Download as PDF, PPTX







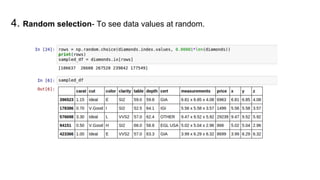
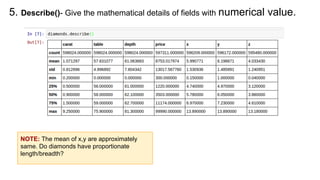
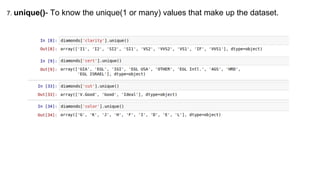

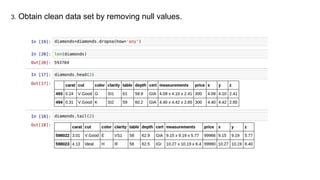
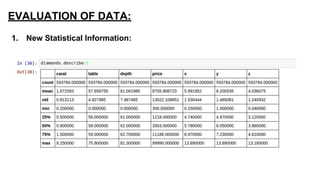
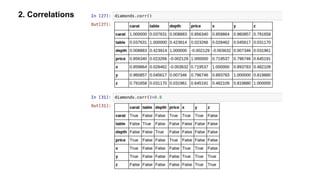
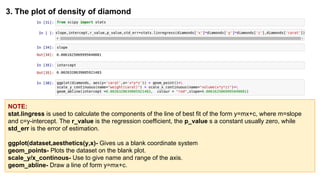
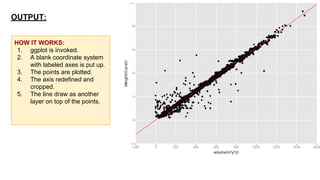

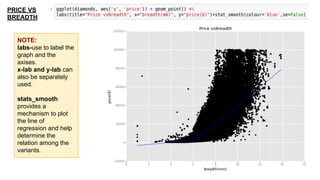
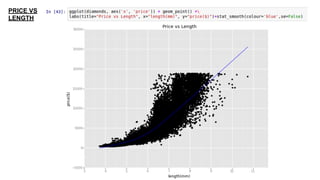
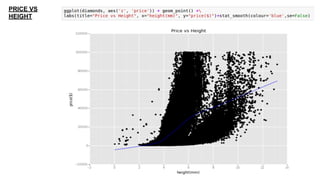
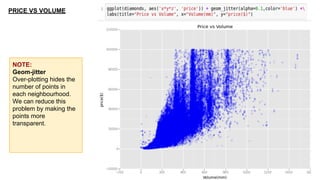
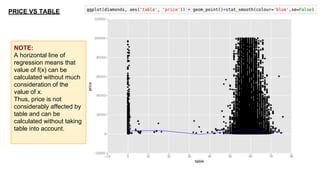
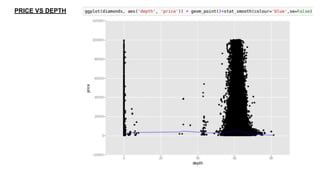
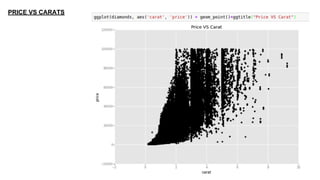
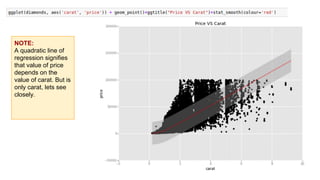
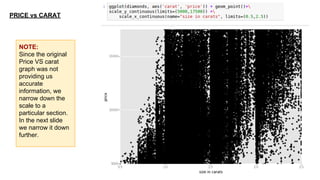
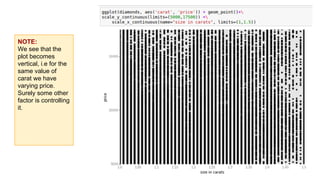
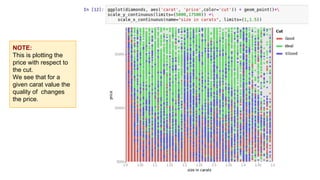
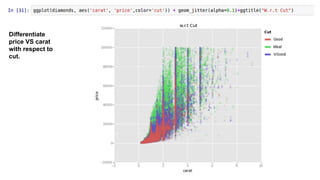
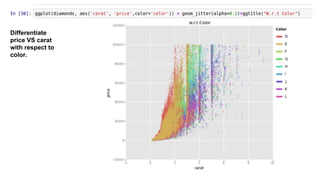
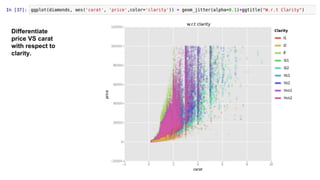
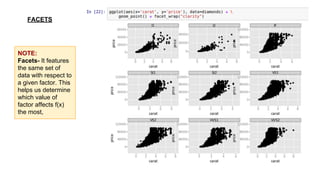




This document provides an introduction to using ggplot in Python. It discusses installing ggplot and importing necessary packages. It then uses a diamonds dataset to demonstrate how to explore the data, prepare it for analysis, evaluate relationships between variables like price and carat size, and use facets to differentiate results. The goal is to help beginners understand basic ggplot functions and how to visualize and analyze data.

























![[系列活動] Data exploration with modern R](https://cdn.slidesharecdn.com/ss_thumbnails/dataexplorationwithmodernr1221-161219044516-thumbnail.jpg?width=640&height=640&fit=bounds)


























![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)














