Download as PDF, PPTX







![© 2023 All Rights Reserved
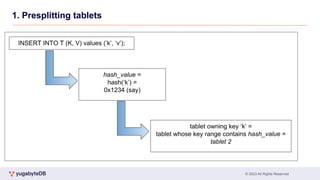
1. Presplitting tablets
● At creation time, presplit a table into the desired number of tablets
○ YSQL tables - Supports both range-sharded and hash-sharded
○ YCQL tables - Support hash-sharded YCQL tables
● Hash-sharded tables
● Max 65536(64k) tablets/shard
● 2-byte range from 0x0000 to 0xFFFF
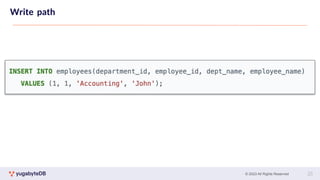
CREATE TABLE customers (
customer_id bpchar NOT NULL,
cname character varying(40),
contact_name character varying(30),
contact_title character varying(30),
PRIMARY KEY (customer_id HASH)
) SPLIT INTO 16 TABLETS;
● e.g. table with 16 tablets the overall hash space [0x0000
to 0xFFFF) is divided into 16 subranges, one for each
tablet: [0x0000, 0x1000), [0x1000, 0x2000), … , [0xF000,
0xFFFF]
● Read/write operations are processed by converting the
primary key into an internal key and its hash value, and
determining to which tablet the operation should be routed](https://image.slidesharecdn.com/gwenn-advancedlevelunlocked-230615074538-e4844306/85/Gwenn-Advanced-level-unlocked_-pdf-12-320.jpg)








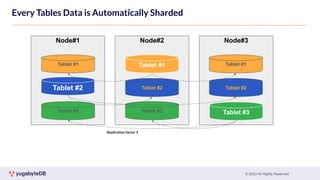
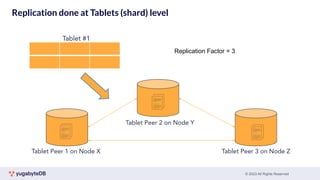
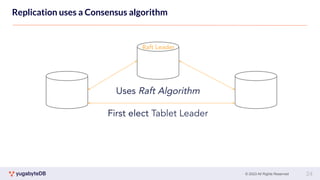
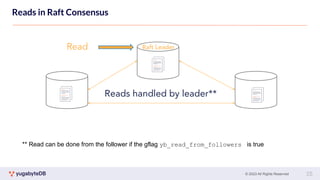
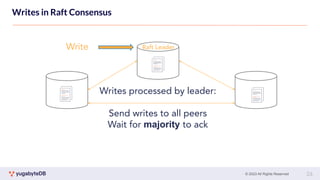
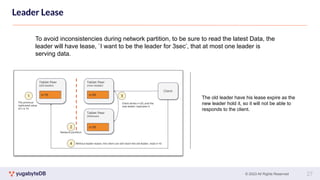


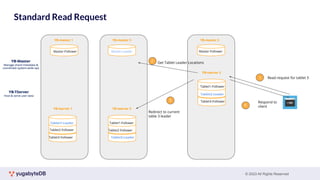
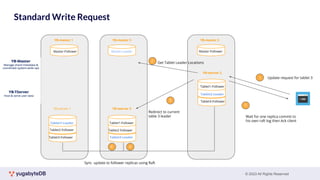

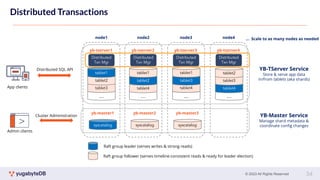
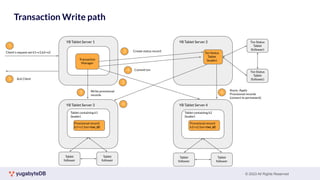
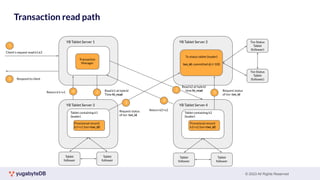


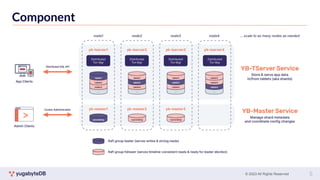
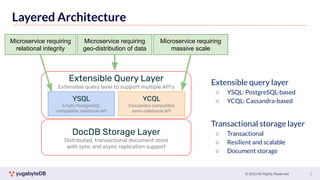
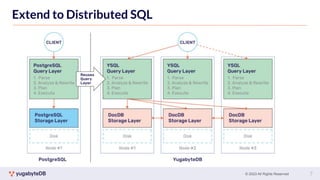
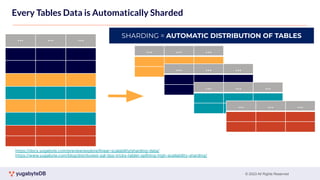
This document provides a summary of key concepts related to data sharding and replication in YugabyteDB. It discusses three methods for sharding data across tablets: pre-splitting tablets at table creation, manual splitting of tablets at runtime, and automatic splitting of tablets as they grow beyond a size threshold. It also explains how YugabyteDB uses Raft consensus for replication, with tablets replicated across multiple nodes to provide fault tolerance. Transaction processing is achieved by writing provisional records to leader tablets and committing transactions once a majority is reached.




















































![How Big Brands are Taking Your Traffic in Alberta [Data Inside].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/howbigbrandsaretakingyourtrafficinalbertadatainside-260123180142-42d276f3-thumbnail.jpg?width=640&height=640&fit=bounds)