Downloaded 12 times



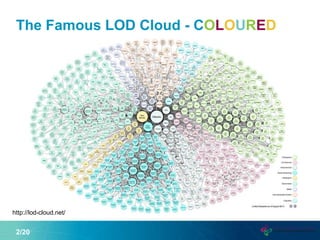
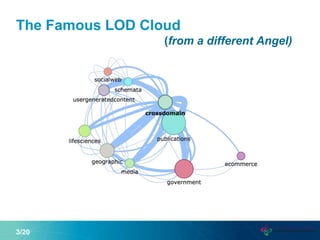
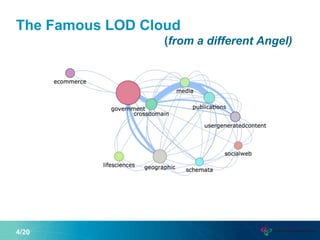
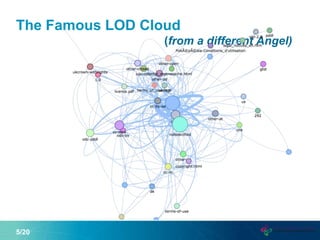


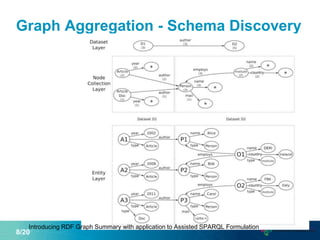









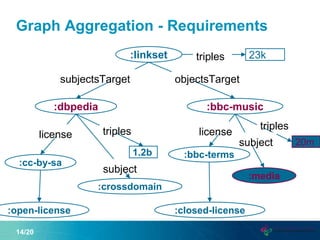





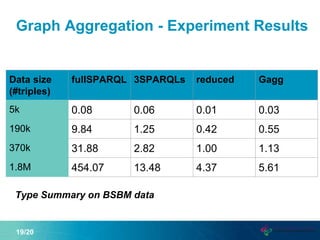

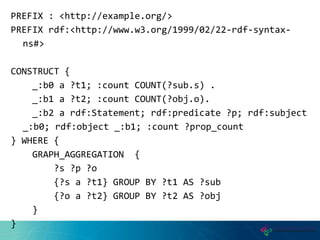
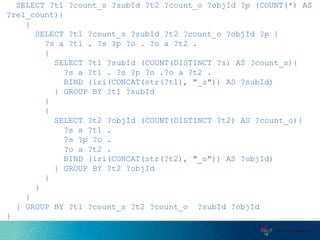

This document proposes a new graph aggregation operator called Gagg that can condense a large graph into a smaller structurally similar graph. Gagg operates in two steps, first grouping vertices based on dimensions like subject and object types, and then applying aggregation functions to compute metrics on the groups. The document evaluates an implementation of Gagg in Apache Jena and shows it can summarize graphs more efficiently than alternative approaches like custom SPARQL queries.











































































