Download as PDF, PPTX


!["type":"/type/object" is assumed
"name" = /type/object/name
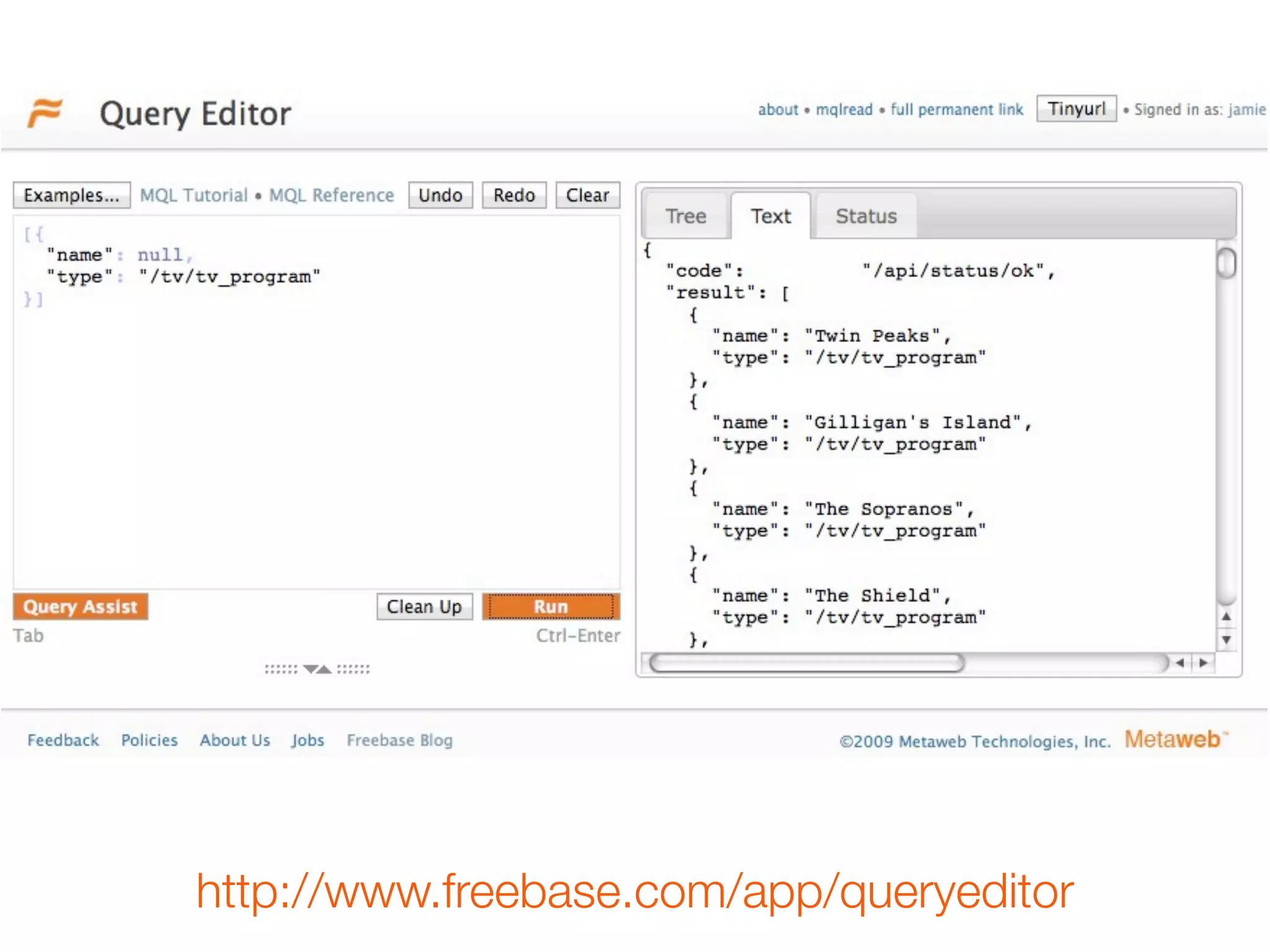
[{
"name" : null,
"type" : "/tv/tv_program"
}]
MQL](https://image.slidesharecdn.com/nyc-workshop-091214201345-phpapp01/75/Freebase-Workshop-December-2009-3-2048.jpg)

!["/program_creator" = /tv/tv_program/program_creator
{
"id":"/en/ncis",
"name" : null,
"type" : "/tv/tv_program",
"program_creator":[ ]
}
MQL](https://image.slidesharecdn.com/nyc-workshop-091214201345-phpapp01/75/Freebase-Workshop-December-2009-7-2048.jpg)
![{
"id":"/en/ncis",
"name" : null,
"type" : "/tv/tv_program",
"program_creator":[{ "id":null, "name":null }]
}
MQL](https://image.slidesharecdn.com/nyc-workshop-091214201345-phpapp01/75/Freebase-Workshop-December-2009-8-2048.jpg)
![Mark Harmon
TV
Performance
Jethro Gibbs
{
"id":"/en/ncis",
"name" : null,
"type" : "/tv/tv_program",
"program_creator":[{ "id":null, "name:null }],
"regular_cast":[{
"actor":null,
"character":null
}]
}](https://image.slidesharecdn.com/nyc-workshop-091214201345-phpapp01/75/Freebase-Workshop-December-2009-9-2048.jpg)
![{
"id":"/en/ncis",
"name" : null,
"type" : "/tv/tv_program",
"program_creator":[{ "id":null, "name:null }],
"regular_cast":[{
"actor":null,
"character":null
}]
}](https://image.slidesharecdn.com/nyc-workshop-091214201345-phpapp01/75/Freebase-Workshop-December-2009-10-2048.jpg)
![Mark Harmon
TV
Performance
Jethro Gibbs
{
"id":"/en/ncis",
"name" : null,
"type" : "/tv/tv_program",
"program_creator":[{ "id":null, "name:null }],
"regular_cast":[{
"actor": {"id":null, "name":null},
"character":null
}]
}](https://image.slidesharecdn.com/nyc-workshop-091214201345-phpapp01/75/Freebase-Workshop-December-2009-11-2048.jpg)
![{
"id":"/en/ncis",
"name" : null,
"type" : "/tv/tv_program",
"program_creator":[{ "id":null, "name:null }],
"regular_cast":[{
"actor": {"id":null, "name":null},
"character":null
}],
"spin_offs":[ ]
}](https://image.slidesharecdn.com/nyc-workshop-091214201345-phpapp01/75/Freebase-Workshop-December-2009-12-2048.jpg)
![{
"id":"/en/ncis",
"name" : null,
"type" : "/tv/tv_program",
"program_creator":[{ "id":null, "name:null }],
"regular_cast":[{
"actor": {"id":null, "name":null},
"character":null
}],
"spin_offs":[{"id":null, "name":null,
"air_date_of_first_episode":null}]
}](https://image.slidesharecdn.com/nyc-workshop-091214201345-phpapp01/75/Freebase-Workshop-December-2009-13-2048.jpg)






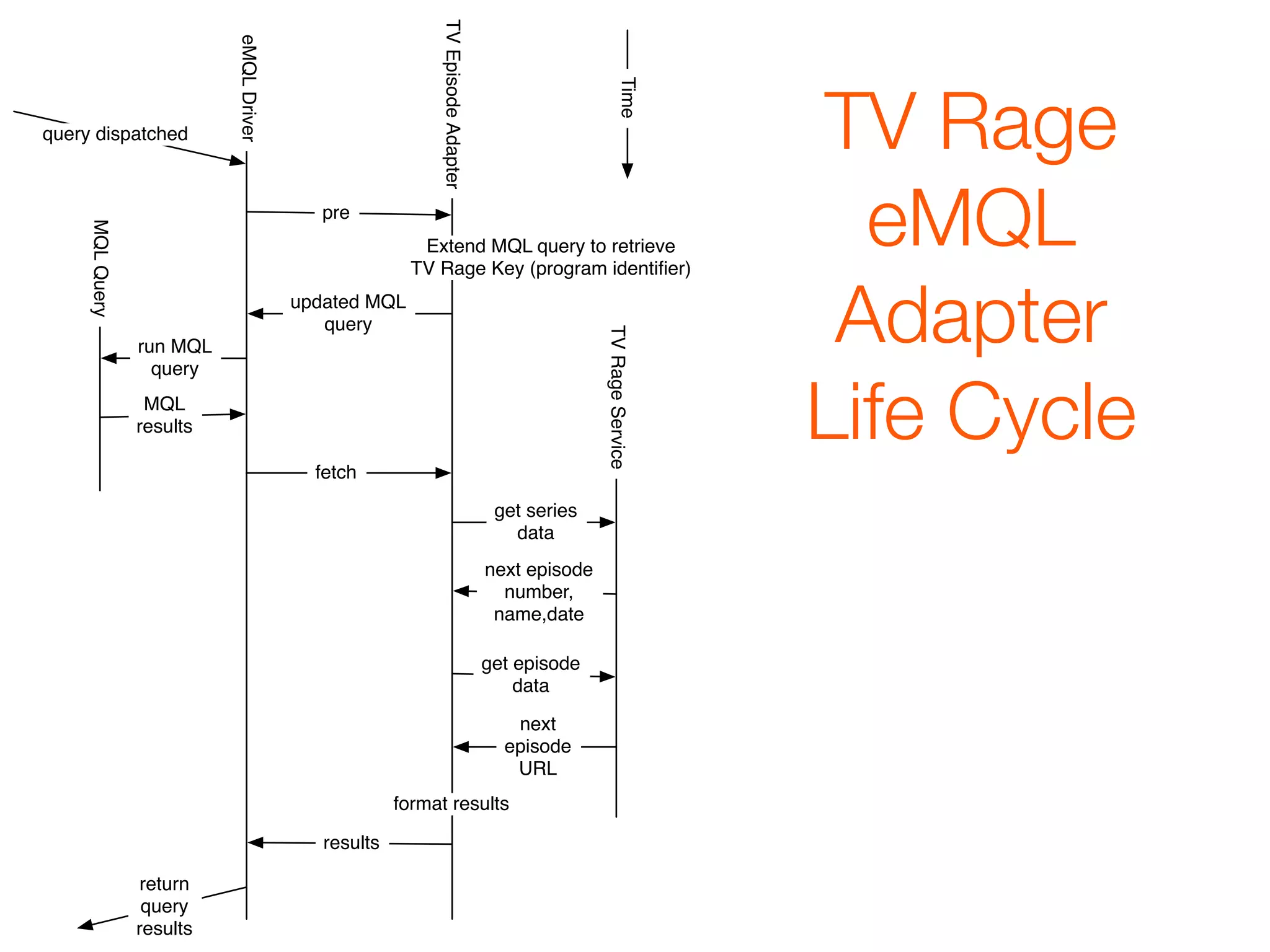
![eMQL Query
{
"id": "/en/ibm",
ticker
"type": "/business/company",
"ticker_symbol": [{
"ibm"
"stock_exchange": null,
"ticker_symbol":null
}]
}](https://image.slidesharecdn.com/nyc-workshop-091214201345-phpapp01/75/Freebase-Workshop-December-2009-21-2048.jpg)
![eMQL Query
{
"id": "/en/ibm",
"type": "/business/company", ticker
"ticker_symbol": [{
"stock_exchange": null, "ibm"
"ticker_symbol":null,
"quote":null
}]
}](https://image.slidesharecdn.com/nyc-workshop-091214201345-phpapp01/75/Freebase-Workshop-December-2009-22-2048.jpg)
![eMQL Query
{
"id": "/en/ibm",
"type": "/business/company", ticker
"ticker_symbol": [{
"stock_exchange": null, "ibm"
"ticker_symbol":null,
"quote":null "pre"
}]
}
"fetch"](https://image.slidesharecdn.com/nyc-workshop-091214201345-phpapp01/75/Freebase-Workshop-December-2009-23-2048.jpg)


![MQL Requests in PHP
{"id":"/en/ncis", "name":null}
$topicid = "/en/ncis";
$simplequery = array('id'=>$topicid, 'name'=>null);
$queryarray = array('q1'=>array('query'=>$simplequery)); #query envelope
$jsonquerystr = json_encode($queryarray);
$mqlurl =
"http://www.freebase.com/api/service/mqlread?queries=". $jsonquerystr;
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $mqlurl);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$resultstr = curl_exec($ch);
curl_close($ch);
$resultarray = json_decode($resultstr, true); #true:give us an array
$topicname = $resultarray["q1"]["result"]["name"]](https://image.slidesharecdn.com/nyc-workshop-091214201345-phpapp01/75/Freebase-Workshop-December-2009-26-2048.jpg)






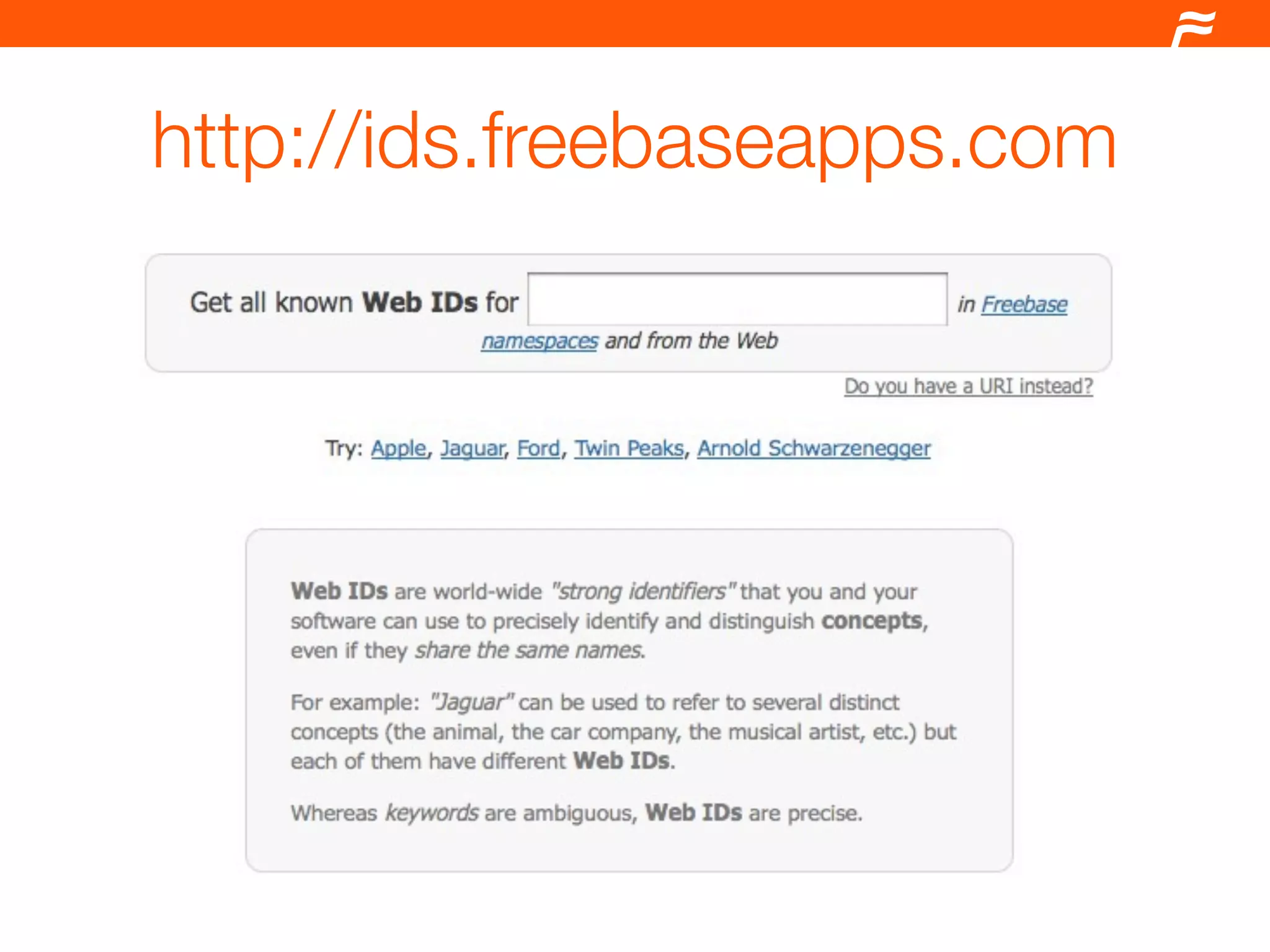




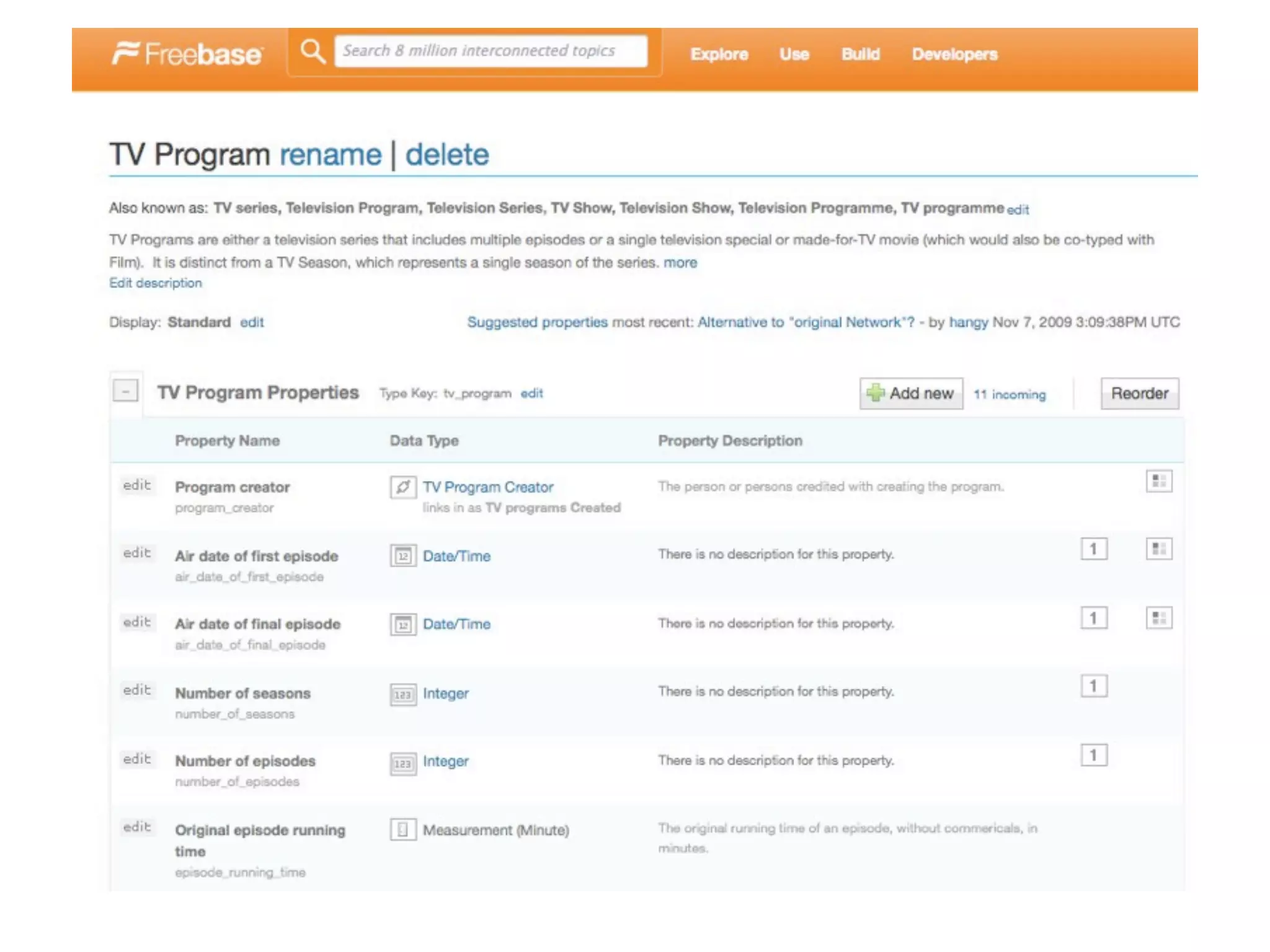
The document outlines a workshop conducted by Jamie Taylor in December 2009, focusing on using Freebase to build MQL queries for TV programs, particularly 'NCIS.' It details methods for accessing Freebase services via PHP, including the usage of CURL for service requests and EMQL extensions for real-time data. Additionally, it discusses integrating external data sources and provides links to relevant resources for developers.









































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)











