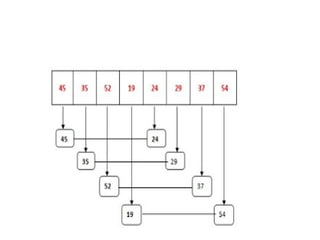
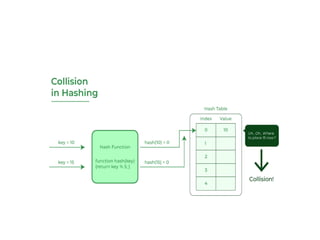
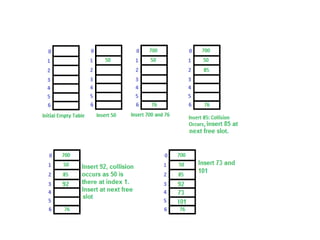
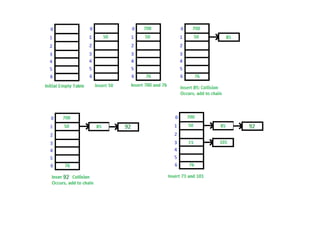
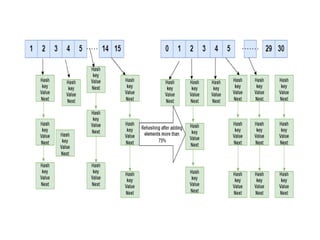
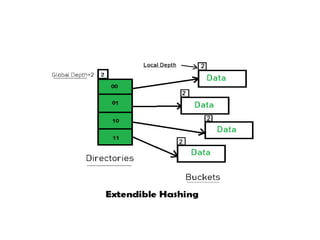
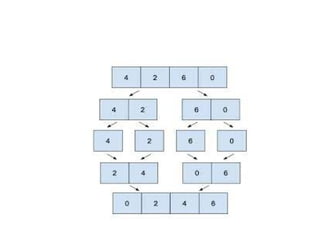
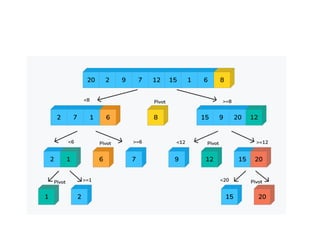
The document provides an in-depth overview of various sorting algorithms, including merge sort, quicksort, insertion sort, shell sort, and radix sort, highlighting their techniques and efficiency. It also covers hashing concepts, including hash functions, collision handling through methods like separate chaining and open addressing, and the rehashing process. Additionally, it discusses applications of these algorithms in areas such as symbol tables, caching, and databases.










![• PROCEDURE SHELL_SORT(ARRAY, N)
WHILE GAP < LENGTH(ARRAY) /3 :
GAP = ( INTERVAL * 3 ) + 1
END WHILE LOOP
WHILE GAP > 0 :
FOR (OUTER = GAP; OUTER < LENGTH(ARRAY); OUTER++):
INSERTION_VALUE = ARRAY[OUTER]
INNER = OUTER;
WHILE INNER > GAP-1 AND ARRAY[INNER – GAP] >=
INSERTION_VALUE:
ARRAY[INNER] = ARRAY[INNER – GAP]
INNER = INNER – GAP
END WHILE LOOP
ARRAY[INNER] = INSERTION_VALUE
END FOR LOOP](https://image.slidesharecdn.com/unitv-250109141320-e8868ce9/85/GRAPHS-BREADTH-FIRST-TRAVERSAL-AND-DEPTH-FIRST-TRAVERSAL-13-320.jpg)