Download to read offline


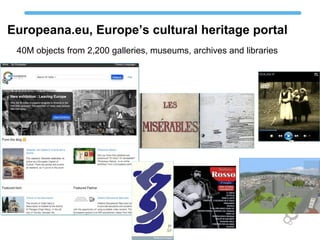
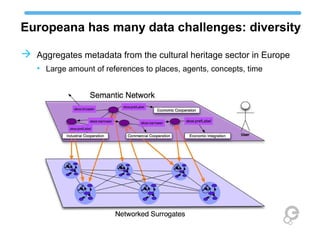
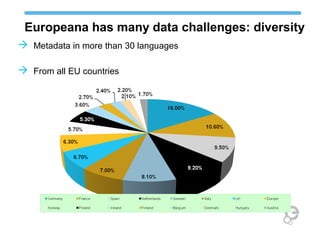


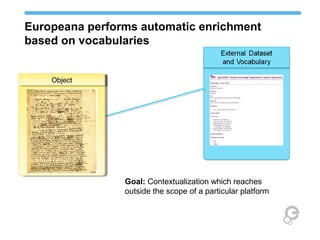
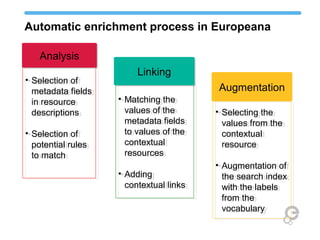
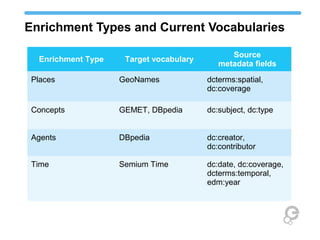
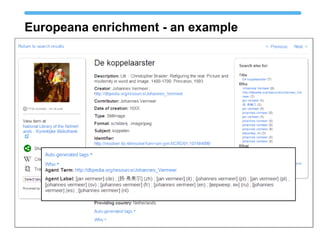








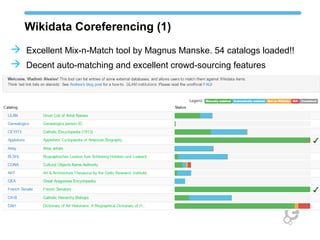










The document discusses Europeana's semantic strategy and its integration with Wikidata to enhance the quality and contextualization of cultural heritage data. It highlights Europeana's challenges in managing diverse multilingual metadata and discusses how it utilizes the Europeana Data Model (EDM) to improve data interlinking through semantic enrichment. The role of Wikidata as a significant source for authority control and multilingual coverage is emphasized, along with the potential for enriching Europeana's dataset with additional information from Wikipedia and other structured data sources.






































































































