HADOOP Copyright(c) Dep.Of Computer Science, SeoKyeong Univ.
1.JAVA 설치
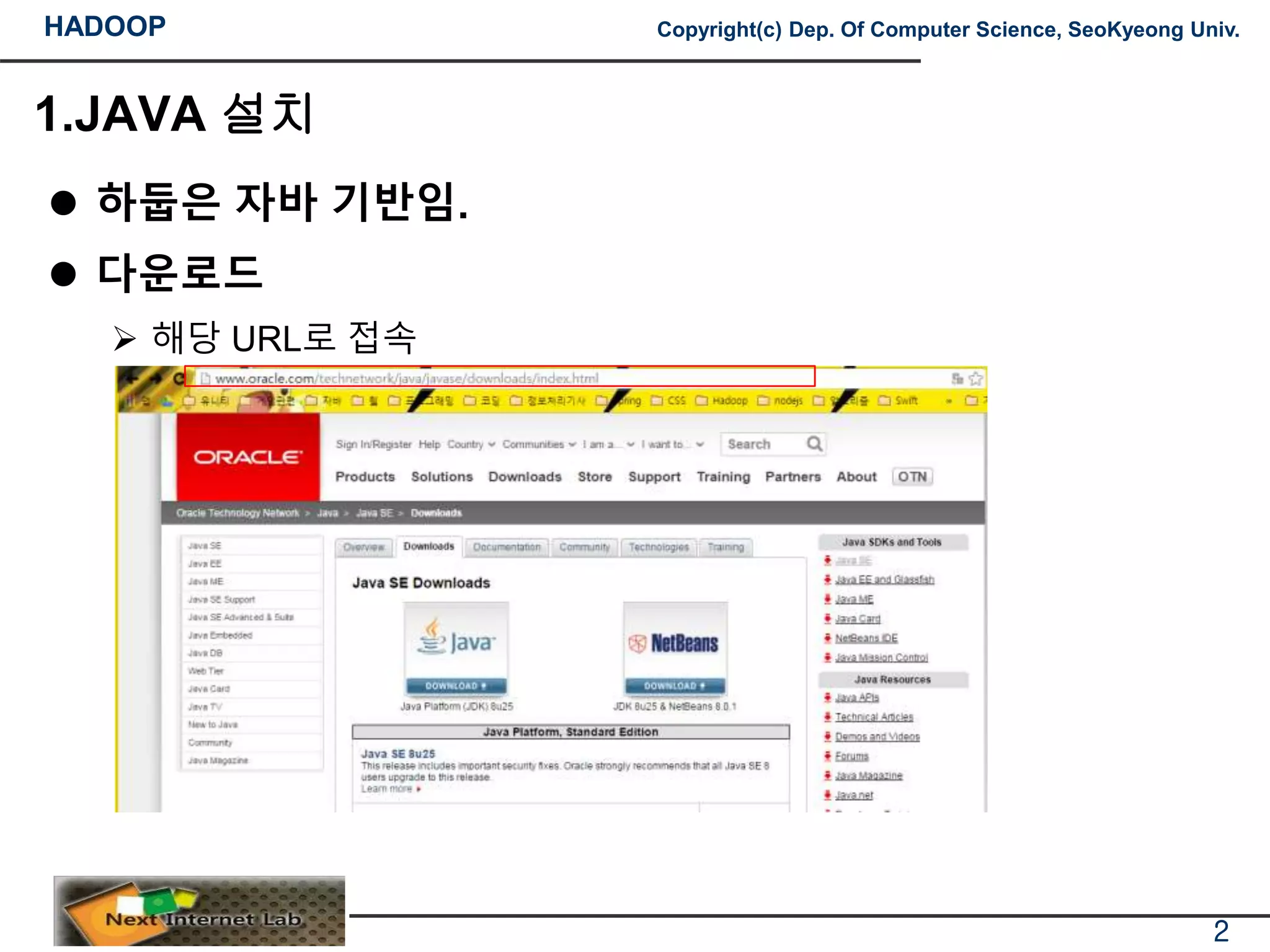
하둡은 자바 기반임.
다운로드
해당 URL로 접속
2
3.
HADOOP Copyright(c) Dep.Of Computer Science, SeoKyeong Univ.
1.JAVA 설치
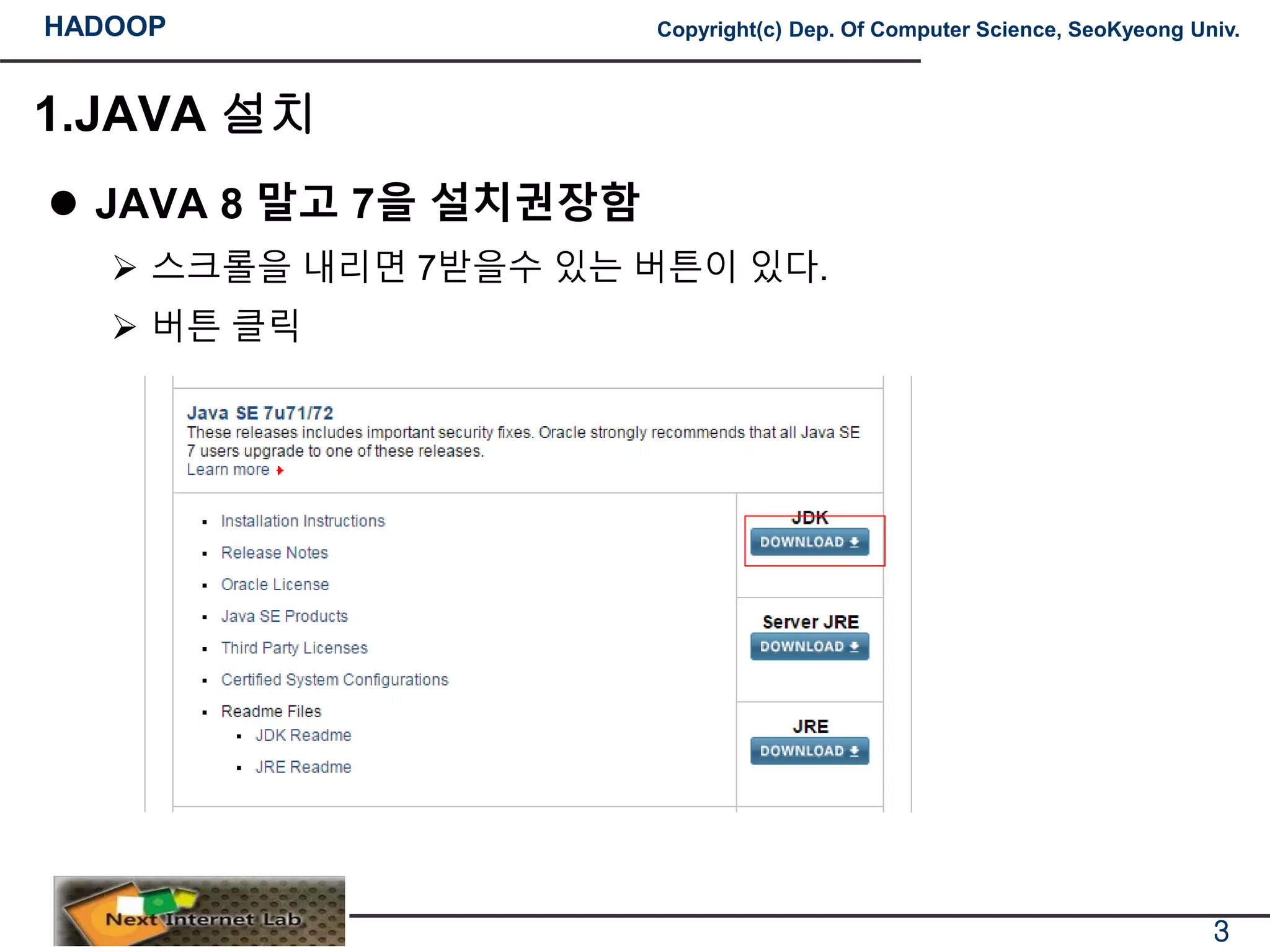
JAVA 8 말고 7을 설치권장함
스크롤을 내리면 7받을수 있는 버튼이 있다.
버튼 클릭
3
4.
HADOOP Copyright(c) Dep.Of Computer Science, SeoKyeong Univ.
1.JAVA 설치
자바 다운로드
Accept License 체크후 자기 운영체제에 맞는 것 다운로드
현재 Centos 6.5 를 사용하고 있으므로 JDK버전-linux.x64-tar.gz
4
*자기 자신의
운영체제 bit에
맞게 다운로드
5.
HADOOP Copyright(c) Dep.Of Computer Science, SeoKyeong Univ.
1.JAVA 설치
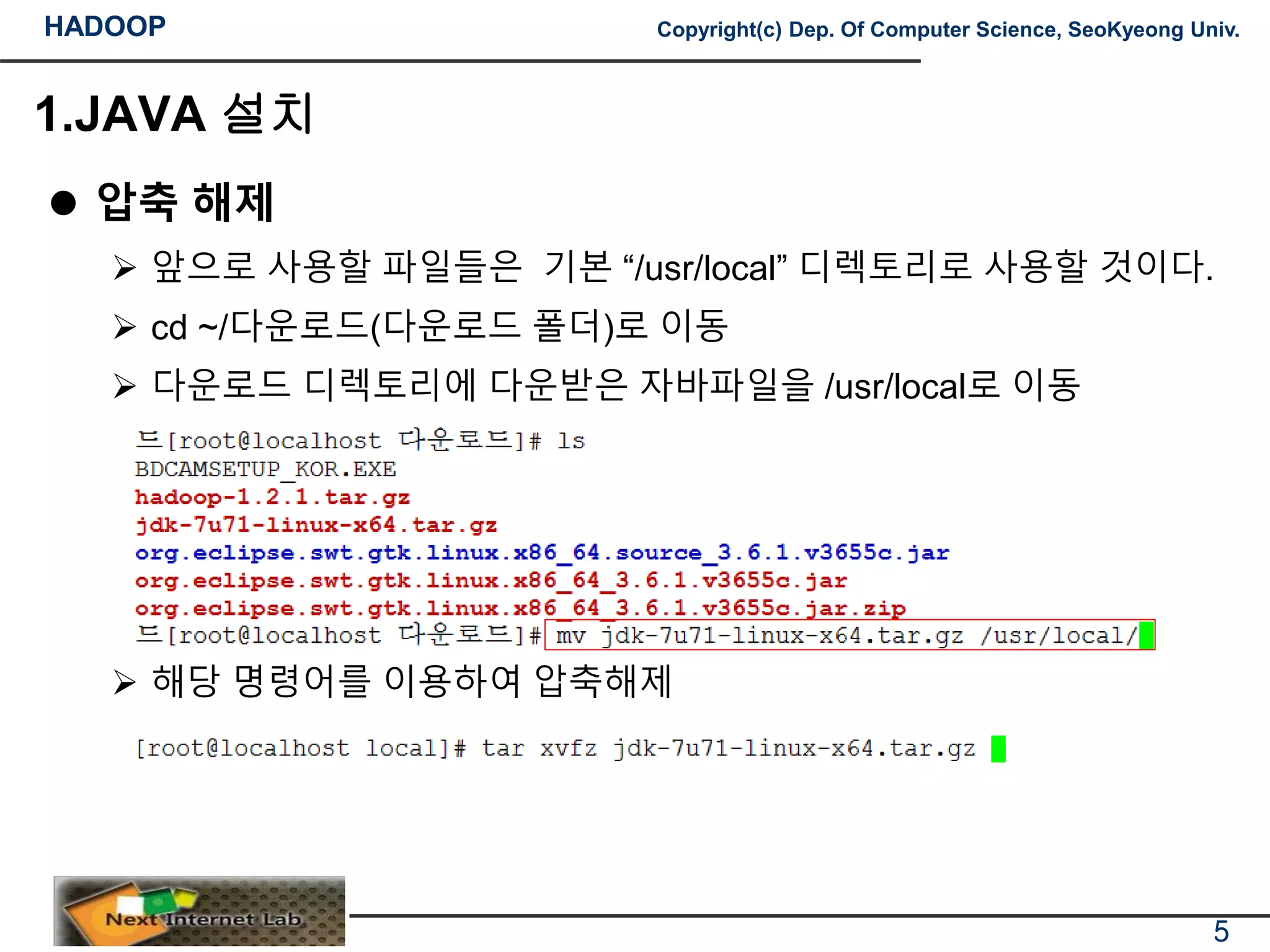
압축 해제
앞으로 사용할 파일들은 기본 “/usr/local” 디렉토리로 사용할 것이다.
cd ~/다운로드(다운로드 폴더)로 이동
다운로드 디렉토리에 다운받은 자바파일을 /usr/local로 이동
해당 명령어를 이용하여 압축해제
5
6.
HADOOP Copyright(c) Dep.Of Computer Science, SeoKyeong Univ.
1.JAVA 설치
심볼릭 링크 걸어주기
Jdk로 시작되는 디렉토리의 닉네임을 정해준다.
앞으로 jdk~~ 폴더는 java라는 이름으로 사용할수 있게된다.
환경변수
환경변수 설정을 하면 어디에서든지 자바명령어를 사용가능하다
여러가지 환경설정파일을 사용할수 있지만 우리는 /etc/profile 에 작성
한다.(vi명령어는 텍스트 편집 도구이다.)
6
7.
HADOOP Copyright(c) Dep.Of Computer Science, SeoKyeong Univ.
1.JAVA 설치
환경변수 설정
Profile 파일에 아무곳이나 해당 텍스트를 입력한다.
입력이 끝났으면 esc -> ‘:’키 누름 -> wq입력 -> 엔터 (저장하는법)
이제 source /etc/profile 을 입력하여 해당 파일을 업데이트 한다
만약 에러메시지가 나올경우 스펠링 틀린것.
해당 명령어를 입력하여 제대로 그 디렉토리로 이동이 되는지 확인
7
8.
HADOOP Copyright(c) Dep.Of Computer Science, SeoKyeong Univ.
2.하둡 설치
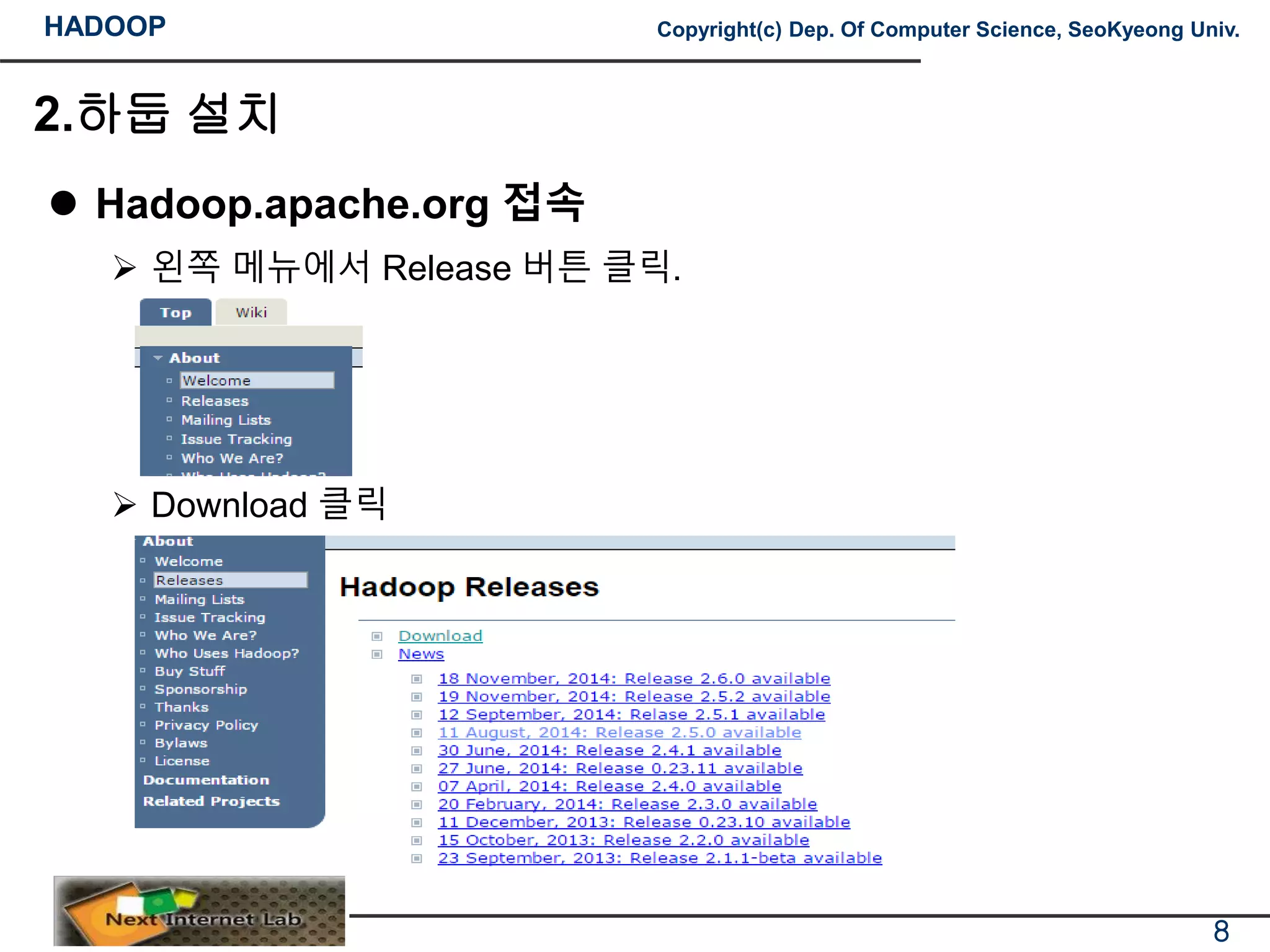
Hadoop.apache.org 접속
왼쪽 메뉴에서 Release 버튼 클릭.
Download 클릭
8
9.
HADOOP Copyright(c) Dep.Of Computer Science, SeoKyeong Univ.
2.하둡 설치
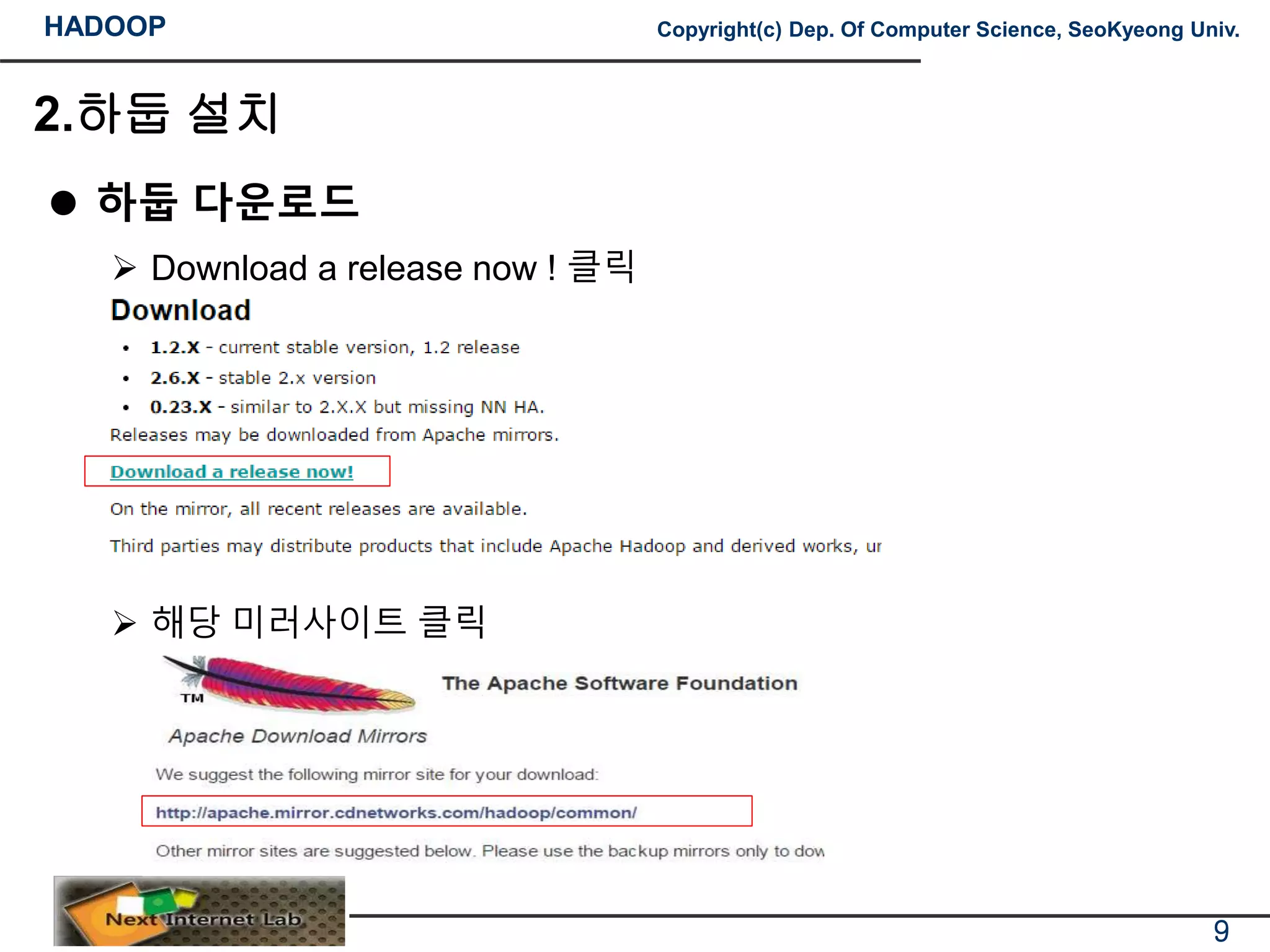
하둡 다운로드
Download a release now ! 클릭
해당 미러사이트 클릭
9
10.
HADOOP Copyright(c) Dep.Of Computer Science, SeoKyeong Univ.
2.하둡 설치
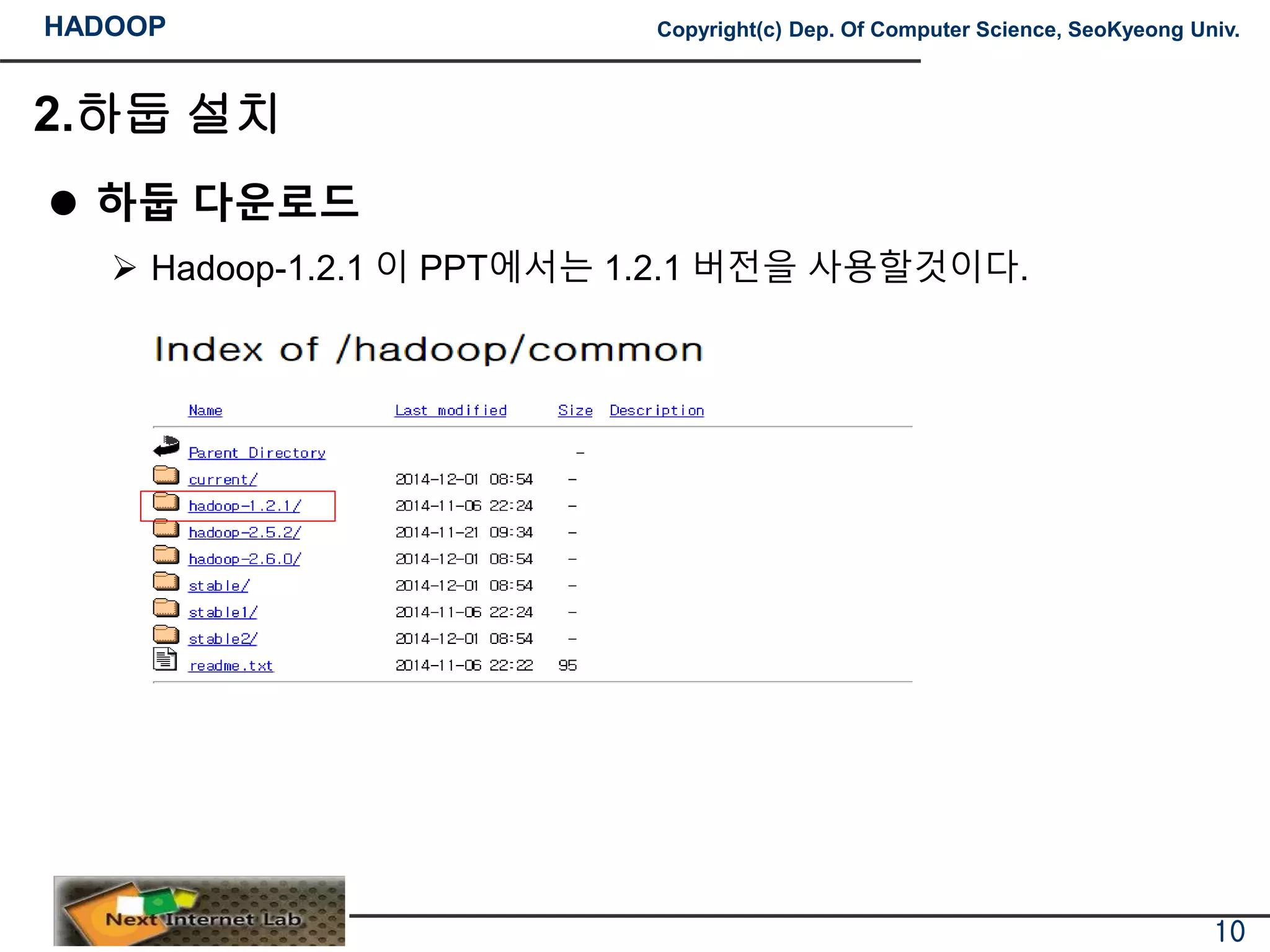
하둡 다운로드
Hadoop-1.2.1 이 PPT에서는 1.2.1 버전을 사용할것이다.
10
11.
HADOOP Copyright(c) Dep.Of Computer Science, SeoKyeong Univ.
2.하둡 설치
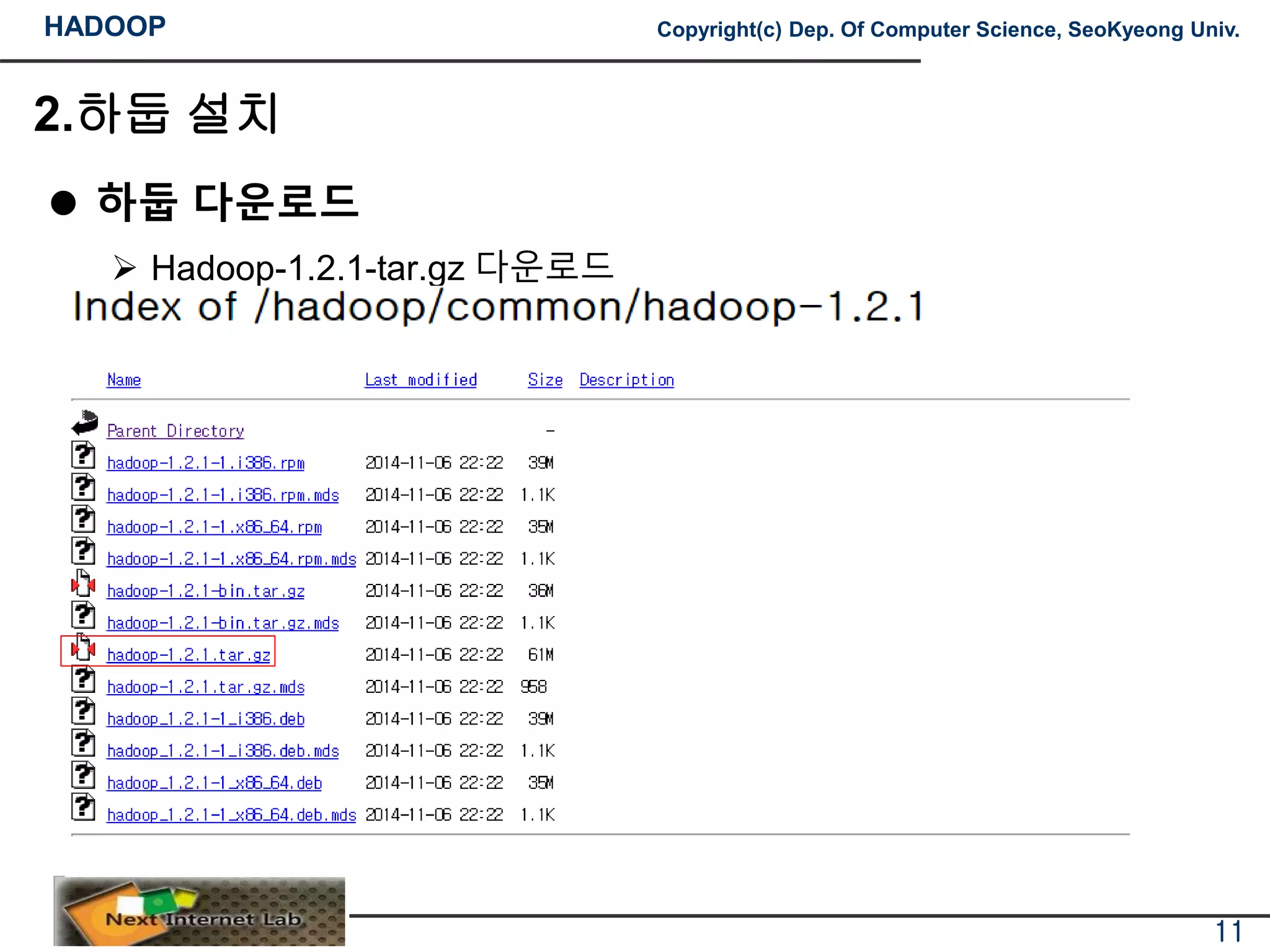
하둡 다운로드
Hadoop-1.2.1-tar.gz 다운로드
11
12.
HADOOP Copyright(c) Dep.Of Computer Science, SeoKyeong Univ.
2.하둡 설치
하둡 다운로드
리눅스 다운경로로 이동.(cd ~/다운로드)
하둡파일 /usr/local로 이동(mv hadoop-1.2.1.tar.gz /usr/local)
Gz 압축 풀기(tar xvfz hadoop-1.2.1.tar.gz)
심볼릭링크 걸어주기(ln –s hadoop-1.2.1 hadoop)
결과 화면
하둡 폴더 hadoop-1.2.1 과 심볼릭링크로 걸린 hadoop 이 있으면 성공
12
13.
HADOOP Copyright(c) Dep.Of Computer Science, SeoKyeong Univ.
2.하둡 설치
하둡 환경변수 설정
자바 설치때와 마찬가지로 hadoop폴더에 링크를 걸어주겠다.
vi 에디터로 profile 수정(vi /etc/profile)
다음과 같은 구문을 추가시켜준다.
* HADOOP_HOME_WARN_SUPPRESS
는 하둡실행시 뜨는 에러를 처리하기 위함
13
14.
HADOOP Copyright(c) Dep.Of Computer Science, SeoKyeong Univ.
2.하둡 설치
하둡 확인
vi 에디터로 수정완료 했으면 (esc -> ‘:’ -> wq입력 -> 엔터 로 저장)
source /etc/profile 을 입력하여 업데이트 해주고
Hadoop version을 입력하여 제대로 환경변수가 잡혔는지 확인
다음 그림과 같이 뜨면 정상설치
14
15.
HADOOP Copyright(c) Dep.Of Computer Science, SeoKyeong Univ.
3.하둡 환경설정
하둡의 모드
1. 독립실행 모드
- 하둡개발의 환경설정만 해주는 모드 맵리듀스 테스트할때 사용
2. 의사분산 모드
- 로컬컴퓨터 하나에서 데몬 프로세스를 여러 개 사용하는 모드
3. 완전분산 모드
- 실제로 클러스터를 구성하고 하둡을 설정하는 모드
자세한 설명은 책이나 구글을 찾아볼것!
15
16.
HADOOP Copyright(c) Dep.Of Computer Science, SeoKyeong Univ.
3.하둡 환경설정
이 PPT는 의사분산모드 목적으로 만들었으므로 의사분산 모
드 환경설정을 따른다
하둡의 모드의 변경을 위해서는 hadoop 디렉토리내의 conf안에 있는
모든 파일들에게 환경을 명시해주어야 한다.
수정해야할 파일들 목록
core-site.xml ( 공통적인 환경설정)
hdfs-site.xml (HDFS 에 관한 환경설정 - 저장소관련)
mapred-site.xml (맵리듀스에 관한 환경설정 – 데이터분석 관련)
16
17.
HADOOP Copyright(c) Dep.Of Computer Science, SeoKyeong Univ.
3.하둡 환경설정
환경설정
하둡 conf디렉토리로 이동하여 환경설정을 시작한다
cd $HADOOP_HOME/conf
“core-site.xml” 수정 (vi core-site.xml)
17
HADOOP Copyright(c) Dep.Of Computer Science, SeoKyeong Univ.
3.하둡 환경설정
SSH 설정
하둡은 노드간의 통신을 ssh 방식으로 사용하기 때문에
하둡실행시 항상 ssh 접근 비밀번호를 요구하는 경우가 발생
문제를 해결하기 위해 공개키를 설정해 준다.
Rsa 키 생성 (ssh-keygen –t rsa 입력 [모든 물음은 다 엔터])
19
20.
HADOOP Copyright(c) Dep.Of Computer Science, SeoKyeong Univ.
3.하둡 환경설정
SSH 설정
키를 자기 자신에게 설정
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
ssh root@localhost 입력하여 비밀번호를 묻지 않는다면 성공!
20
21.
HADOOP Copyright(c) Dep.Of Computer Science, SeoKyeong Univ.
4.하둡 실행
HDFS 초기화
hadoop namenode –format 명령어를 이용하여 포맷한다.
start-all.sh 를 입력하여 하둡데몬프로세스 실행
Jps 명령어를 입력하여 밑에 그림과같이 6개 목록이 뜨면 실행성공!
21
22.
HADOOP Copyright(c) Dep.Of Computer Science, SeoKyeong Univ.
4.하둡 실행
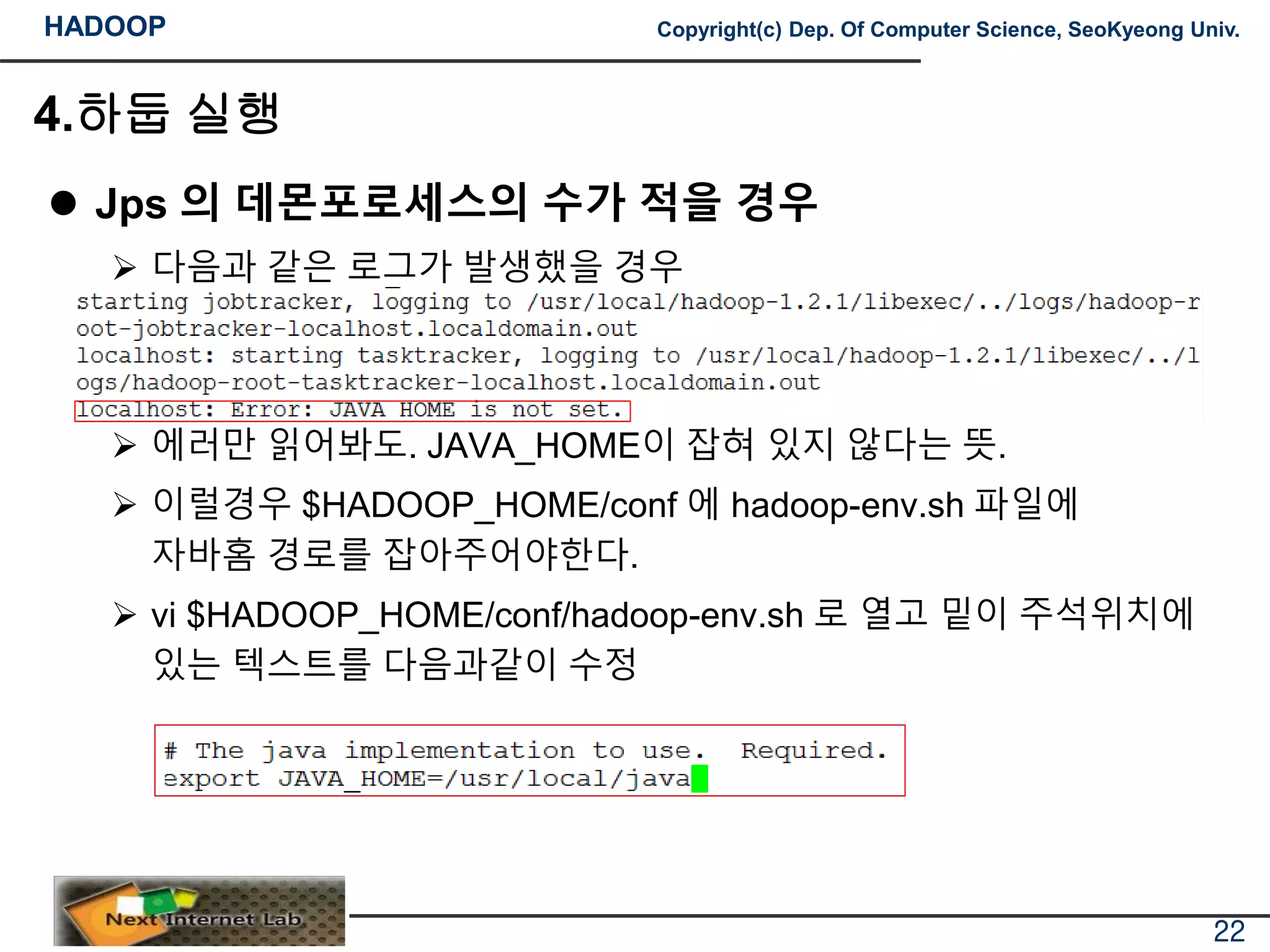
Jps 의 데몬포로세스의 수가 적을 경우
다음과 같은 로그가 발생했을 경우
에러만 읽어봐도. JAVA_HOME이 잡혀 있지 않다는 뜻.
이럴경우 $HADOOP_HOME/conf 에 hadoop-env.sh 파일에
자바홈 경로를 잡아주어야한다.
vi $HADOOP_HOME/conf/hadoop-env.sh 로 열고 밑이 주석위치에
있는 텍스트를 다음과같이 수정
22
23.
HADOOP Copyright(c) Dep.Of Computer Science, SeoKyeong Univ.
4.하둡 실행
이제 환경설정은 끝났으니 간단한 예제로 데이터 분석해보자
Wordcount를 해보자
Wordcount 는 텍스트에서 단어의 개수를 추출하는 예제
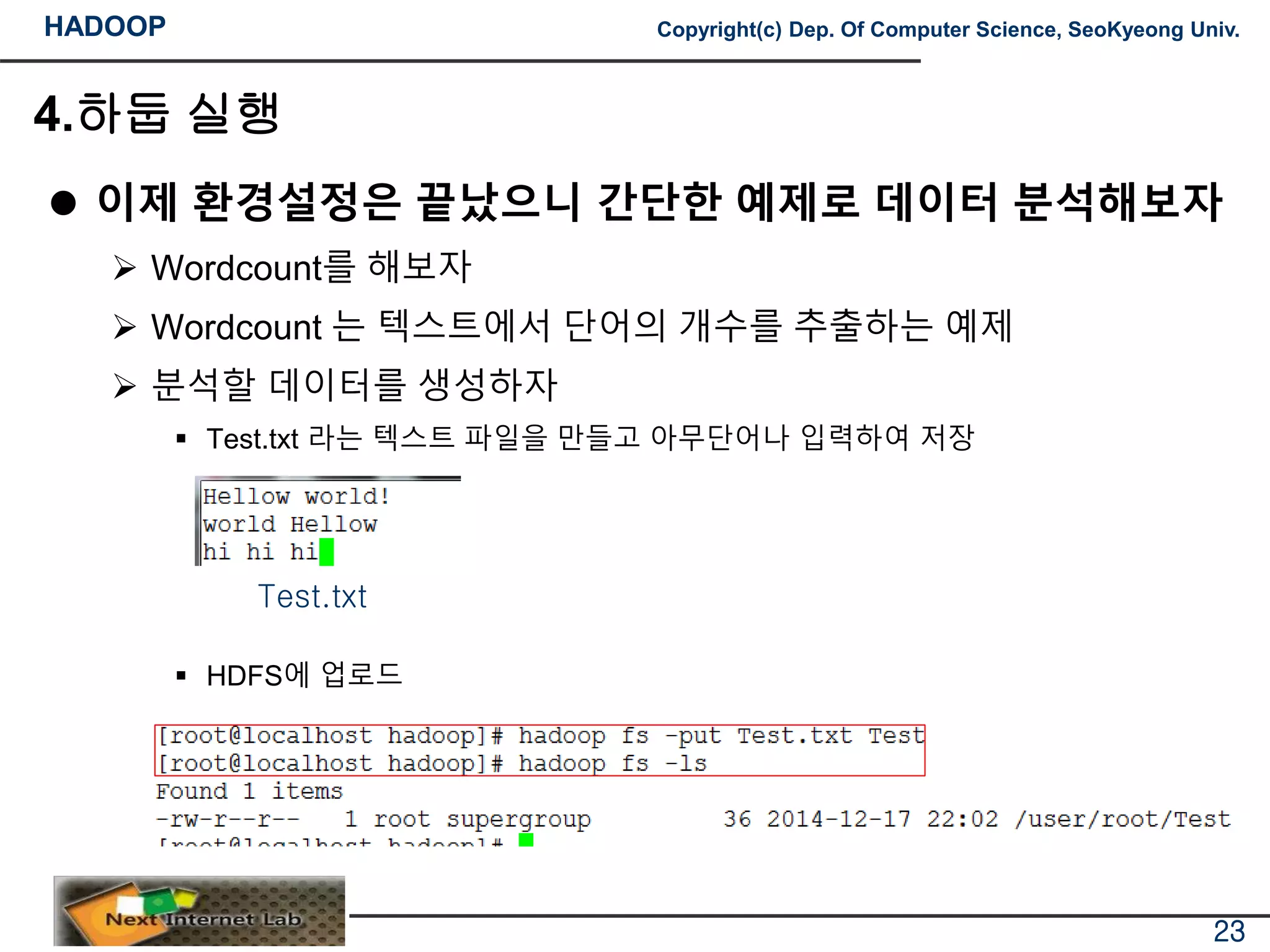
분석할 데이터를 생성하자
Test.txt 라는 텍스트 파일을 만들고 아무단어나 입력하여 저장
HDFS에 업로드
23
Test.txt
24.
HADOOP Copyright(c) Dep.Of Computer Science, SeoKyeong Univ.
4.하둡 실행
하둡 실행
하둡 디렉토리에서 다음과 같은 명령어로 실행
명령어 해석
1. hadoop : 하둡 실행
2. jar : jar파일을 사용
3. hadoop-example-1.2.1.jar : 해당이름의 자르파일을 사용하여 분석
4. wordcount : 해당 자르파일중에 wordcount 실행
5. test.txt : Input data가 HDFS 에 Test.txt 라는 파일을 사용하겠단든 뜻
6. output : 결과를 HDFS 에 output 디렉토리에 저장 하겠다는 뜻
24
25.
HADOOP Copyright(c) Dep.Of Computer Science, SeoKyeong Univ.
4.하둡 실행
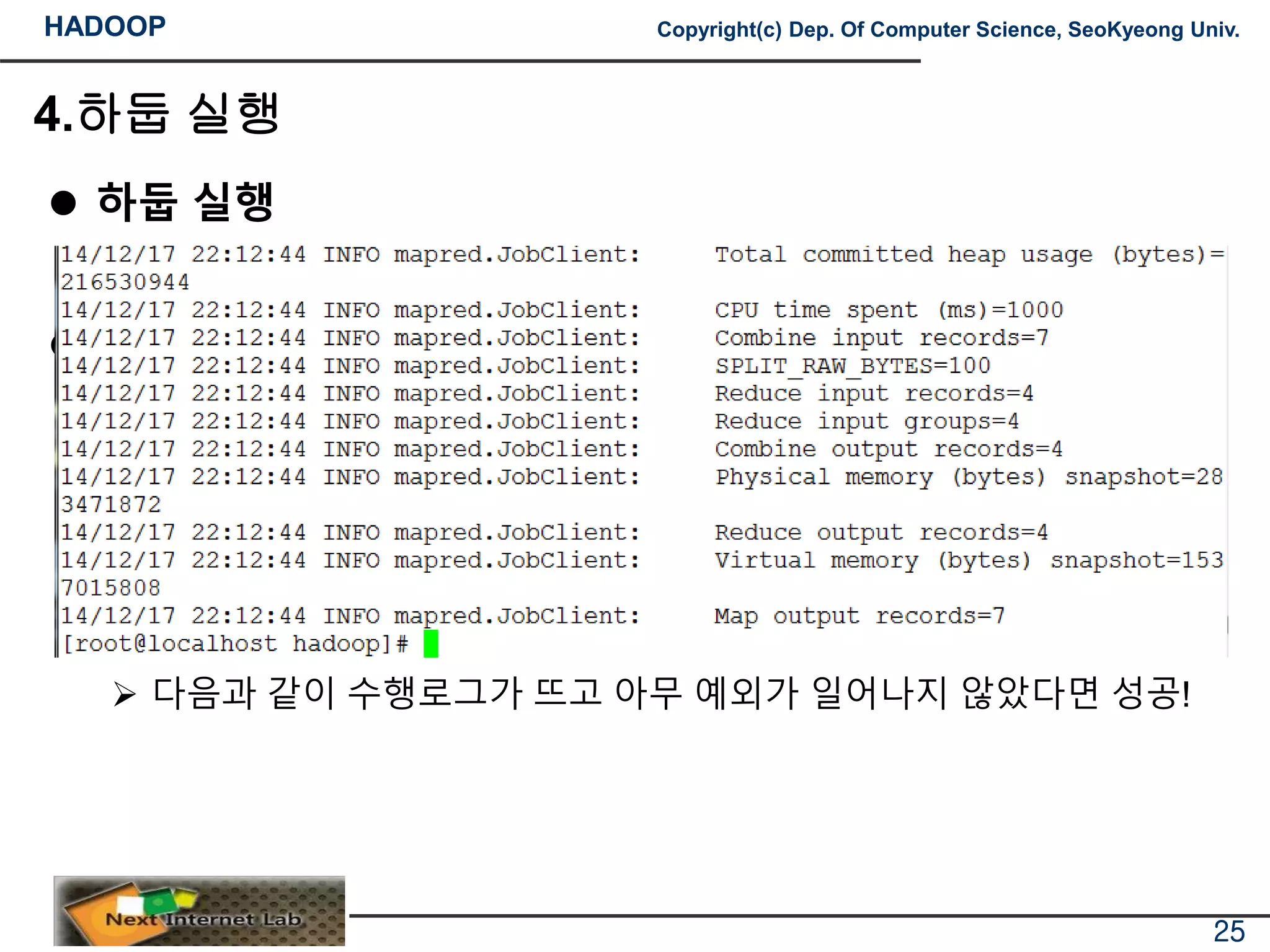
하둡 실행
다음과 같이 수행로그가 뜨고 아무 예외가 일어나지 않았다면 성공!
25
26.
HADOOP Copyright(c) Dep.Of Computer Science, SeoKyeong Univ.
4.하둡 실행
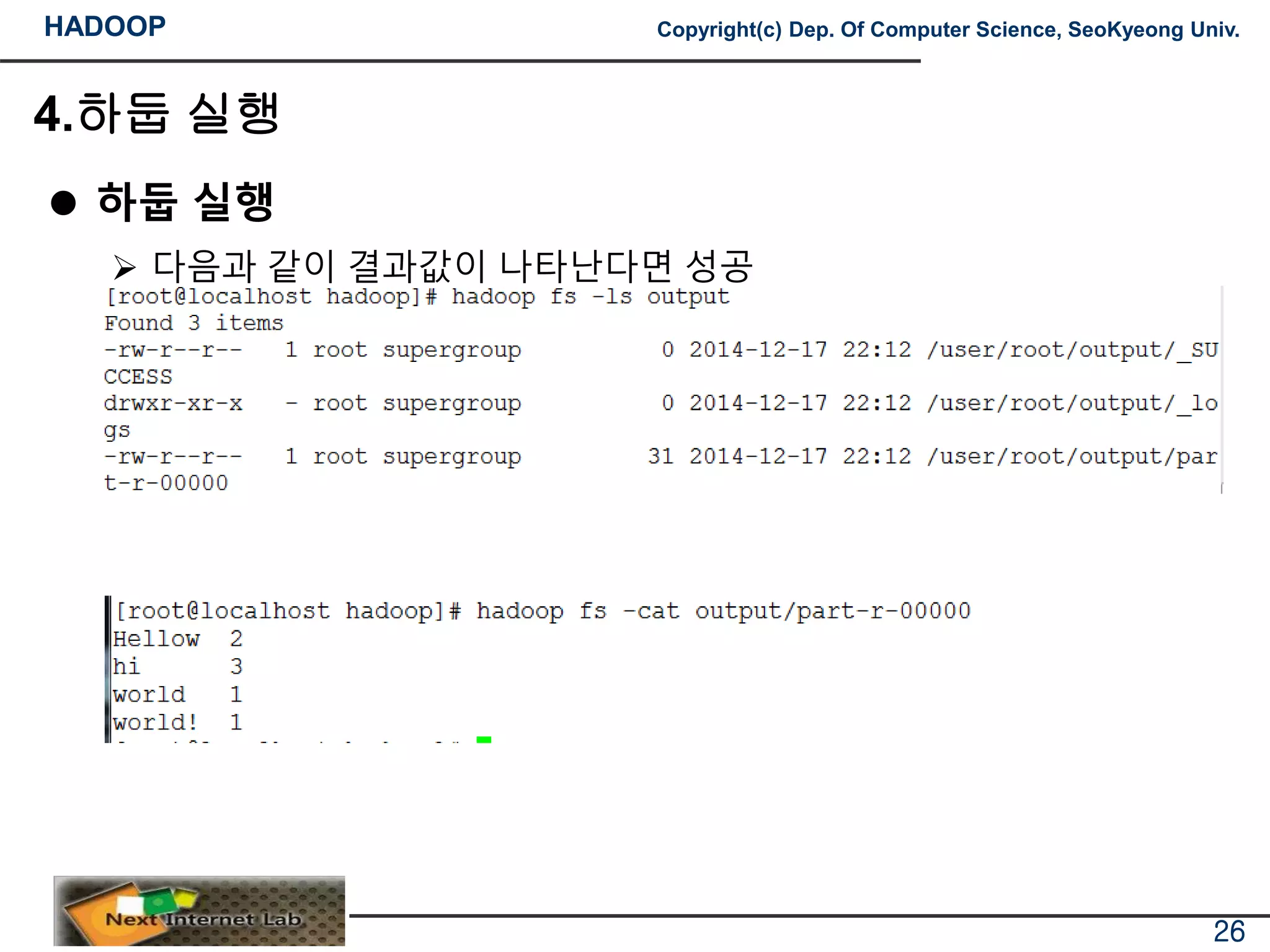
하둡 실행
다음과 같이 결과값이 나타난다면 성공
내용확인
26
27.
HADOOP Copyright(c) Dep.Of Computer Science, SeoKyeong Univ.
5. TIP
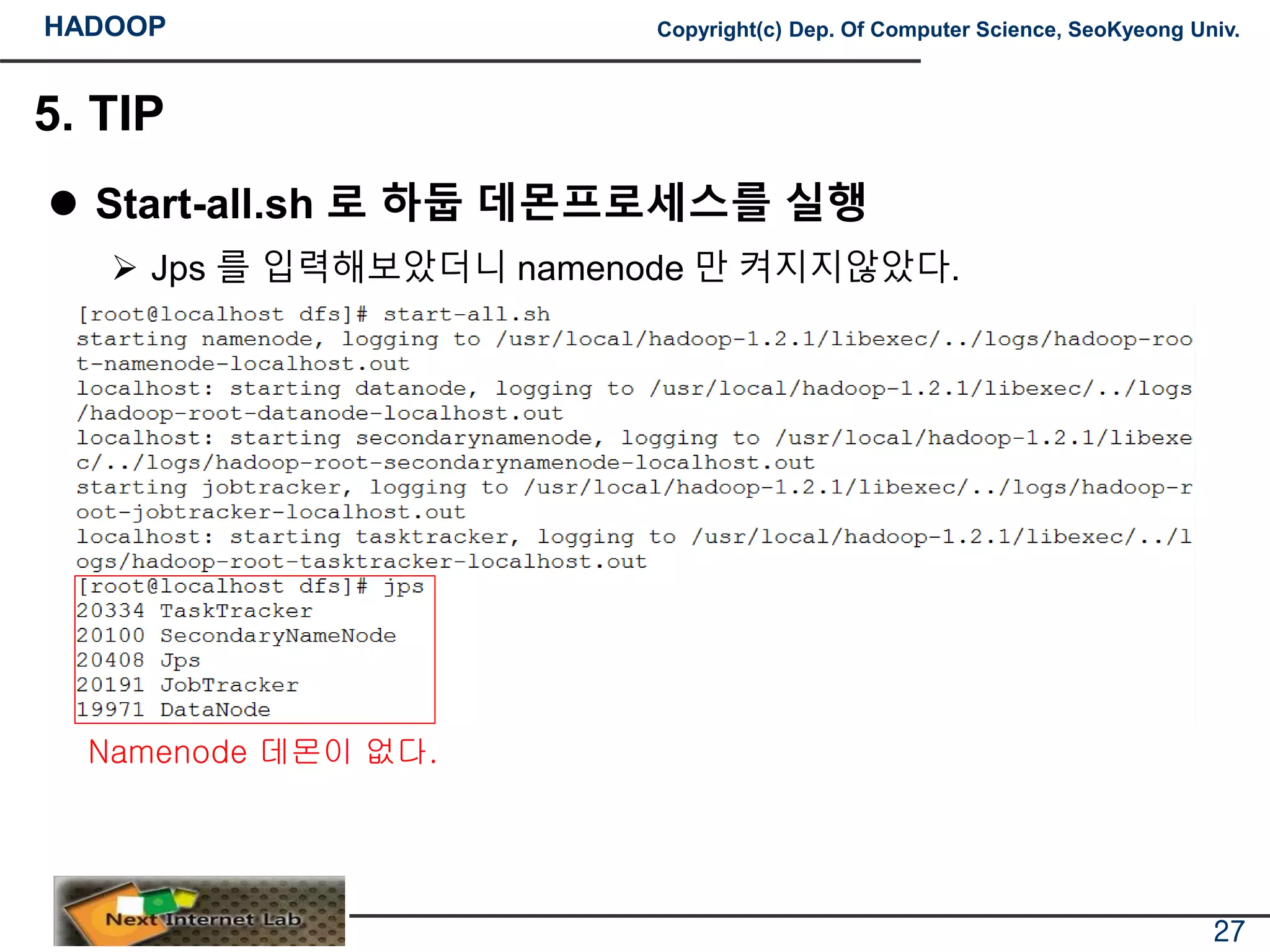
Start-all.sh 로 하둡 데몬프로세스를 실행
Jps 를 입력해보았더니 namenode 만 켜지지않았다.
27
Namenode 데몬이 없다.
28.
HADOOP Copyright(c) Dep.Of Computer Science, SeoKyeong Univ.
5.TIP
Start-all.sh 로 하둡 데몬프로세스를 실행
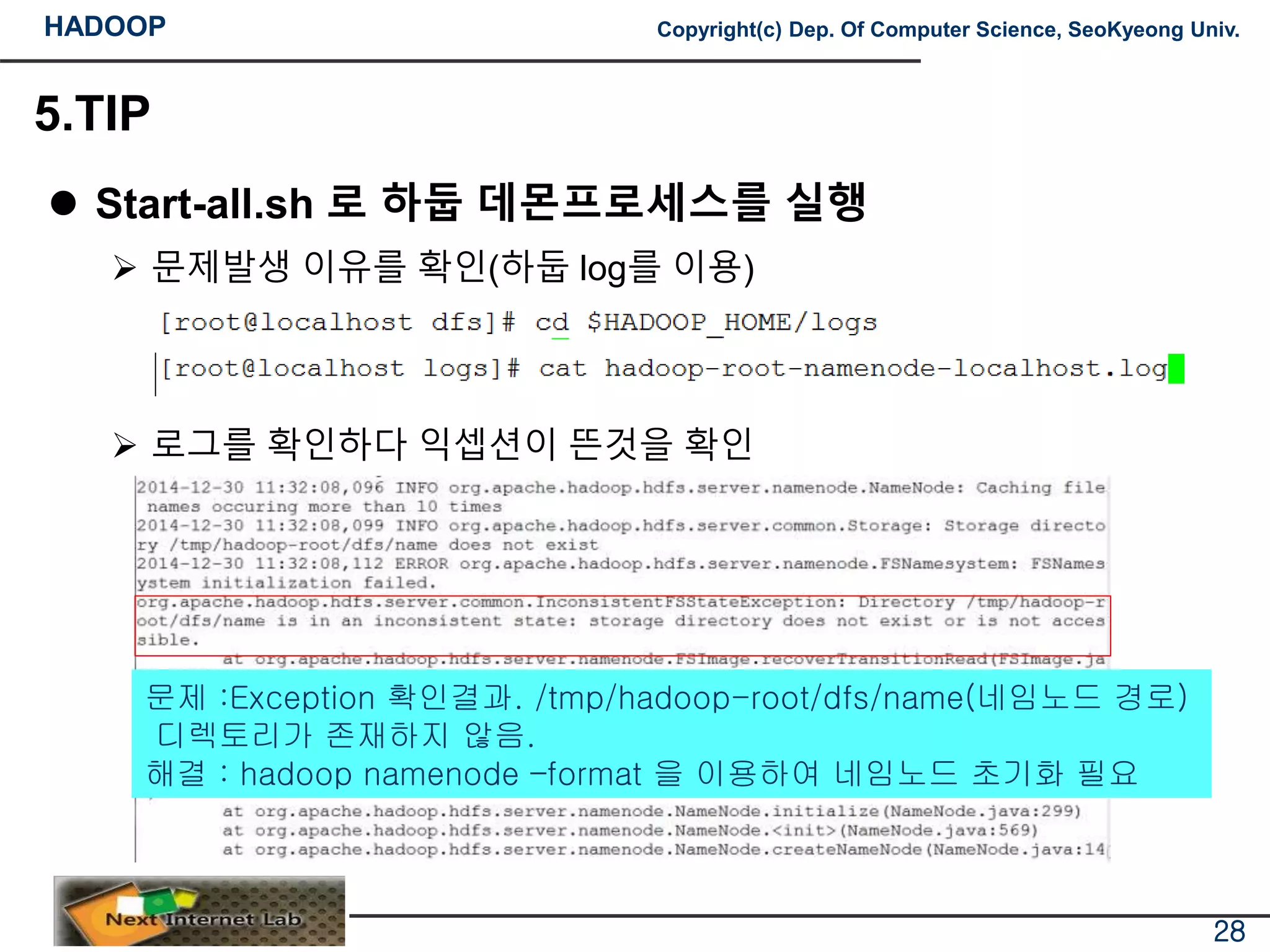
문제발생 이유를 확인(하둡 log를 이용)
로그를 확인하다 익셉션이 뜬것을 확인
28
문제 :Exception 확인결과. /tmp/hadoop-root/dfs/name(네임노드 경로)
디렉토리가 존재하지 않음.
해결 : hadoop namenode –format 을 이용하여 네임노드 초기화 필요
29.
HADOOP Copyright(c) Dep.Of Computer Science, SeoKyeong Univ.
5.TIP
Start-all.sh 로 하둡 데몬프로세스를 실행
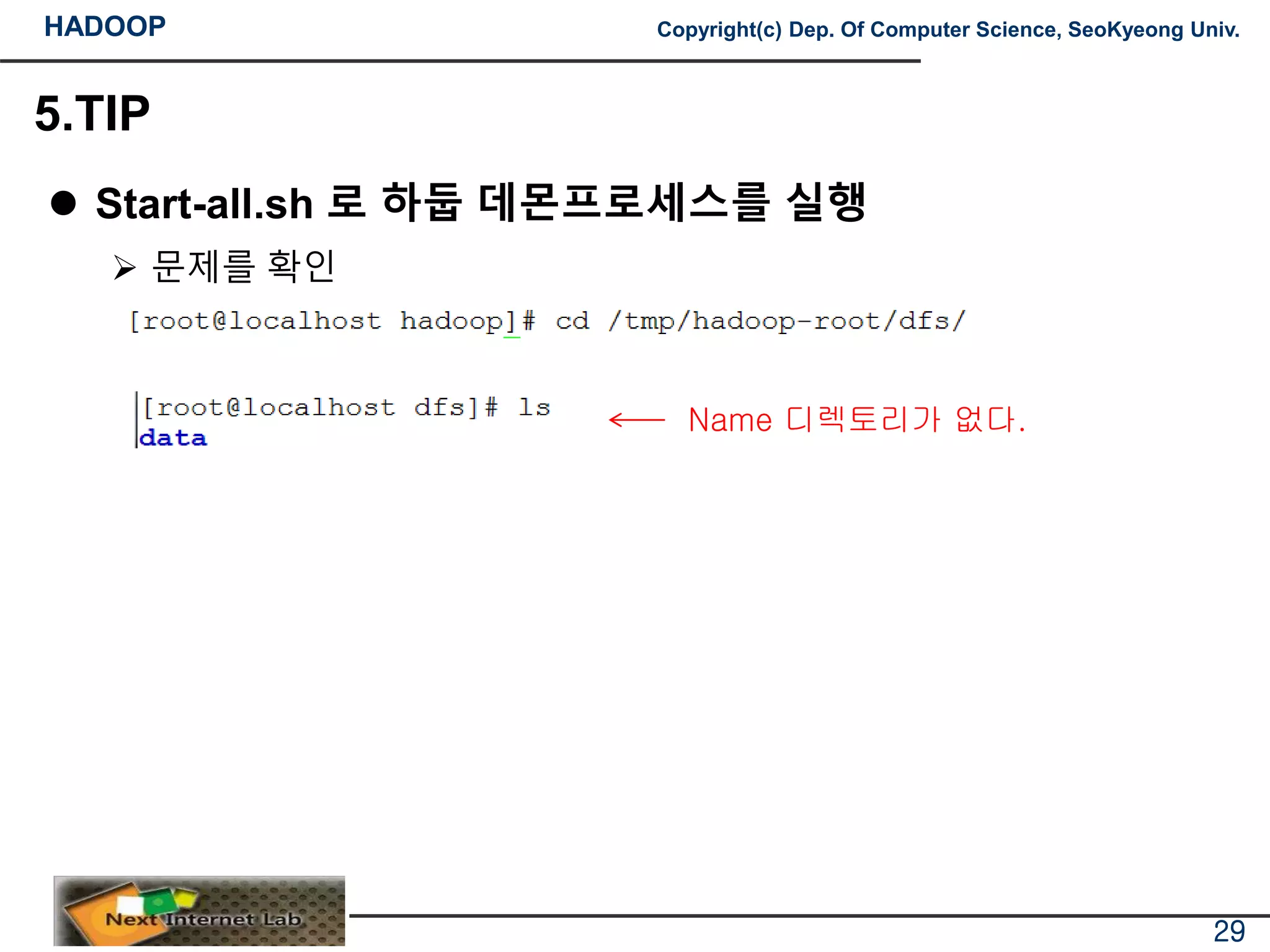
문제를 확인
29
Name 디렉토리가 없다.
30.
HADOOP Copyright(c) Dep.Of Computer Science, SeoKyeong Univ.
5.TIP
Start-all.sh 로 하둡 데몬프로세스를 실행
해결방법
30
1
2
3
포맷 명령어
Hadoop namenode –format을
두번 입력하고 Y를 입력해서
포맷을 실행함
31.
HADOOP Copyright(c) Dep.Of Computer Science, SeoKyeong Univ.
5.TIP
Start-all.sh 로 하둡 데몬프로세스를 실행
다시 실행
Jps로 확인
31
Namenode가 실행되지만.
Datanode가 사라졌다.
다시 확인해보자.
32.
HADOOP Copyright(c) Dep.Of Computer Science, SeoKyeong Univ.
5.TIP
Start-all.sh 로 하둡 데몬프로세스를 실행
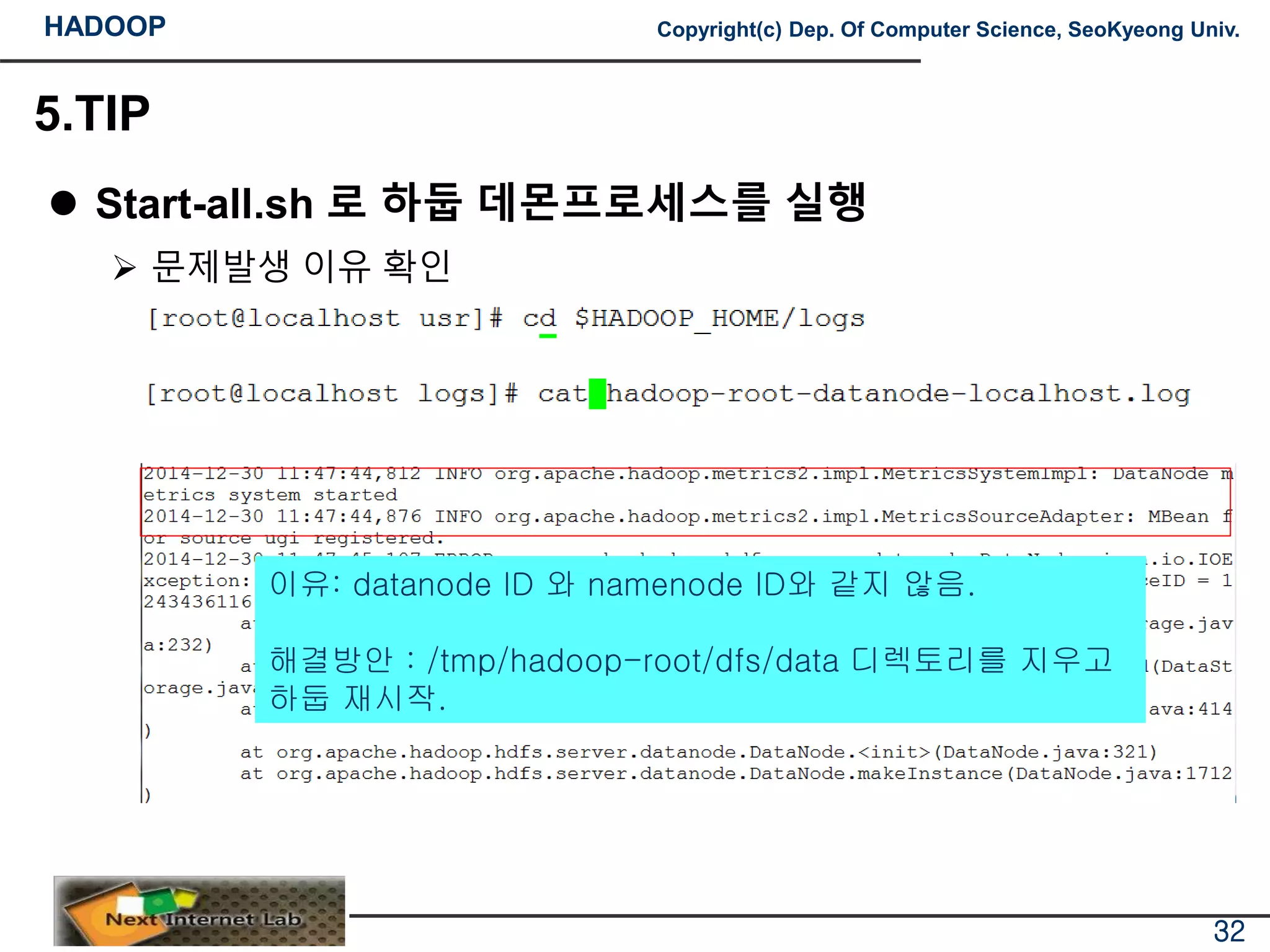
문제발생 이유 확인
32
이유: datanode ID 와 namenode ID와 같지 않음.
해결방안 : /tmp/hadoop-root/dfs/data 디렉토리를 지우고
하둡 재시작.
33.
HADOOP Copyright(c) Dep.Of Computer Science, SeoKyeong Univ.
5.TIP
Start-all.sh 로 하둡 데몬프로세스를 실행
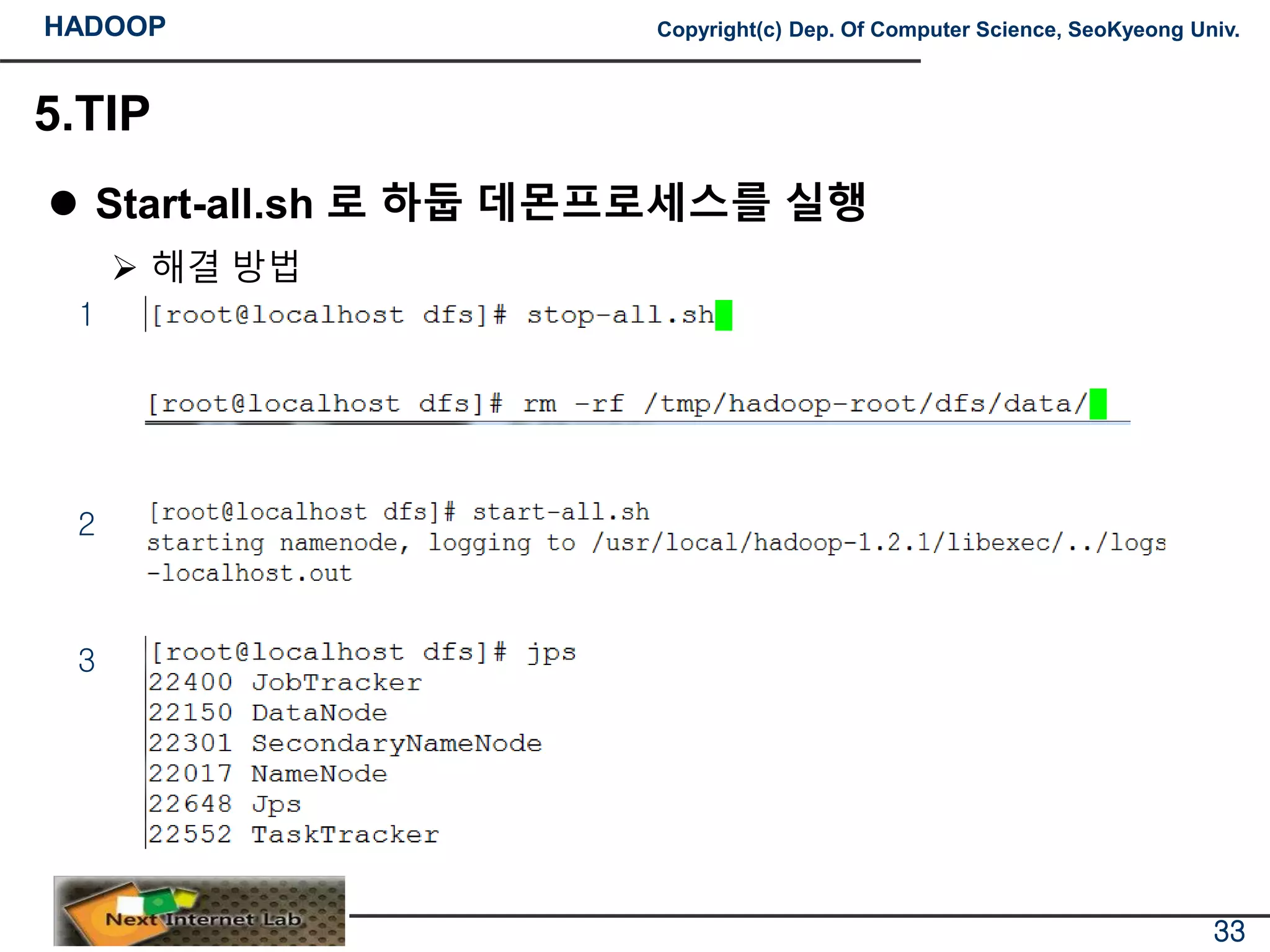
해결 방법
33
1
2
3











![HADOOP Copyright(c) Dep. Of Computer Science, SeoKyeong Univ.
3.하둡 환경설정
SSH 설정
하둡은 노드간의 통신을 ssh 방식으로 사용하기 때문에
하둡실행시 항상 ssh 접근 비밀번호를 요구하는 경우가 발생
문제를 해결하기 위해 공개키를 설정해 준다.
Rsa 키 생성 (ssh-keygen –t rsa 입력 [모든 물음은 다 엔터])
19](https://image.slidesharecdn.com/random-150421032703-conversion-gate01/75/slide-19-2048.jpg)

















































![제 16회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [하둡메이트 팀] : 하둡 설정 고도화 및 맵리듀스 모니터링](https://cdn.slidesharecdn.com/ss_thumbnails/random-220728094615-7bbbfc3e-thumbnail.jpg?width=640&height=640&fit=bounds)

![[234]멀티테넌트 하둡 클러스터 운영 경험기](https://cdn.slidesharecdn.com/ss_thumbnails/234-171017024419-thumbnail.jpg?width=640&height=640&fit=bounds)

