



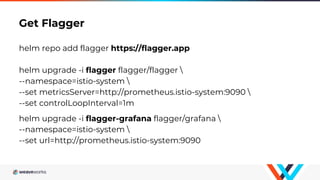
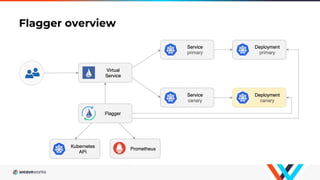

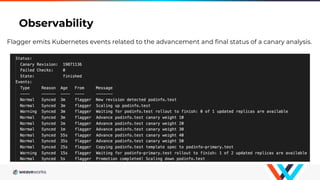
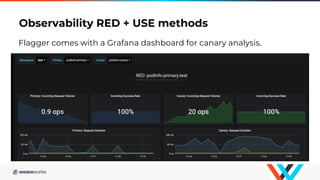
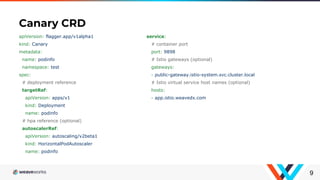
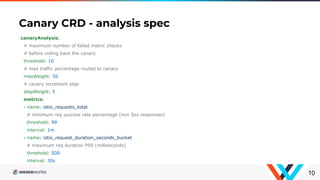
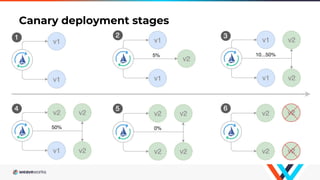
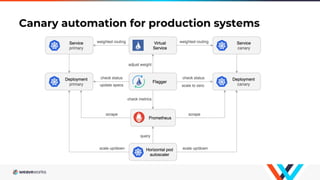




Flagger is a Kubernetes operator that automates canary deployments using Istio routing and Prometheus metrics. It gradually shifts traffic to the canary while measuring key performance indicators like success rate and latency. If the canary meets the thresholds, it is promoted to primary, if not traffic is shifted back and the canary is aborted. Flagger implements a control loop that advances the canary in steps from 0% to 100% traffic while monitoring metrics to ensure stability before fully promoting the deployment.











































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)






