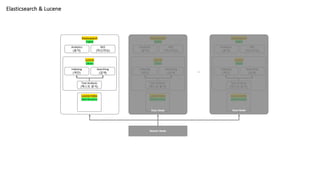
Elasticsearch & Lucene
Lucene
Library
Searching
(검색)
Indexing
(색인)
TextAnalysis
(텍스트 분석)
M/L
(머신러닝)
Analytics
(분석)
Elasticsearch
Engine
Lucene Index
Data Structure
Lucene
Library
Searching
(검색)
Indexing
(색인)
Text Analysis
(텍스트 분석)
M/L
(머신러닝)
Analytics
(분석)
Elasticsearch
Engine
Lucene Index
Data Structure
Lucene
Library
Searching
(검색)
Indexing
(색인)
Text Analysis
(텍스트 분석)
M/L
(머신러닝)
Analytics
(분석)
Elasticsearch
Engine
Lucene Index
Data Structure
Data Node Data Node
…
Master Node
5.
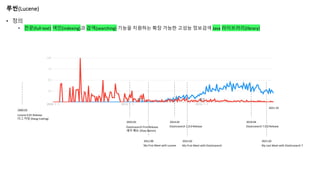
루씬(Lucene)
• 정의
• 전문(full-text)색인(indexing)과 검색(searching) 기능을 지원하는 확장 가능한 고성능 정보검색 Java 라이브러리(library)
Elasticsearch First Release
새이 베논 (Shay Banon)
2021.10
2010.02 2014.02
Elasticsearch 1.0.0 Release
Lucene 0.01 Release
더그 커팅 (Doug Cutting)
2000.03
2015.02
My First Meet with Elasticsearch
2012.00
My First Meet with Lucene
2019.04
Elasticsearch 7.0.0 Release
2021.02
My Last Meet with Elasticsearch 7
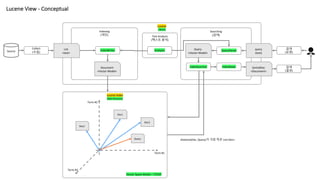
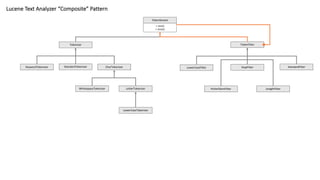
Lucene View -Conceptual
Lucene
Library
Searching
(검색)
Indexing
(색인) Text Analysis
(텍스트 분석)
Source
Collect
(수집)
List
<text>
Document
<Vector Model>
Lucene Index
Data Structure
IndexWriter
IndexSearcher IndexReaer
검색
(요청)
QueryParser
Query
<Vector Model>
query
(text)
Analyzer
SortedDoc
<Document>
Term #1
Term #2
Term #3
Doc1
Doc3
Doc2
Query
Vector Space Model – TF/IDF
distance(Doc, Query)가 가장 작은 List<Doc>
검색
(결과)
8.
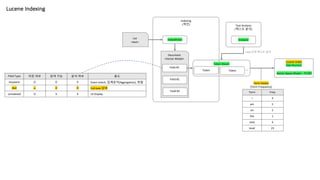
Lucene Indexing
Indexing
(색인) TextAnalysis
(텍스트 분석)
List
<text>
Document
<Vector Model>
IndexWriter Analyzer
Field #1
Token Token
Token Steam
…
Field #2
Field #3
Lucene Index
Data Structure
Filed Type 저장 여부 검색 가능 분석 여부 용도
keyword O O X Exact-match, 집계분석(Aggregation), 정렬
text △ O O Full-text 검색
unindexed O X X UI Display
Field 단위 텍스트 분석
Vector Space Model – TF/IDF
Term Freq
i 3
am 5
on 2
the 1
next 4
level 23
Term Vector
(Term Frequency)
9.
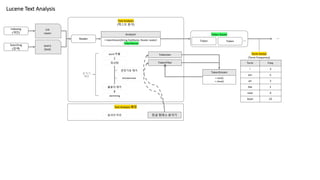
Lucene Text Analysis
TextAnalysis
(텍스트 분석)
List
<text>
query
(text)
Analyzer
+ tokenStream(String fieldName, Reader reader)
: TokenSteram
Searching
(검색)
Indexing
(색인)
TokenStream
+ next()
+ close()
Tokenizer
TokenFilter
Token Token
Token Steam
…
Reader
word 추출
정규화
문장기호 제거
toLowercase
불용어 제거
stemming
…
Term Freq
i 3
am 5
on 2
the 1
next 4
level 23
Term Vector
(Term Frequency)
Text Analysis 확장
동의어 처리 한글 형태소 분석기
…
분석기
체인
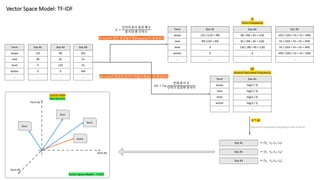
Vector Space Model:TF-IDF
Term
aespa
next
level
winter
…
Doc #1
132
90
0
0
…
TF
(Term Frequency)
Doc #2
98
95
120
0
…
Doc #3
103
55
55
349
…
TF: Term이 많이 등장할수록(Frequent) 더 중요하다
Term
aespa
next
level
winter
…
Doc #1
132 / (132 + 90)
90/ (132 + 90)
0
0
…
Doc #2
98 / (98 + 95 + 120)
95 / (98 + 95 + 120)
120 / (98 + 95 + 120)
0
…
Doc #3
103 / (103 + 55 + 55 + 349)
55 / (103 + 55 + 55 + 349)
55 / (103 + 55 + 55 + 349)
349 / (103 + 55 + 55 + 349)
…
Term
aespa
next
level
winter
…
Doc #1
log(3 / 3)
log(3 / 3)
log(3 / 2)
log(3 / 1)
…
IDF: Term이 등장한 문서가 작을수록(IDF) 더 중요하다
IDF
(Inverse Document Frequency)
t" =
단어의 문서 등장 횟수
문서의 총 단어수
$%" = &'(
전체 문서 수
단어가 등장한 문서수
tf * idf
Doc #1 = (*+, *-, *., */)
Doc #2 = (*+, *-, *., */)
Doc #3 = (*+, *-, *., */)
Vectorize of documents according to axis of terms
Lucene Index
Data Structure
Term #1
Term #2
Term #3
Doc1
Doc3
Doc2
Query
Vector Space Model – TF/IDF
12.
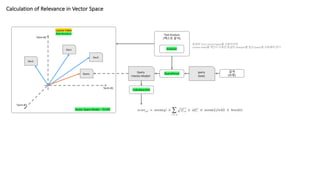
Calculation of Relevancein Vector Space
Lucene Index
Data Structure
Term #1
Term #2
Term #3
Doc1
Doc3
Doc2
Query
Vector Space Model – TF/IDF
IndexSearcher
검색
(요청)
QueryParser
Query
<Vector Model>
query
(text)
Text Analysis
(텍스트 분석)
Analyzer
동일한 Term Vector Space를 사용하려면
Lucene Index를 색인시 사용한 동일한 Analyzer를 질의 Query에 사용해야 한다
13.
True
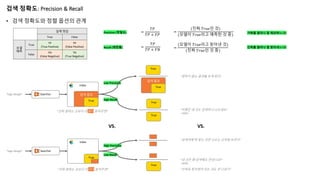
검색 정확도: Precision& Recall
• 검색 정확도와 정렬 옵션의 관계
실제 정답
True False
모델
예측
True
TP
(True Positive)
FP
(False Positive)
False
FN
(False Negative)
TN
(True Negative)
Precision (정밀도)
Recall (재현율)
=
"#
"# + %#
=
"#
"# + %&
=
(진짜 "()*인 것)
(모델이 "()*라고 예측한 것 중)
=
(모델이 "()*라고 찾아낸 것)
(진짜 "()*인 것 중)
가짜를 얼마나 잘 제외하느냐?
진짜를 얼마나 잘 찾아내느냐?
Searcher
Index
“logo design” 검색 결과
True
검색 결과
True
True
True
True
Searcher
Index
“logo design”
True
Low Precision
High Recall
High Precision
Low Recall
“진짜 원하는 것보다 더 많이 찾아주면”
“진짜 원하는 것보다 더 적게 찾아주면”
“원하지 않는 결과를 보게 된다”
“어쨌든 내 것도 검색하니 나오네요”
- Seller -
“검색어에 딱 맞는 것만 나오는 것처럼 보인다”
“내 것은 왜 검색해도 안되나요?”
- Seller
“진짜로 찾아줘야 되는 것도 안 나온다”
VS. VS.
14.
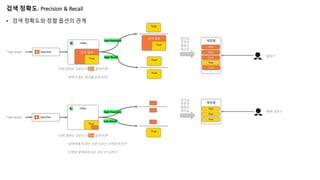
True
검색 정확도: Precision& Recall
• 검색 정확도와 정렬 옵션의 관계
Searcher
Index
“logo design” 검색 결과
True
검색 결과
True
True
True
True
Searcher
Index
“logo design”
True
Low Precision
High Recall
High Precision
Low Recall
“진짜 원하는 것보다 더 많이 찾아주면”
“진짜 원하는 것보다 더 적게 찾아주면”
“원하지 않는 결과를 보게 된다”
“검색어에 딱 맞는 것만 나오는 것처럼 보인다”
“진짜로 찾아줘야 되는 것도 안 나온다”
재정렬
True
False
False
False
False
재정렬
True
True
True
인기순
추천순
평점순
최신순
인기순
추천순
평점순
최신순
…
“뭥미 ?”
“뻔한 것만 ?”
15.
Relevance Model
• 벡터공간 모델 (Vector Space Model)
• 쿼리와 문서를 고차원 공간의 벡터로 표현
• 두 벡터 사이의 거리를 계산하여 관련성을 Scoring 함
• 예시
• TF/IDF 기반의 Full-text 검색
• 불린 모델 (Boolean Model)
• 쿼리에 문서가 해당하는지 아닌지 (True or False) 만을 판단
• 관련성에 대한 Scoring을 하지 않음
• 예시
• Elasticsearch의 TermQuery를 이용한 Exact Value Match
• 확률 모델 (Probabilistic Model)
• 질의와 문서가 일치하는 확률을 계산
• 예시
• BM25 기반의 Full-text 검색
자세한 내용은 아래 참조
BM25 – Elasticsearch 5.0에서 검색하는 새로운 방법 https://popit.kr/bm25-elasticsearch-5-0%ec%97%90%ec%84%9c-%ea%b2%80%ec%83%89%ed%95%98%eb%8a%94-%ec%83%88%eb%a1%9c%ec%9a%b4-%eb%b0%a9%eb%b2%95/
16.
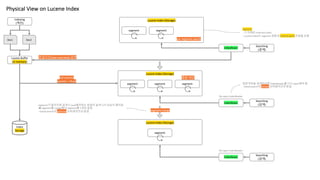
Physical View onLucene Index
Doc1 Doc2
Index
Storage
Lucene Index (Storage)
segment segment
Lucene Buffer
(in-memory)
Lucene Index (Storage)
segment segment segment
Indexing
(색인)
IndexReaer
Searching
(검색)
IndexReaer
Searching
(검색)
준실시간(near-real time) 검색
증분 색인
full-commit
commit + flush
Re-open IndexReader
Lucene Index (Storage)
segment
IndexReaer
Searching
(검색)
Re-open IndexReader
segment merge
증분색인을 검색하려면 IndexReader를 다시 open해야 함
- Elasticsearch의 refresh 오퍼레이션과 동일
segment가 많아지면 검색시 read해야하는 파일이 늘어나서 성능이 떨어짐
è segment를 merge해서 segment를 1개로 합침
- Elasticsearch의 optimize 오퍼레이션과 동일
per segment search
segment
- 그 자체로 inverted index
- Lucene Index는 segment 집합과 commit point 파일을 포함
17.
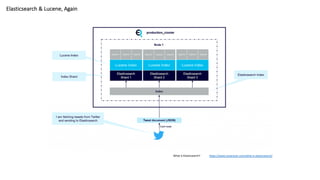
Elasticsearch & Lucene,Again
What is Elasticsearch? https://www.instaclustr.com/what-is-elasticsearch/
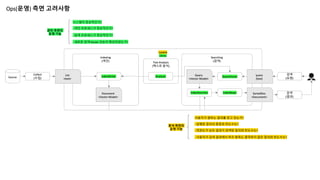
Ops(운영) 측면 고려사항
사용자가원하는 결과를 얻고 있는가?
- 색인 프로세스가 정상적인가?
- 검색 프로세스가 정상적인가?
- 새로운 검색 Model 성능이 향상되었는가?
시스템이 정상적인가?
- 실행된 질의의 종류와 빈도수는?
- 연관도가 낮은 결과가 검색된 질의와 빈도수는?
- 사용자가 검색 결과에서 하우 항목도 클릭하지 않은 질의와 빈도수는?
관리 측면의
운영 기능
분석 측면의
운영 기능
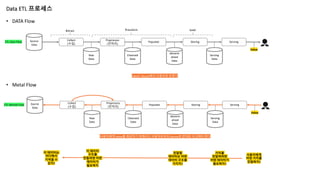
Data ETL 프로세스
Source
Data
Collect
(수집)
Preprocess
(전처리)
PopulateStoring Serving
ETL Data Flow
Extract Transform Load
Raw
Data
Cleansed
Data
denorm
alized
Data
Serving
Data
Value
• DATA Flow
• Metal Flow
Data는 Source에서 사용자로 흐른다
Source
Data
Collect
(수집)
Preprocess
(전처리)
Populate Storing Serving
ETL Mental Flow
Raw
Data
Cleansed
Data
denorm
alized
Data
Serving
Data
Value
사용자에게 Value를 제공하기 위해서는 사용자로부터 Source로 반대로 사고해야 한다
사용자에게
어떤 가치를
전달하지?
가치를
전달하려면
어떤 데이터가
필요하지?
전달할
데이터는 어떤
데이터 구조를
가지지?
이 데이터
구조를
만들려면 어떤
데이터가
필요하지
이 데이터는
어디에서
가져올 수
있지?
22.
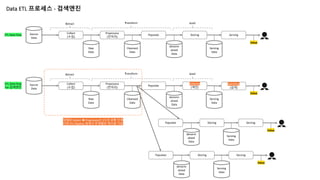
Data ETL 프로세스- 검색엔진
Source
Data
Collect
(수집)
Preprocess
(전처리)
Populate Storing Serving
ETL Data Flow
Extract Transform Load
Raw
Data
Cleansed
Data
denorm
alized
Data
Serving
Data
Value
Source
Data
Collect
(수집)
Preprocess
(전처리)
Populate
Indexing
(색인)
Searching
(검색)
ETL Data Flow
For 검색엔진
Extract Transform Load
Raw
Data
Cleansed
Data
denorm
alized
Data
Serving
Data
Value
Populate Storing Serving
denorm
alized
Data
Serving
Data
Value
Populate Storing Serving
denorm
alized
Data
Serving
Data
Value
대체로 Collect è Preprocess는 ETL의 공통 단계
다른 ETL Pipeline 설계시 주제별로 재사용 가능
23.
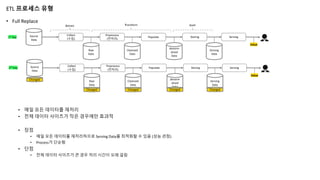
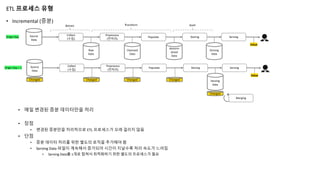
ETL 프로세스 유형
•Full Replace
• 매일 모든 데이터를 재처리
• 전체 데이터 사이즈가 작은 경우에만 효과적
• 장점
• 매일 모든 데이터를 재처리하므로 Serving Data를 최적화할 수 있음 (성능 관점)
• Process가 단순함
• 단점
• 전체 데이터 사이즈가 큰 경우 처리 시간이 오래 걸림
Source
Data
Collect
(수집)
Preprocess
(전처리)
Populate Storing Serving
1st
Day
Extract Transform Load
Raw
Data
Cleansed
Data
denorm
alized
Data
Serving
Data
Value
Source
Data
Collect
(수집)
Preprocess
(전처리)
Populate Storing Serving
2nd
Day
Raw
Data
Cleansed
Data
denorm
alized
Data
Serving
Data
Value
Changed
Changed Changed Changed Changed
24.
• Incremental (증분)
•매일 변경된 증분 데이터만을 처리
• 장점
• 변경된 증분만을 처리하므로 ETL 프로세스가 오래 걸리지 않음
• 단점
• 증분 데이터 처리를 위한 별도의 로직을 추가해야 함
• Serving Data 파일이 계속해서 증가되어 시간이 지날수록 처리 속도가 느려짐
• Serving Data를 1개로 합쳐서 최적화하기 위한 별도의 프로세스가 필요
ETL 프로세스 유형
Source
Data
Collect
(수집)
Preprocess
(전처리)
Populate Storing Serving
Origin Day
Extract Transform Load
Raw
Data
Cleansed
Data
denorm
alized
Data
Serving
Data
Value
Source
Data
Collect
(수집)
Preprocess
(전처리)
Populate Storing Serving
Origin Day + 1
Value
Changed Changed Changed Changed
Changed
Serving
Data
Merging
25.
검색서비스 구축을 위한TIP
• 검색하기 원하는 형태로 색인하라
• 색인 속도보다 검색 속도가 중요하다
• 검색 성능/품질이 색인 성능/품질보다 중요하다
• 검색이 목표이며 색인은 이를 달성하기 위한 수단이다
• 검색 서비스이지 색인 서비스가 아니다
• 하지만 색인 프로그램 개발에 더 많은 공수가 들어간다
• 색인 프로그램이 더 복잡하다
• 색인은 단 하나의 목표를 갖는다. 바로 사용자에게 제공할 검색 서비스의 품질이다
• 검색 기능을 구현하고자 할 때 필요한 모든 준비는 색인 과정에서 진행해야 한다
New
Doc
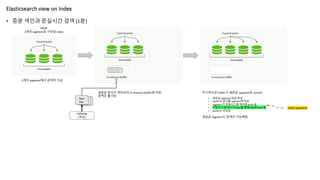
• 증분 색인과준실시간 검색 (1분)
Elasticsearch view on Index
NOW
3개의 segment로 구성된 index
Indexing
(색인)
New
Doc
New
Doc
3개의 segment에서 검색이 가능
새로운 문서가 색인되어 in-memory buffer에 저장
검색은 불가능
주기적으로 buffer가 새로운 segment로 commit
• 새로운 segment 파일 생성
• buffer의 문서를 segment에 저장
• segment가 파일시스템 캐시에 write 됨
• 파일시스템 캐시가 fsync를 통해 disk에 flush 됨
• buffer는 비워짐
새로운 segment도 검색이 가능해짐
costly operation
30.
New
Doc
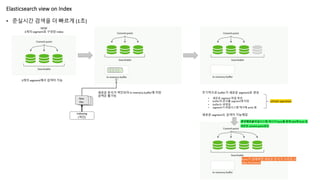
• 준실시간 검색을더 빠르게 (1초)
Elasticsearch view on Index
NOW
3개의 segment로 구성된 index
Indexing
(색인)
New
Doc
New
Doc
3개의 segment에서 검색이 가능
새로운 문서가 색인되어 in-memory buffer에 저장
검색은 불가능
주기적으로 buffer가 새로운 segment로 생성
• 새로운 segment 파일 생성
• buffer의 문서를 segment에 저장
• buffer는 비워짐
• segment가 파일시스템 캐시에 write 됨
새로운 segment도 검색이 가능해짐
주기적으로 파일시스템 캐시가 fsync를 통해 disk에 flush 됨
refresh operation
새로운 commit point생성
fsync가 실패하면 새로운 문서가 사라짐 !!!
(Not Persistent)
31.
New
Doc
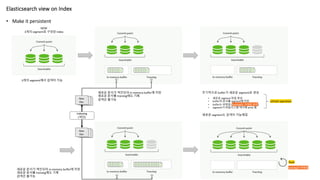
• Make itpersistent
Elasticsearch view on Index
NOW
3개의 segment로 구성된 index
Indexing
(색인)
New
Doc
New
Doc
3개의 segment에서 검색이 가능
주기적으로 buffer가 새로운 segment로 생성
• 새로운 segment 파일 생성
• buffer의 문서를 segment에 저장
• buffer는 비워짐 (translog는 그대로 유지)
• segment가 파일시스템 캐시에 write 됨
새로운 segment도 검색이 가능해짐
refresh operation
새로운 문서가 색인되어 in-memory buffer에 저장
새로운 문서를 translog에도 기록
검색은 불가능
New
Doc
New
Doc
New
Doc
새로운 문서가 색인되어 in-memory buffer에 저장
새로운 문서를 translog에도 기록
검색은 불가능
flush
translog는 비워짐
32.
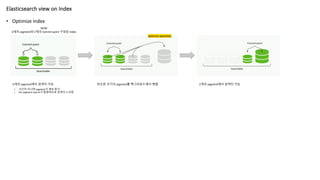
• Optimize Index
Elasticsearchview on Index
Searchable
Commit point
NOW
4개의 segment와 2개의 Commit point 구성된 index
4개의 segment에서 검색이 가능
• 시간이 지나면 segment가 계속 증가
• Per segment search가 발생하므로 검색이 느려짐
비슷한 크기의 segment를 백그라운드에서 병합 2개의 segment에서 검색이 가능
optimize operation
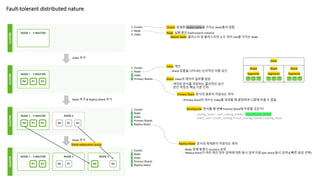
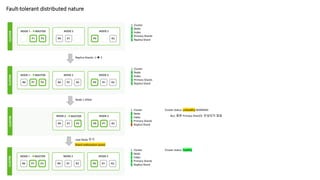
Fault-tolerant distributed nature
1Cluster
1 Node
0 Index
1 Cluster
1 Node
1 Index
3 Primary Shards
index 추가
Cluster: 동일한 cluster.name을 가지는 Node들의 집합
Node: 실행 중인 Elasticsearch instance
Index: 색인
Master Node: 클러스터 및 클러스터의 노드 관리 role을 가지는 Node
Shard: Index의 데이터 일부를 담당
Shard
Index
Shard Shard
Segments Segments Segments
- Shard 집합을 나타내는 논리적인 이름 공간
- 색인된 문서를 저장하는 물리적인 공간
- 분산 저장의 핵심 기본 단위
Primary Shard: 문서의 원본이 저장되는 위치
- Primary Shard의 개수는 Index를 생성할 때 결정하며 나중에 바꿀 수 없음
Replica Shard: 문서의 복제본이 저장되는 위치
- Node 장애 발생시 recovery 보장
- Replica Shard가 여러 개인 경우 검색에 대한 동시 검색 지원 (per-shard 동시 검색 & 빠른 응답 선택)
Node 추가 & Replica Shard 추가
1 Cluster
2 Node
1 Index
3 Primary Shards
1 Replica Shard
Node 추가
1 Cluster
3 Node
1 Index
3 Primary Shards
1 Replica Shard
Shard reallocation (auto)
routing_factor = num_routing_shards / num_primary_shards
shard_num = (hash(_routing) % num_routing_shards) / routing_factor
Routing rule: 문서를 몇 번째 Primary Shard에 저장할 것인가?
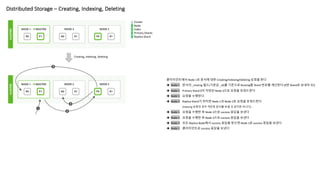
Distributed Storage –Creating, Indexing, Deleting
1 Cluster
3 Node
1 Index
2 Primary Shards
2 Replica Shard
클라이언트에서 Node 1로 문서에 대한 Creating/Indexing/Deleting 요청을 한다
è Node 1 문서의 _routing 필드(기본값 _id)를 기준으로 Routing할 Shard 번호를 계산한다 (0번 Shard로 보내야 되!)
è Node 1 Primary Shard 0이 저장된 Node 3으로 요청을 포워드한다
è Node 3 요청을 수행한다.
è Node 3 Replica Shard가 위치한 Node 1과 Node 2로 요청을 포워드한다
(Indexing 요청의 경우 색인된 문서를 보낼 것 같지만 아니다)
è Node 1 요청을 수행한 후 Node 3으로 success 응답을 보낸다
è Node 2 요청을 수행한 후 Node 3으로 success 응답을 보낸다
è Node 3 모든 Replica Node에서 success 응답을 받으면 Node 1로 success 응답을 보낸다
è Node 1 클라이언트로 success 응답을 보낸다
Creating, Indexing, Deleting
38.
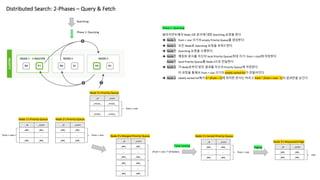
Distributed Search: 2-Phases– Query & Fetch
Searching
Phase 1: Querying
클라이언트에서 Node 3로 문서에 대한 Searching 요청을 한다
è Node 3 from + size 크기의 empty Priority Queue를 생성한다
è Node 3 모든 Node로 Searching 요청을 포워드한다
è Node * Searching 요청을 수행한다.
è Node * 매칭된 문서를 자신의 local Priority Queue(최대 크기: from + size)에 저장한다
Node * local Priority Queue를 Node 3으로 전달한다
è Node 3 각 Node로부터 받은 결과를 자신의 Priority Queue에 저장한다
이 과정을 통해서 from + size 크기의 totally sorted list가 만들어진다
è Node 3 totally sorted list에서 0 ~ (from – 1)에 위치한 문서는 버리고 from ~ (from + size - 1)의 결과만을 남긴다
Phase 1: Querying
_id _score
_empty_ _empty_
… …
_empty_ _empty_
from + size
_id _score
_###_ _###_
… …
_###_ _###_
from + size
_id _score
_###_ _###_
… …
_###_ _###_
from + size
_###_ _###_
… …
_###_ _###_
_id _score
_###_ _###_
… …
_###_ _###_
(from + size ) * (# Nodes)
_id _score
_###_ _###_
… …
_###_ _###_
from + size
_id _score
_###_ _###_
_###_ _###_
size
Node 3’s Priority Queue
Node 1’s Priority Queue Node 2’s Priority Queue
Node 3’s Merged Priority Queue Node 3’s Sorted Priority Queue
Node 3’s Requested Page
Total ranking Paging
39.
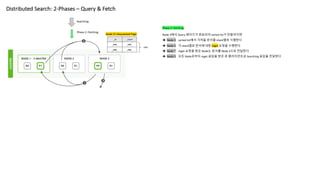
Distributed Search: 2-Phases– Query & Fetch
Searching
Phase 2: Fetching
Node 3에서 Query 페이즈가 완료되어 sorted list가 만들어지면
è Node 3 sorted list에서 가져올 문서를 shard별로 식별한다
è Node 3 각 shard별로 문서에 대한 mget 요청을 수행한다
è Node * mget 요청을 받은 Node는 문서를 Node 3으로 전달한다
è Node 3 모든 Node로부터 mget 응답을 받은 후 클라이언트로 Searching 응답을 전달한다
Phase 2: Fetching
_id _score
_###_ _###_
_###_ _###_
size
Node 3’s Requested Page
Query & FilterContext in Elasticsearch
주어진 질의에 대해 이 문서는 어느 정도 매칭이 되는가?
Query context
query document score(q, d): 관련성(relevance score)
”full text search”에 가장 잘 매칭된 문서는?
“run”을 포함하는 문서는?
“runs”, “running”, “jog”, “sprint”를 포함하는 문서도 매칭될 수 있어야 한다
“quick”, “brown”, “fox”를 포함하는 문서는?
이들 단어가 많이 등장할 수록, 그리고 단어들 사이가 가까울수록 더 높은 관련성을 가져야 한다
stemming synonyms
term frequency phrase matching
주어진 질의에 대해 이 문서는 질의를 포함하느냐 안하느냐?
Filter context
query document Yes or No
status 필드는 ”published”이냐 아니냐?
timestamp가 2015년과 2016년 사이이냐 아니냐?
기준 Query Filter
Data type text (analyzed) keyword
Matching Full-text Exact value
by Relevance Yes or No
Caching No Yes
속도 느림 빠름
Query vs Filter
42.
Synonyms Searching (동의어검색)
• 동의어 검색 범위
• 동의어와 유사어
• 유사한 의미와 아이디어
• light하게 사용하는 경우
• 사용자는 입력한 “질의어”와 검색 결과의 상관관계를 이해할 것
• aggressive하게 사용
• 사용자는 입력한 "질의어”와 검색 결과 사이의 상관관계를 발견하기
어려울 것
• 오히려 검색 결과가 입력한 “질의어”와 관련 없이 랜덤하다고 느낄 것
usa, united states, united states of america
english queen, british monarch
동의어 검색을 어디까지 허용할 것인가?
꼭 필요한 경우에만!
• 동의어 사전 규칙 유형
• 단순 확장 (Simple Expansion)
• 단순 축약 (Simple Contraction)
• 의미적 확장 (Genre Expansion)
jump, leap, hop
leap, hop => jump
Original terms: Replaced by:
---------------------------------------------------
jump => ( jump, leap, hop )
leap => ( jump, leap, hop )
hop => ( jump, leap, hop )
Original terms: Replaced by:
---------------------------------------------------
leap => ( jump )
hop => ( jump )
cat, pet, animal
kitten, cat, pet, animal
Original terms: Replaced by:
---------------------------------------------------
cat => ( cat, pet, animal )
kitten => ( kitten, cat, pet, animal )
43.
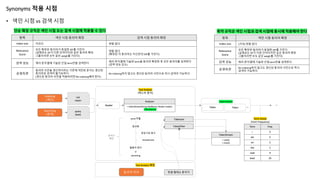
Synonyms 적용 시점
•색인 시점 vs 검색 시점
동의어 처리
Indexing
(색인)
Searching
(검색)
항목 색인 시점 동의어 확장 검색 시점 동의어 확장
Index size 커진다 변함 없다
Relevance
Score
모든 확장된 동의어가 동일한 IDF를 가진다
(실제로는 DF가 다른 단어이지만 같은 동의어 확장
그룹이라면 모두 같은 weigh를 가진다)
변함 없다
(확장된 각 동의어는 자신만의 IDF를 가진다)
검색 성능 쿼리 문자열에 기술된 단일 term만을 검색한다
쿼리 문자열에 기술된 term을 동의어 확장한 후 모든 동의어를 검색한다
(검색 성능 감소)
운영측면
동의어 사전을 갱신하더라도 기존에 색인된 문서는 갱신된
동의어로 검색이 불가능하다
(갱신된 동의어 사전을 적용하려면 Re-indexing해야 한다)
Re-indexing하지 않고도 갱신된 동의어 사전으로 즉시 검색이 가능하다
항목 색인 시점 동의어 확장
Index size (거의) 변함 없다
Relevance
Score
모든 확장된 동의어가 동일한 IDF를 가진다
(실제로는 DF가 다른 단어이지만 같은 동의어 확장
그룹이라면 모두 같은 weigh를 가진다)
검색 성능 쿼리 문자열에 기술된 단일 term만을 검색한다
운영측면
Re-indexing하지 않고도 갱신된 동의어 사전으로 즉시
검색이 가능하다
단순 확장 규칙은 색인 시점 또는 검색 시점에 적용할 수 있다 축약 규칙은 색인 시점과 검색 시점에 동시에 적용해야 한다
44.
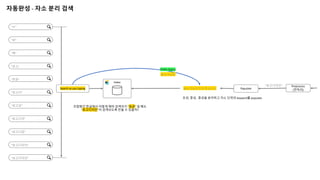
자동완성 - 자소분리 검색
“ㄹ”
“로”
“록”
“로고”
“로곧”
“로고디”
“로고딪”
“로고디자”
“로고디장”
“로고디자이”
“로고디자인”
Index
Search as you typing
조합형인 한글에서 어떻게 해야 검색어가 “로곧” 일 때도
“로고디자인”이 검색되도록 만들 수 있을까?
“로고디자인” Preprocess
(전처리)
Populate
ㄹㅗㄱㅗㄷㅣㅈㅏㅇㅣㄴ
초성, 중성, 종성을 분리하고 자소 단위의 keyword를 populate
Prefix Query
ㄹㅗㄱㅗㄷ
References
• Elasticsearch
• Elasticsearch적용 및 활용 정리 https://www.slideshare.net/JunyiSong1/elasticsearch-45936425
• Elasticsearch Guide https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
• BM25 – Elasticsearch 5.0에서 검색하는 새로운 방법 https://popit.kr/bm25-elasticsearch-5-0%ec%97%90%ec%84%9c-
%ea%b2%80%ec%83%89%ed%95%98%eb%8a%94-%ec%83%88%eb%a1%9c%ec%9a%b4-%eb%b0%a9%eb%b2%95/
• Elasticsearch: The Definitive Guide 2.x https://www.elastic.co/guide/en/elasticsearch/guide/master/search.html
• Lucene
• 루씬 인 액션(2005) 에이콘 출판사
• 루씬 인 액션(2013) 개정판 에이콘 출판사
• Machine Learning
• 처음 배우는 머신러닝 한빛미디어
• 검색 성능
• 데이터팀 검색성능 측정 https://kmongteam.atlassian.net/wiki/spaces/DEV/pages/2135589348
• 무신사: 검색어 분석을 통한 상품 정렬 개선 https://medium.com/musinsa-tech/%EA%B2%80%EC%83%89%EC%96%B4-
%EB%B6%84%EC%84%9D%EC%9D%84-%ED%86%B5%ED%95%9C-%EC%83%81%ED%92%88-%EC%A0%95%EB%A0%AC-%EA%B0%9C%EC%84%A0-
b92ded2923c3
• 무신사가 검색 품질을 관리하는 방법 https://medium.com/musinsa-tech/map-416b5f143943

























![[236] 카카오의데이터파이프라인 윤도영](https://cdn.slidesharecdn.com/ss_thumbnails/236-161025031702-thumbnail.jpg?width=640&height=640&fit=bounds)














![[Retail & CPG Day 2019] 마켓컬리 서비스 AWS 이관 및 최적화 여정 - 임상석, 마켓컬리 개발 리더](https://cdn.slidesharecdn.com/ss_thumbnails/kurly-191024042353-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[215]네이버콘텐츠통계서비스소개 김기영](https://cdn.slidesharecdn.com/ss_thumbnails/215-161025030904-thumbnail.jpg?width=640&height=640&fit=bounds)


![제 17회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [중고책나라] : 실시간 데이터를 이용한 Elasticsearch 클러스터 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/random-230220154251-7145ba84-thumbnail.jpg?width=640&height=640&fit=bounds)




