Google Power Searching
구글검색 120% 활용하기
작성 : 임병현 AE / i4u networks
일자 : 2012.07.27
*아이포유네트웍스 : 소셜 미디어 전문 디지털 마케팅홍보 대행사로
정부/기업/브랜드/미디어/서비스 등의 고객사와 함께 하고 있습니다.
*들어가기에 앞서 본 내용은 Power Searching with Google 수업을 바탕으로 제작되어
영문 검색페이지가 기본이기에 한글 구글 검색 시 조금 다를 수 있는 점을 알려드립니다.
2.
1. 구글 검색프로세스_인터넷
• 방대한 양의 정보와 웹사이트
– 1995년 8월에는 18,000개에 불과했던 웹사이트의 수가 2011년 12월에는
555,482,744개로 증가
(Netcraft 조사. http://bit.ly/LQH2XQ)
– 이렇게 많은 웹사이트 중 구글은 어떻게 유저가 원하는 웹사이트를 검색하여
찾아주는 것일까?
3.
1. 구글 검색프로세스_웹 크롤러
• 웹 크롤러 (Web Crawler)
– 흔히 스파이더(Spider)라 불리는 웹 크롤러는 자동으로 인터넷을 탐색하며
각 웹사이트의 컨텐츠를 수집하는 프로그램
– 수집한 데이터는 인덱스(Index)라 불리며, 이 인덱스를 바탕으로 검색에 맞
는 웹사이트를 검색결과에 표시
(http://bit.ly/NZKmQ6)
4.
1. 구글 검색프로세스_페이지랭크
• 페이지랭크 (PageRank)
– 수많은 인덱스에서 무작위로 검색결과를 표시하지 않고 각 웹사이트를 인덱
싱할 시에 웹사이트에서 사용되는 단어, 링크 등을 바탕으로 점수를 부여하는
시스템
– 래리 페이지(Larry Page)와 세르게이 브린(Sergey Brin)이 개발한 알고리즘
이며 이를 바탕으로 높은 페이지랭크를 가지고 있는 웹사이트가 우선적으로
검색결과에 표시
5.
2. 검색 쿼리
•쿼리 (Query)
– 쿼리란 흔히 유저가 검색창에 입력하는 단어 또는 문장 등을 부르는 명칭
– 검색엔진은 쿼리에서 사용된 단어(동의어 포함)을 바탕으로 인덱스를 검색하
게되므로 어떤 단어들을 조합하여 쿼리를 만드느냐가 중요
• 구글 권장 방법
① 무엇을 찾고 싶은지 정확히 정하라
② 글로 썼을 때 어떻게 표현될지 생각하라
③ 본인이 실제로 관련된 내용을 작성한 글쓴이라고 상상하여 단어와 문장을
선택하라
???
6.
2. 검색 쿼리_예1
•아이의 팔이 부러져 어떻게 대처해야 하나 검색을 하고 싶을 때 어떤 쿼리
를 사용해야 할까?
– Busted Arm (부서진 팔)
– Broken Arm (부러진 팔)
• 위 표현 모두 ‘부러진 팔’을 뜻하는 쿼리지만, 전자의 경우 전문적인 표현
이 아니므로 후자로 검색을 하였을 경우 더 알맞은 검색결과가 표시
*후자인 [Broken Arm]으로 검색한 경우 의학적 검색결과가 표시됨
7.
2. 검색 쿼리_예2
•샌프란시스코 베이에 있던 옛 도시의 명칭을 알고 싶어 검색을 하고 싶다.
아무런 사전 지식이 없어 막막한데, 어떻게 해야 할까?
– 이럴 때는 몇 번의 검색을 통해 쿼리를 수정하는 방법으로 원하는 결과 검색
• 먼저, [what was the old city in san francisco bay called?] 로 검색을
해보자
*정확한 명칭이 나오지 않는다
• 예전에 존재했던 도시를 부르는 다른 단어인 ‘ghost town (유령 도시)’
로 바꿔서 검색을 해보자
*Drawbridge라는 명칭이 검색되었다
8.
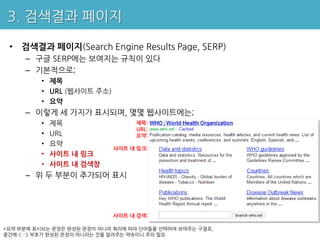
3. 검색결과 페이지
• 검색결과 페이지(Search Engine Results Page, SERP)
– 구글 SERP에는 보여지는 규칙이 있다
– 기본적으로;
• 제목
• URL (웹사이트 주소)
• 요약
– 이렇게 세 가지가 표시되며, 몇몇 웹사이트에는;
• 제목 제목:
URL:
• URL 요약:
• 요약
사이트 내 링크:
• 사이트 내 링크
• 사이트 내 검색창
– 위 두 부분이 추가되어 표시
사이트 내 검색:
*요약 부분에 표시되는 문장은 완성된 문장이 아니라 쿼리에 따라 단어들을 선택하여 보여주는 구절로,
중간에 <…> 부호가 완성된 문장이 아니라는 것을 알려주는 약속이니 주의 필요
9.
4. 신빙성
• 구글검색결과에 표시되는 웹사이트들은 스파이더로 저장을 한 인덱스의
결과물일 뿐이므로 신빙성을 체크하는 것은 유저의 몫이다
• “페이지랭크=신빙성” 이 아니므로 검색결과 페이지에 상위노출이 됐다고
신빙성이 있는 페이지가 아니다
• 구글 추천 신빙성 체크 방법
1) URL 검사하기
• SERP에서 보여지는 URL만 체크하여도 뒤의 도메인 주소(예, *.edu, *.ac.kr 등)
를 통해 교육기관 페이지인지 블로그인지 쉽게 파악이 가능
2) 쿼리 보완하기
• 정확한 쿼리 입력으로 정확하고 신빙성 있는 자료 검색
– 예) 지구의 지름을 찾고 싶다면 지구가 타원체인 점을 감안하여 정확하게 [지구의 적도
지름] 과 같은 정확한 쿼리를 입력하라
3) 원하는 답을 쿼리로 사용하지 마라
• 원하는 답을 쿼리로 사용할 경우 해당 답이 오답일지라도 관련 웹사이트만 검색
이 되어 표시
– 예) [문어의 평균 길이 18인치] 라는 쿼리를 입력할 경우 문어의 평균 길이가 18인치라
고 작성되어 있는 페이지만 SERP에 표시됨
10.
5. 구글 컨텐츠검색
• 구글 제공 컨텐츠
a. Web – 웹
b. Image – 이미지
c. YouTube – 동영상 (유튜브)
d. Scholar – 학문
e. Blogs – 블로그
f. Patents – 특허권
– 등 다양한 컨텐츠가 검색 가능
– 위 컨텐츠는 검색창의 왼쪽, 또는 상단의 툴바에서 선택 가능
• 이 중 특정 컨텐츠만을 검색하고 싶으면 해당 컨텐츠 링크를 클릭하여 검
색결과를 필터링하거나 검색창에서 [구글 이미지] 를 검색하여 해당 구
글 서비스로 이동하여 검색
11.
6. 구글 검색오퍼레이터_1
• 오퍼레이터
– 프로그래밍에서 흔히 사용되는 연산자
• 구글은 여러 검색 오퍼레이터를 제공하며, 이들을 활용하여 특정 웹사이
트만 검색하거나 원하는 형식의 파일을 찾을 수 있다
1. 특정 사이트 검색
– 아주 좋은 정보를 가지고 있는 사이트가 있는데 사이트 내 검색이 비활성화
되어있는 경우 유용
– 오퍼레이터 = [site:(사이트 주소)]
• 예) [tesla coil site:stanford.edu] – 다음 쿼리를 입력하면 스탠퍼드 대학교 내
에서 “tesla coil” 이라는 단어를 포함한 웹사이트를 검색하여 표시
– 이 오퍼레이터는 특정 도메인 검색에도 사용 가능
• 예) [tesla coil site:.gov] – 다음 쿼리를 검색 시 gov 도메인을 가진 모든 웹사이
트에서 “tesla coil” 단어 검색
– 주의 사항
• [site:gov] 와 [site:.gov] 같은 형식은 사용이 가능하나
[site: gov] 처럼 콜론 뒤에 띄어쓰기한 경우에는 작동하지 않음
12.
6. 구글 검색오퍼레이터_2
2. 특정 파일형식 찾기
– DOC, PPT 등 원하는 형식의 파일을 찾기 위해 사용되는 오퍼레이터
– 오퍼레이터 = [filetype:(파일 확장자)]
• 예) [tax rate filetype:csv] – 다음 쿼리를 입력 시 “tax rate” 에 관련된 CSV 형식
의 파일 검색
– 여러 개의 오퍼레이터를 동시에 사용하는 것도 가능
• 예) [tax rate filetype:csv site:gov] – 다음 쿼리 검색 시 GOV 도메인을 가진 웹
사이트 내에서 제공되는 “tax rate” 과 관련된 CSV 파일 검색
3. 단어 제외 오퍼레이터
– 특정 단어를 제외하고 검색하는 오퍼레이터
– 오퍼레이터 = [-(쿼리)]
• 예) 살사 소스를 검색하고 싶지만 살사춤도 있으므로 춤과 관련된 페이지는 제외
하고 싶을 시 [salsa –dancing] 과 같이 검색을 하며, 토마토를 사용하지 않은 살
사 소스를 검색하고 싶다면 [salsa –dancing –tomatoes] 를 사용
13.
6. 구글 검색오퍼레이터_3
4. 특정 구절 검색하기
– 시 구절이나 노래 가사는 생각이 나는데 제목이 생각이 안 날 경우 유용
– 오퍼레이터 = [“(쿼리)”]
• 예) [“when venus the goddess of beauty and love”] – 다음 쿼리를 사용하면
정확한 구절이 사용된 웹사이트만 검색
• 따옴표 오퍼레이터를 사용하지 않고 검색 시 단어의 순서를 무시하고 검색
14.
6. 구글 검색오퍼레이터_4
5. 여러 단어 한 번에 검색하기
– 원하는 결과를 얻기 위해 더 많은 단어를 사용하여, 예를 들면 동의어를 함께
검색하고 싶은 경우 활용
– 오퍼레이터 = [(쿼리) OR (쿼리)]
• 예) “Tesla Coil (테슬라 코일)” 에 관련된 정보를 찾고 싶다면 더 많은 검색결과에
서 원하는 정보를 찾기 위해 테슬라 코일의 다른 이름인 “Jacob’s Ladder” 를 함께
검색해보자
[“tesla coil” OR “jacob’s ladder”]
– 주의 사항
• [OR] 오퍼레이터는 대문자로 입력하였을 때만 작동
15.
6. 구글 검색오퍼레이터_5
6. 특정 단어 포함해 검색하기
– 쿼리와 함께 사용된 단어까지 포함시켜서 검색하고 싶은 경우
– 오퍼레이터 = [intext:(단어)]
• 예) 산호 탈색현상 (coral bleaching)에 관련된 문서를 스탠퍼드 대학교 웹사이트
에서 검색을 하고 싶은데 “지구 물리학(geophysics)” 란 단어가 꼭 포함된 페이지
를 찾고 싶은 경우
[“coral bleaching” site:stanford.edu intext:geophycis]
• 이처럼 [intext]로 단어를 포함시켜서 검색
7. 기타
– 오퍼레이터 기능은 순서와 상관없이 작동
• 예) [tax rate site:gov] = [site:gov tax rate]
[“coral bleaching” site:stanford.edu intext:geophycis]
= [site:stanford.edu “coral bleaching” intext:geophycis]
– 모든 오퍼레이터 기능은 구글 고급 검색 옵션에서도 편리하게 사용 가능
16.
7. 구글 검색추가 기능_1
• 자동 완성 기능
– 계속해서 축적되는 검색 관련 데이터를 바탕으로 제공하는 기능
– 여러 유저가 과거에 사용한 쿼리가 자동으로 보이기 때문에 더 적합한 쿼리를
발견할 수도 있기에 좀 더 효율적인 검색이 가능
– SERP 하단에 보여지는 관련 검색 쿼리도 유용하게 사용 가능
17.
7. 구글 검색추가 기능_2
• 간편 검색 기능 (1)
– 단순 계산이나 단위 변환 등 중요 키워드를 사용하여 간편한 검색이 가능
• 예) 세네갈의 수도가 알고 싶다면
[capital senegal] 처럼 “capital”을 사용하여 간편하게 검색
– 우측에 제공되는 구글 추천
설명 박스를 통해 더욱 많은
관련 정보를 얻을 수 있음
– 링크도 함께 제공되므로 관심있는 유저들은 쉽게 추가 검색 가능
18.
7. 구글 검색추가 기능_3
• 간편 검색 기능 (2)
– 추가 간편 검색 키워드
[weather (지역)] – 날씨 정보
[time (지역)] – 날씨 정보
– [(항공편 명)] – 항공편 운항 정보 (예: [KE 086])
– [(단위) in (단위)] 형식을 사용하여 변환
• 예)
[32c in f] – 섭씨에서 화씨로 변환
[1cup in ml] – 컵을 밀리리터로 변환
19.
8. 구글 이미지검색 옵션_1
• 구글 이미지에서는 다양한 옵션을 제공하며 이를 활용하여 더 적합한 이
미지를 검색하는 것이 가능하다. 이를 “tesla” 를 예로 사용하여 배워보자
– 과학자 테슬라, 테슬라 코일, 그리고 자동차까지 다양한 이미지들이 검색
– 여기서 왼편에 있는 옵션 중 컬러 부분을 활용하여 원하는 이미지를 찾아보자
<- 색 구분 없음
<- 컬러 이미지
<- 흑백 이미지
<- 특정 색상 강조
20.
8. 구글 이미지검색 옵션_2
– 컬러 옵션을 사용할 경우 “빨강”을 선택하여 테슬라 자동차 이미지 위주로 검
색을 하거나 “흑백”을 선택하여 과학자 테슬라 초상화 등과 같은 이미지를 위
주로 검색하는 것이 가능하다
21.
8. 구글 이미지검색 옵션_3
– 또 다른 유용한 기능으로는 비슷한 이미지만을 검색해주는 “similar” 기능으
로, 예로 [cup]을 검색해보자
– 커피잔, 트로피 등 여러 종류의 이미지가 검색되어 나온다. 여기서 트로피 컵
만을 찾고 싶은 경우 “similar” 기능을 사용하면 된다.
트로피에 마우스를 올리면 “similar” 라고 쓰여진 링크가 보인다
이 링크를 클릭하게 되면 해당 이미지와 비슷한 이미지들만 필터링되어 보인다
22.
9. 마치며
구글 검색에는이번 자료에 포함되지 않은 더 많은 오퍼레이터와 기능이 사
용될 수 있습니다. 원하는 정보를 더욱 효율적으로 검색하기 위해서는 계속
해서 유저들도 공부를 할 필요가 있다고 생각합니다.
앞서 알려 드린 바와 같이 본 자료는 구글에서 제공한 <Power Searching
with Google> (powersearchingwithgoogle.com/) 수업을 바탕으로 작
성되었으며, 몇 가지 제외한 기능들도 있습니다. 더욱 자세히 배우고 싶으신
분은 해당 사이트로 가셔서 동영상 강의 시청을 추천해 드립니다.
궁금하신 부분은 작성자에게 이메일(limbh@i4unetworks.co.kr)로
보내주시기 바랍니다.




![2. 검색 쿼리_예1
• 아이의 팔이 부러져 어떻게 대처해야 하나 검색을 하고 싶을 때 어떤 쿼리
를 사용해야 할까?
– Busted Arm (부서진 팔)
– Broken Arm (부러진 팔)
• 위 표현 모두 ‘부러진 팔’을 뜻하는 쿼리지만, 전자의 경우 전문적인 표현
이 아니므로 후자로 검색을 하였을 경우 더 알맞은 검색결과가 표시
*후자인 [Broken Arm]으로 검색한 경우 의학적 검색결과가 표시됨](https://image.slidesharecdn.com/googlepowersearchingfinal-120727034332-phpapp02/85/Google-Power-Searching-120-6-320.jpg)
![2. 검색 쿼리_예2
• 샌프란시스코 베이에 있던 옛 도시의 명칭을 알고 싶어 검색을 하고 싶다.
아무런 사전 지식이 없어 막막한데, 어떻게 해야 할까?
– 이럴 때는 몇 번의 검색을 통해 쿼리를 수정하는 방법으로 원하는 결과 검색
• 먼저, [what was the old city in san francisco bay called?] 로 검색을
해보자
*정확한 명칭이 나오지 않는다
• 예전에 존재했던 도시를 부르는 다른 단어인 ‘ghost town (유령 도시)’
로 바꿔서 검색을 해보자
*Drawbridge라는 명칭이 검색되었다](https://image.slidesharecdn.com/googlepowersearchingfinal-120727034332-phpapp02/85/Google-Power-Searching-120-7-320.jpg)
![4. 신빙성
• 구글 검색결과에 표시되는 웹사이트들은 스파이더로 저장을 한 인덱스의
결과물일 뿐이므로 신빙성을 체크하는 것은 유저의 몫이다
• “페이지랭크=신빙성” 이 아니므로 검색결과 페이지에 상위노출이 됐다고
신빙성이 있는 페이지가 아니다
• 구글 추천 신빙성 체크 방법
1) URL 검사하기
• SERP에서 보여지는 URL만 체크하여도 뒤의 도메인 주소(예, *.edu, *.ac.kr 등)
를 통해 교육기관 페이지인지 블로그인지 쉽게 파악이 가능
2) 쿼리 보완하기
• 정확한 쿼리 입력으로 정확하고 신빙성 있는 자료 검색
– 예) 지구의 지름을 찾고 싶다면 지구가 타원체인 점을 감안하여 정확하게 [지구의 적도
지름] 과 같은 정확한 쿼리를 입력하라
3) 원하는 답을 쿼리로 사용하지 마라
• 원하는 답을 쿼리로 사용할 경우 해당 답이 오답일지라도 관련 웹사이트만 검색
이 되어 표시
– 예) [문어의 평균 길이 18인치] 라는 쿼리를 입력할 경우 문어의 평균 길이가 18인치라
고 작성되어 있는 페이지만 SERP에 표시됨](https://image.slidesharecdn.com/googlepowersearchingfinal-120727034332-phpapp02/85/Google-Power-Searching-120-9-320.jpg)
![5. 구글 컨텐츠 검색
• 구글 제공 컨텐츠
a. Web – 웹
b. Image – 이미지
c. YouTube – 동영상 (유튜브)
d. Scholar – 학문
e. Blogs – 블로그
f. Patents – 특허권
– 등 다양한 컨텐츠가 검색 가능
– 위 컨텐츠는 검색창의 왼쪽, 또는 상단의 툴바에서 선택 가능
• 이 중 특정 컨텐츠만을 검색하고 싶으면 해당 컨텐츠 링크를 클릭하여 검
색결과를 필터링하거나 검색창에서 [구글 이미지] 를 검색하여 해당 구
글 서비스로 이동하여 검색](https://image.slidesharecdn.com/googlepowersearchingfinal-120727034332-phpapp02/85/Google-Power-Searching-120-10-320.jpg)
![6. 구글 검색 오퍼레이터_1
• 오퍼레이터
– 프로그래밍에서 흔히 사용되는 연산자
• 구글은 여러 검색 오퍼레이터를 제공하며, 이들을 활용하여 특정 웹사이
트만 검색하거나 원하는 형식의 파일을 찾을 수 있다
1. 특정 사이트 검색
– 아주 좋은 정보를 가지고 있는 사이트가 있는데 사이트 내 검색이 비활성화
되어있는 경우 유용
– 오퍼레이터 = [site:(사이트 주소)]
• 예) [tesla coil site:stanford.edu] – 다음 쿼리를 입력하면 스탠퍼드 대학교 내
에서 “tesla coil” 이라는 단어를 포함한 웹사이트를 검색하여 표시
– 이 오퍼레이터는 특정 도메인 검색에도 사용 가능
• 예) [tesla coil site:.gov] – 다음 쿼리를 검색 시 gov 도메인을 가진 모든 웹사이
트에서 “tesla coil” 단어 검색
– 주의 사항
• [site:gov] 와 [site:.gov] 같은 형식은 사용이 가능하나
[site: gov] 처럼 콜론 뒤에 띄어쓰기한 경우에는 작동하지 않음](https://image.slidesharecdn.com/googlepowersearchingfinal-120727034332-phpapp02/85/Google-Power-Searching-120-11-320.jpg)
![6. 구글 검색 오퍼레이터_2
2. 특정 파일형식 찾기
– DOC, PPT 등 원하는 형식의 파일을 찾기 위해 사용되는 오퍼레이터
– 오퍼레이터 = [filetype:(파일 확장자)]
• 예) [tax rate filetype:csv] – 다음 쿼리를 입력 시 “tax rate” 에 관련된 CSV 형식
의 파일 검색
– 여러 개의 오퍼레이터를 동시에 사용하는 것도 가능
• 예) [tax rate filetype:csv site:gov] – 다음 쿼리 검색 시 GOV 도메인을 가진 웹
사이트 내에서 제공되는 “tax rate” 과 관련된 CSV 파일 검색
3. 단어 제외 오퍼레이터
– 특정 단어를 제외하고 검색하는 오퍼레이터
– 오퍼레이터 = [-(쿼리)]
• 예) 살사 소스를 검색하고 싶지만 살사춤도 있으므로 춤과 관련된 페이지는 제외
하고 싶을 시 [salsa –dancing] 과 같이 검색을 하며, 토마토를 사용하지 않은 살
사 소스를 검색하고 싶다면 [salsa –dancing –tomatoes] 를 사용](https://image.slidesharecdn.com/googlepowersearchingfinal-120727034332-phpapp02/85/Google-Power-Searching-120-12-320.jpg)
![6. 구글 검색 오퍼레이터_3
4. 특정 구절 검색하기
– 시 구절이나 노래 가사는 생각이 나는데 제목이 생각이 안 날 경우 유용
– 오퍼레이터 = [“(쿼리)”]
• 예) [“when venus the goddess of beauty and love”] – 다음 쿼리를 사용하면
정확한 구절이 사용된 웹사이트만 검색
• 따옴표 오퍼레이터를 사용하지 않고 검색 시 단어의 순서를 무시하고 검색](https://image.slidesharecdn.com/googlepowersearchingfinal-120727034332-phpapp02/85/Google-Power-Searching-120-13-320.jpg)
![6. 구글 검색 오퍼레이터_4
5. 여러 단어 한 번에 검색하기
– 원하는 결과를 얻기 위해 더 많은 단어를 사용하여, 예를 들면 동의어를 함께
검색하고 싶은 경우 활용
– 오퍼레이터 = [(쿼리) OR (쿼리)]
• 예) “Tesla Coil (테슬라 코일)” 에 관련된 정보를 찾고 싶다면 더 많은 검색결과에
서 원하는 정보를 찾기 위해 테슬라 코일의 다른 이름인 “Jacob’s Ladder” 를 함께
검색해보자
[“tesla coil” OR “jacob’s ladder”]
– 주의 사항
• [OR] 오퍼레이터는 대문자로 입력하였을 때만 작동](https://image.slidesharecdn.com/googlepowersearchingfinal-120727034332-phpapp02/85/Google-Power-Searching-120-14-320.jpg)
![6. 구글 검색 오퍼레이터_5
6. 특정 단어 포함해 검색하기
– 쿼리와 함께 사용된 단어까지 포함시켜서 검색하고 싶은 경우
– 오퍼레이터 = [intext:(단어)]
• 예) 산호 탈색현상 (coral bleaching)에 관련된 문서를 스탠퍼드 대학교 웹사이트
에서 검색을 하고 싶은데 “지구 물리학(geophysics)” 란 단어가 꼭 포함된 페이지
를 찾고 싶은 경우
[“coral bleaching” site:stanford.edu intext:geophycis]
• 이처럼 [intext]로 단어를 포함시켜서 검색
7. 기타
– 오퍼레이터 기능은 순서와 상관없이 작동
• 예) [tax rate site:gov] = [site:gov tax rate]
[“coral bleaching” site:stanford.edu intext:geophycis]
= [site:stanford.edu “coral bleaching” intext:geophycis]
– 모든 오퍼레이터 기능은 구글 고급 검색 옵션에서도 편리하게 사용 가능](https://image.slidesharecdn.com/googlepowersearchingfinal-120727034332-phpapp02/85/Google-Power-Searching-120-15-320.jpg)
![7. 구글 검색 추가 기능_2
• 간편 검색 기능 (1)
– 단순 계산이나 단위 변환 등 중요 키워드를 사용하여 간편한 검색이 가능
• 예) 세네갈의 수도가 알고 싶다면
[capital senegal] 처럼 “capital”을 사용하여 간편하게 검색
– 우측에 제공되는 구글 추천
설명 박스를 통해 더욱 많은
관련 정보를 얻을 수 있음
– 링크도 함께 제공되므로 관심있는 유저들은 쉽게 추가 검색 가능](https://image.slidesharecdn.com/googlepowersearchingfinal-120727034332-phpapp02/85/Google-Power-Searching-120-17-320.jpg)
![7. 구글 검색 추가 기능_3
• 간편 검색 기능 (2)
– 추가 간편 검색 키워드
[weather (지역)] – 날씨 정보
[time (지역)] – 날씨 정보
– [(항공편 명)] – 항공편 운항 정보 (예: [KE 086])
– [(단위) in (단위)] 형식을 사용하여 변환
• 예)
[32c in f] – 섭씨에서 화씨로 변환
[1cup in ml] – 컵을 밀리리터로 변환](https://image.slidesharecdn.com/googlepowersearchingfinal-120727034332-phpapp02/85/Google-Power-Searching-120-18-320.jpg)


![8. 구글 이미지 검색 옵션_3
– 또 다른 유용한 기능으로는 비슷한 이미지만을 검색해주는 “similar” 기능으
로, 예로 [cup]을 검색해보자
– 커피잔, 트로피 등 여러 종류의 이미지가 검색되어 나온다. 여기서 트로피 컵
만을 찾고 싶은 경우 “similar” 기능을 사용하면 된다.
트로피에 마우스를 올리면 “similar” 라고 쓰여진 링크가 보인다
이 링크를 클릭하게 되면 해당 이미지와 비슷한 이미지들만 필터링되어 보인다](https://image.slidesharecdn.com/googlepowersearchingfinal-120727034332-phpapp02/85/Google-Power-Searching-120-21-320.jpg)


![[야생의 땅: 듀랑고] 서버 아키텍처 - SPOF 없는 분산 MMORPG 서버](https://cdn.slidesharecdn.com/ss_thumbnails/public-140529222503-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



![[NDC 발표] 모바일 게임데이터분석 및 실전 활용](https://cdn.slidesharecdn.com/ss_thumbnails/20140529-140529031622-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



![쿠키런: 킹덤 대규모 인프라 및 서버 운영 사례 공유 [데브시스터즈 - 레벨 200] - 발표자: 용찬호, R&D 엔지니어, 데브시스터즈 ...](https://cdn.slidesharecdn.com/ss_thumbnails/t3s3-221108102039-c0f48289-thumbnail.jpg?width=640&height=640&fit=bounds)















![[NDC2016] TERA 서버의 Modern C++ 활용기](https://cdn.slidesharecdn.com/ss_thumbnails/v09teramodernc20160425-160427044156-thumbnail.jpg?width=640&height=640&fit=bounds)










![[무료] 시스템해킹(해커스쿨문제풀이) 공개버전](https://cdn.slidesharecdn.com/ss_thumbnails/random-150918071120-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)













![[제12회 인터넷 리더십] 온라인 네트워크를 전략적 홍보_검색_전은서](https://cdn.slidesharecdn.com/ss_thumbnails/041821-140424032159-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



![[4차]구글 알고리즘 분석(151106)](https://cdn.slidesharecdn.com/ss_thumbnails/4-151106-160217170051-thumbnail.jpg?width=640&height=640&fit=bounds)
































