name/current/edits
13/08/15 23:48:56 INFO namenode.FSEditLog: close success: truncate to 4, editlog=/tmp/hadoop-hyeonseok/dfs/name/current/edits
13/08/15 23:48:56 INFO common.Storage: Storage directory /tmp/hadoop-hyeonseok/dfs/name has been successfully formatted.
13/08/15 23:48:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at choiui-MacBook.local/192.168.100.5
13년 8월 16일 금요일
20.
데몬 프로세스 실행& 중지
choiui-MacBook:~ hyeonseok$ start-all.sh <= 데몬 프로세스 실행
starting namenode, logging to /Users/hyeonseok/tools/hadoop-1.1.2/libexec/../logs/hadoop-hyeonseok-namenode-choiui-MacBook.local.out
localhost: starting datanode, logging to /Users/hyeonseok/tools/hadoop-1.1.2/libexec/../logs/hadoop-hyeonseok-datanode-choiui-MacBook.local.out
localhost: starting secondarynamenode, logging to /Users/hyeonseok/tools/hadoop-1.1.2/libexec/../logs/hadoop-hyeonseok-secondarynamenode-choiui-MacBook.local.out
starting jobtracker, logging to /Users/hyeonseok/tools/hadoop-1.1.2/libexec/../logs/hadoop-hyeonseok-jobtracker-choiui-MacBook.local.out
localhost: starting tasktracker, logging to /Users/hyeonseok/tools/hadoop-1.1.2/libexec/../logs/hadoop-hyeonseok-tasktracker-choiui-MacBook.local.out
choiui-MacBook:~ hyeonseok$ jps -l <= 데몬 프로세스 확인
6281 org.apache.hadoop.hdfs.server.datanode.DataNode
6195 org.apache.hadoop.hdfs.server.namenode.NameNode
6366 org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode
6543 sun.tools.jps.Jps
6514 org.apache.hadoop.mapred.TaskTracker
173
6428 org.apache.hadoop.mapred.JobTracker
choiui-MacBook:~ hyeonseok$ stop-all.sh <= 데몬 프로세스 중지
stopping jobtracker
localhost: stopping tasktracker
stopping namenode
localhost: stopping datanode
localhost: stopping secondarynamenode
13년 8월 16일 금요일
21.
P.105 예제 3-3실행 [1]
choiui-MacBook:bin hyeonseok$ hadoop fs -ls / <= hdfs / 디렉토리 확인
2013-08-15 23:56:31.878 java[7231:1603] Unable to load realm info from SCDynamicStore
Found 1 items
drwxr-xr-x - hyeonseok supergroup 0 2013-08-15 23:49 /tmp
choiui-MacBook:bin hyeonseok$ hadoop fs -copyFromLocal input.txt /tmp/ <= input.txt를 hdfs로 copy
2013-08-15 23:57:19.739 java[7250:1603] Unable to load realm info from SCDynamicStore
choiui-MacBook:bin hyeonseok$ hadoop fs -ls /tmp <= copy 확인
2013-08-15 23:57:33.085 java[7288:1603] Unable to load realm info from SCDynamicStore
Found 2 items
drwxr-xr-x - hyeonseok supergroup 0 2013-08-15 23:49 /tmp/hadoop-hyeonseok
-rw-r--r-- 1 hyeonseok supergroup 12 2013-08-15 23:57 /tmp/input.txt <= hadoop classpath 확인
choiui-MacBook:bin hyeonseok$ echo $HADOOP_CLASSPATH
.
choiui-MacBook:bin hyeonseok$ hadoop com.cecil.ch3.FileSystemDoubleCat /tmp/input.txt <= DoubleCat 실행
2013-08-15 23:59:20.133 java[7329:1603] Unable to load realm info from SCDynamicStore
hadoop test
hadoop test
./com
./com/cecil
./com/cecil/ch3
./com/cecil/ch3/FileSystemDoubleCat.class
./input.txt
Local 디렉토리 구조
hdfs의 input.txt 파일을 사용하여 실행
13년 8월 16일 금요일
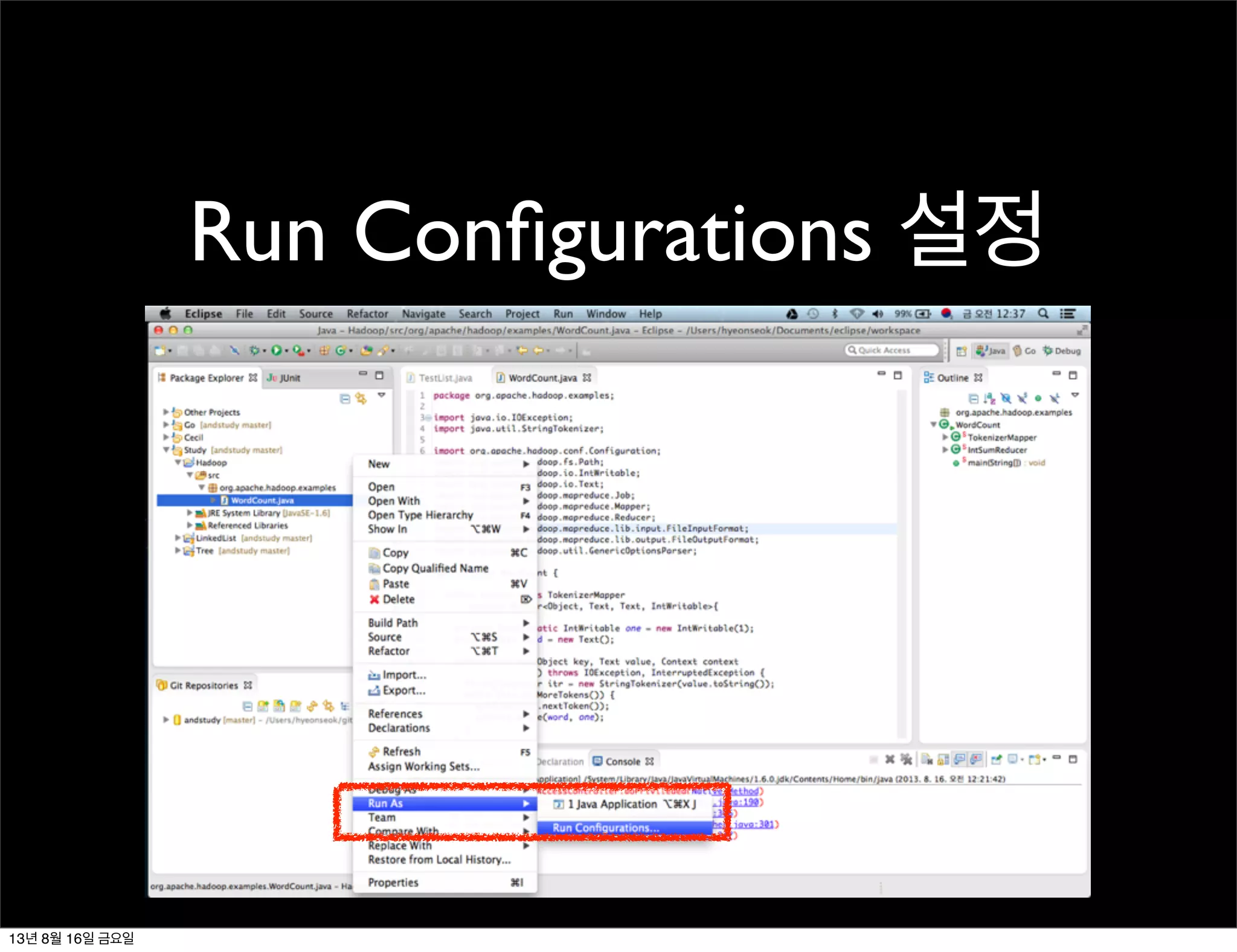
WordCount.java
1. 실행 환경
•소스: <hadoop>/src/example.WordCount.java
• 컴파일 및 jar 생성: eclipse
2. 실행 과정
• map-reduce 소스 작성
• jar 파일 생성
•map-reduce job은 분산된 노드에서 실행되어야
하기 때문에 jar 파일이 필요함
• map-reduce 실행
13년 8월 16일 금요일
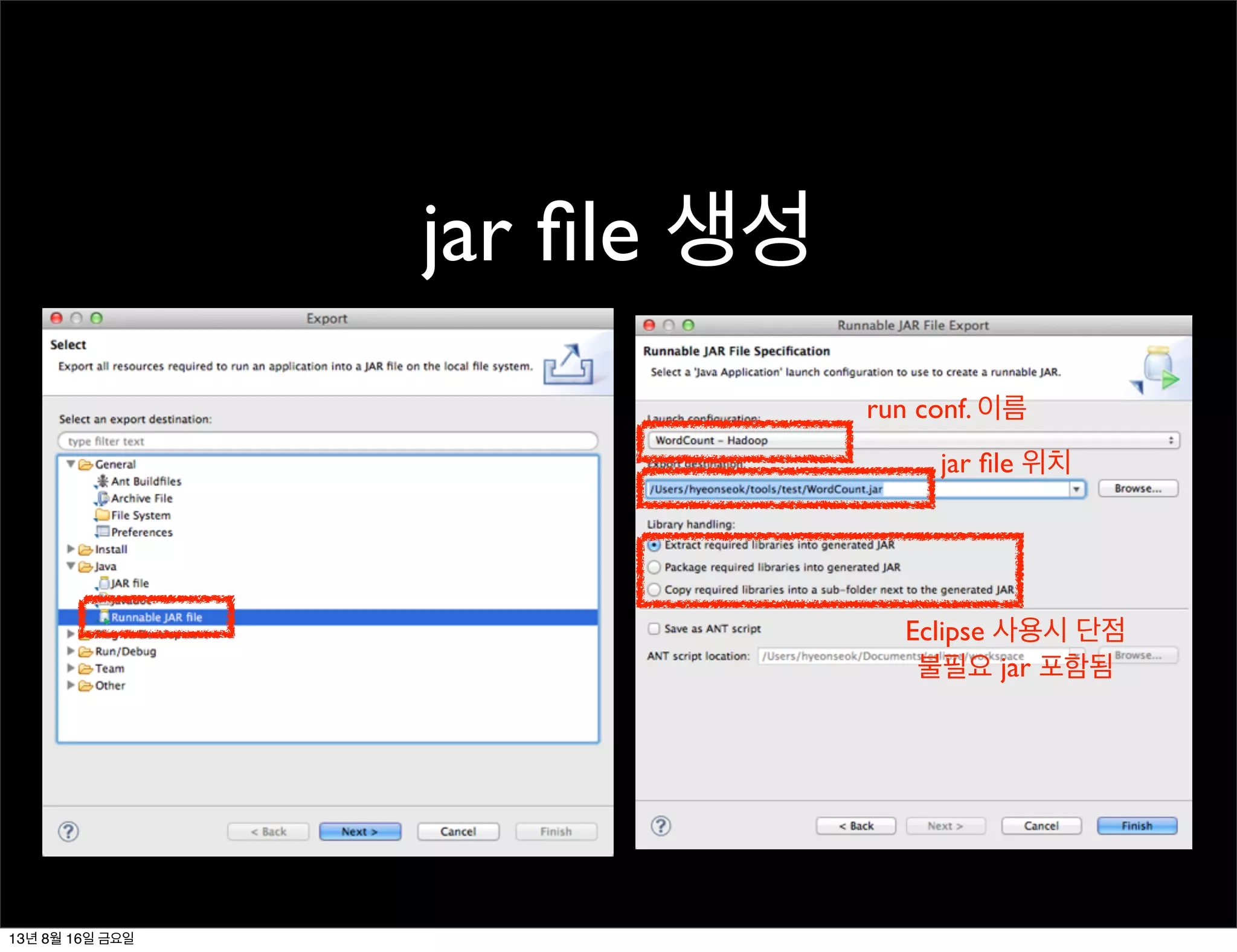
jar file 생성
runconf. 이름
jar file 위치
Eclipse 사용시 단점
불필요 jar 포함됨
13년 8월 16일 금요일
29.
실행
choiui-MacBook:test hyeonseok$ hadoopjar WordCount.jar /tmp/input.txt /tmp/out <= WordCount 실행
2013-08-16 00:24:33.064 java[7550:1603] Unable to load realm info from SCDynamicStore
13/08/16 00:24:34 INFO input.FileInputFormat:Total input paths to process : 1
13/08/16 00:24:34 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
13/08/16 00:24:34 WARN snappy.LoadSnappy: Snappy native library not loaded
13/08/16 00:24:35 INFO mapred.JobClient: Running job: job_201308152355_0001
13/08/16 00:24:36 INFO mapred.JobClient: map 0% reduce 0%
13/08/16 00:24:45 INFO mapred.JobClient: map 100% reduce 0%
13/08/16 00:24:53 INFO mapred.JobClient: map 100% reduce 33%
13/08/16 00:24:55 INFO mapred.JobClient: map 100% reduce 100%
:
13/08/16 00:24:56 INFO mapred.JobClient: Map output records=2
choiui-MacBook:test hyeonseok$
choiui-MacBook:test hyeonseok$ hadoop fs -ls /tmp/out <= 실행 결과 생성된 파일들
2013-08-16 00:25:30.600 java[7640:1603] Unable to load realm info from SCDynamicStore
Found 3 items
-rw-r--r-- 1 hyeonseok supergroup 0 2013-08-16 00:24 /tmp/out/_SUCCESS
drwxr-xr-x - hyeonseok supergroup 0 2013-08-16 00:24 /tmp/out/_logs
-rw-r--r-- 1 hyeonseok supergroup 16 2013-08-16 00:24 /tmp/out/part-r-00000
choiui-MacBook:test hyeonseok$ fs -ls /tmp/out/part-r-00000
-bash: fs: command not found
choiui-MacBook:test hyeonseok$ hadoop fs -cat /tmp/out/part-r-00000 <= 결과 확인
2013-08-16 00:25:57.141 java[7661:1603] Unable to load realm info from SCDynamicStore
hadoop
1
test
1
map-reduce 작업 시 input과 output을 명시
- output은 존재하지 않는 디렉토리여야 함. 존재할 경우 실패.
13년 8월 16일 금요일
30.
References
1. Tom White(2013). 하둡 완벽가이드. (심탁
길, 김현우, 옮김). 서울: 한빛미디어. (원서출판
2012)
13년 8월 16일 금요일










![P.105 예제 3-3 [1]
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class FileSystemDoubleCat {
public static void main(String [] args) throws IOException {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
FSDataInputStream in = null;
try {
in = fs.open(new Path(uri));
IOUtils.copyBytes(in, System.out, 4096, false);
in.seek(0);
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
}
13년 8월 16일 금요일](https://image.slidesharecdn.com/hwotosetuphadoop-130815110606-phpapp01/75/Java-hadoop-10-2048.jpg)


![Execution command
export HADOOP_CLASSPATH=<생성된 class file 경로>
hadoop <main class 명> <input file>
choiui-MacBook:bin hyeonseok$ export HADOOP_CLASSPATH=.
choiui-MacBook:bin hyeonseok$ hadoop com.cecil.ch3.FileSystemDoubleCat input.txt
2013-08-15 16:12:53.711 java[932:1203] Unable to load realm info from SCDynamicStore
hadoop test
hadoop test
bin 디렉토리 내에서 실행한 결과bin
bin/com
bin/com/cecil
bin/com/cecil/ch3
bin/com/cecil/ch3/FileSystemDoubleCat.class
bin/input.txt
src
src/com
src/com/cecil
src/com/cecil/ch3
src/com/cecil/ch3/FileSystemDoubleCat.java
디렉토리 구조
13년 8월 16일 금요일](https://image.slidesharecdn.com/hwotosetuphadoop-130815110606-phpapp01/75/Java-hadoop-13-2048.jpg)




![ssh 설정
choiui-MacBook:hadoop-1.1.2 hyeonseok$ ssh-keygen -t rsa <= ssh key 생성
Generating public/private rsa key pair.
Enter file in which to save the key (/Users/hyeonseok/.ssh/id_rsa): <= Enter: 기본값
/Users/hyeonseok/.ssh/id_rsa already exists.
Overwrite (y/n)? y
Enter passphrase (empty for no passphrase): <= Enter만 입력: 암호 미설정
Enter same passphrase again: <= Enter만 입력: 암호 확인
Your identification has been saved in /Users/hyeonseok/.ssh/id_rsa.
Your public key has been saved in /Users/hyeonseok/.ssh/id_rsa.pub.
The key fingerprint is:
05:75:6f:6b:72:b8:69:33:a7:7b:ba:17:9e:64:e0:3a hyeonseok@choiui-MacBook.local
The key's randomart image is:
+--[ RSA 2048]----+
| ... . |
| . . . |
| . o |
| . .o . |
| S .o.+ |
| .*+ |
| .*+.o |
| E. == |
| .=* |
+---------------------+
choiui-MacBook:hadoop-1.1.2 hyeonseok$ cat /User/hyeonseok/.ssh/id_rsa.pub >> ~/.ssh/authrized_keys <= 접속 허용 목록에 추가
ssh key file 생성
- Command를 실행 할 곳에서 key file을 생성하고, 모든 장비로 복사 (접속 계정에 주의)
ssh 접속 Test
choiui-MacBook:hadoop-1.1.2 hyeonseok$ ssh hyeonseok@localhost
Last login:Thu Aug 15 18:07:55 2013
choiui-MacBook:~ hyeonseok$
13년 8월 16일 금요일](https://image.slidesharecdn.com/hwotosetuphadoop-130815110606-phpapp01/75/Java-hadoop-18-2048.jpg)
![파일 시스템 format
choiui-MacBook:~ hyeonseok$ hadoop namenode -format <= 파일 시스템 포멧
13/08/15 23:48:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = choiui-MacBook.local/192.168.100.5
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 1.1.2
STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.1 -r 1440782; compiled by 'hortonfo' on Thu Jan 31 02:03:24 UTC 2013
************************************************************/
13/08/15 23:48:55 INFO util.GSet:VM type = 64-bit
13/08/15 23:48:55 INFO util.GSet: 2% max memory = 19.9175 MB
13/08/15 23:48:55 INFO util.GSet: capacity = 2^21 = 2097152 entries
13/08/15 23:48:55 INFO util.GSet: recommended=2097152, actual=2097152
2013-08-15 23:48:55.787 java[6120:1603] Unable to load realm info from SCDynamicStore
13/08/15 23:48:56 INFO namenode.FSNamesystem: fsOwner=hyeonseok
13/08/15 23:48:56 INFO namenode.FSNamesystem: supergroup=supergroup
13/08/15 23:48:56 INFO namenode.FSNamesystem: isPermissionEnabled=true
13/08/15 23:48:56 INFO namenode.FSNamesystem: dfs.block.invalidate.limit=100
13/08/15 23:48:56 INFO namenode.FSNamesystem: isAccessTokenEnabled=false accessKeyUpdateInterval=0 min(s), accessTokenLifetime=0 min(s)
13/08/15 23:48:56 INFO namenode.NameNode: Caching file names occuring more than 10 times
13/08/15 23:48:56 INFO common.Storage: Image file of size 115 saved in 0 seconds.
13/08/15 23:48:56 INFO namenode.FSEditLog: closing edit log: position=4, editlog=/tmp/hadoop-hyeonseok/dfs/name/current/edits
13/08/15 23:48:56 INFO namenode.FSEditLog: close success: truncate to 4, editlog=/tmp/hadoop-hyeonseok/dfs/name/current/edits
13/08/15 23:48:56 INFO common.Storage: Storage directory /tmp/hadoop-hyeonseok/dfs/name has been successfully formatted.
13/08/15 23:48:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at choiui-MacBook.local/192.168.100.5
13년 8월 16일 금요일](https://image.slidesharecdn.com/hwotosetuphadoop-130815110606-phpapp01/75/Java-hadoop-19-2048.jpg)

![P.105 예제 3-3 실행 [1]
choiui-MacBook:bin hyeonseok$ hadoop fs -ls / <= hdfs / 디렉토리 확인
2013-08-15 23:56:31.878 java[7231:1603] Unable to load realm info from SCDynamicStore
Found 1 items
drwxr-xr-x - hyeonseok supergroup 0 2013-08-15 23:49 /tmp
choiui-MacBook:bin hyeonseok$ hadoop fs -copyFromLocal input.txt /tmp/ <= input.txt를 hdfs로 copy
2013-08-15 23:57:19.739 java[7250:1603] Unable to load realm info from SCDynamicStore
choiui-MacBook:bin hyeonseok$ hadoop fs -ls /tmp <= copy 확인
2013-08-15 23:57:33.085 java[7288:1603] Unable to load realm info from SCDynamicStore
Found 2 items
drwxr-xr-x - hyeonseok supergroup 0 2013-08-15 23:49 /tmp/hadoop-hyeonseok
-rw-r--r-- 1 hyeonseok supergroup 12 2013-08-15 23:57 /tmp/input.txt <= hadoop classpath 확인
choiui-MacBook:bin hyeonseok$ echo $HADOOP_CLASSPATH
.
choiui-MacBook:bin hyeonseok$ hadoop com.cecil.ch3.FileSystemDoubleCat /tmp/input.txt <= DoubleCat 실행
2013-08-15 23:59:20.133 java[7329:1603] Unable to load realm info from SCDynamicStore
hadoop test
hadoop test
./com
./com/cecil
./com/cecil/ch3
./com/cecil/ch3/FileSystemDoubleCat.class
./input.txt
Local 디렉토리 구조
hdfs의 input.txt 파일을 사용하여 실행
13년 8월 16일 금요일](https://image.slidesharecdn.com/hwotosetuphadoop-130815110606-phpapp01/75/Java-hadoop-21-2048.jpg)




![실행
choiui-MacBook:test hyeonseok$ hadoop jar WordCount.jar /tmp/input.txt /tmp/out <= WordCount 실행
2013-08-16 00:24:33.064 java[7550:1603] Unable to load realm info from SCDynamicStore
13/08/16 00:24:34 INFO input.FileInputFormat:Total input paths to process : 1
13/08/16 00:24:34 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
13/08/16 00:24:34 WARN snappy.LoadSnappy: Snappy native library not loaded
13/08/16 00:24:35 INFO mapred.JobClient: Running job: job_201308152355_0001
13/08/16 00:24:36 INFO mapred.JobClient: map 0% reduce 0%
13/08/16 00:24:45 INFO mapred.JobClient: map 100% reduce 0%
13/08/16 00:24:53 INFO mapred.JobClient: map 100% reduce 33%
13/08/16 00:24:55 INFO mapred.JobClient: map 100% reduce 100%
:
13/08/16 00:24:56 INFO mapred.JobClient: Map output records=2
choiui-MacBook:test hyeonseok$
choiui-MacBook:test hyeonseok$ hadoop fs -ls /tmp/out <= 실행 결과 생성된 파일들
2013-08-16 00:25:30.600 java[7640:1603] Unable to load realm info from SCDynamicStore
Found 3 items
-rw-r--r-- 1 hyeonseok supergroup 0 2013-08-16 00:24 /tmp/out/_SUCCESS
drwxr-xr-x - hyeonseok supergroup 0 2013-08-16 00:24 /tmp/out/_logs
-rw-r--r-- 1 hyeonseok supergroup 16 2013-08-16 00:24 /tmp/out/part-r-00000
choiui-MacBook:test hyeonseok$ fs -ls /tmp/out/part-r-00000
-bash: fs: command not found
choiui-MacBook:test hyeonseok$ hadoop fs -cat /tmp/out/part-r-00000 <= 결과 확인
2013-08-16 00:25:57.141 java[7661:1603] Unable to load realm info from SCDynamicStore
hadoop
1
test
1
map-reduce 작업 시 input과 output을 명시
- output은 존재하지 않는 디렉토리여야 함. 존재할 경우 실패.
13년 8월 16일 금요일](https://image.slidesharecdn.com/hwotosetuphadoop-130815110606-phpapp01/75/Java-hadoop-29-2048.jpg)















![[211] HBase 기반 검색 데이터 저장소 (공개용)](https://cdn.slidesharecdn.com/ss_thumbnails/211hbase-171016101436-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[234]멀티테넌트 하둡 클러스터 운영 경험기](https://cdn.slidesharecdn.com/ss_thumbnails/234-171017024419-thumbnail.jpg?width=640&height=640&fit=bounds)












![[AWSKRUG] 모바일게임 하이브 런칭기 (2018)](https://cdn.slidesharecdn.com/ss_thumbnails/awskrugawsformobilegame-190419125248-thumbnail.jpg?width=640&height=640&fit=bounds)




















