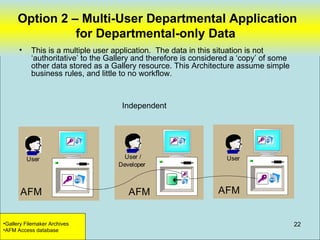
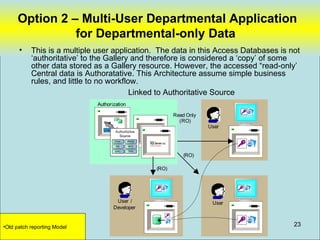
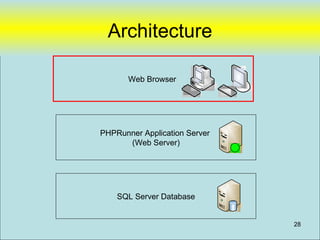
Filemaker is not a suitable option for the gallery's data sharing needs due to its limitations in integrating with SQL databases and running across platforms like Macs. While Filemaker's external SQL sources feature allows connecting to SQL databases, it has significant limitations including inability to base value lists on external data, date/time data entry restrictions, potential for out of date external data, lack of binary data support, slow scrolling of large record sets, and sorting not performed in the database. Filemaker is primarily designed for smaller, single platform solutions rather than scaling beyond a purely Filemaker based solution.



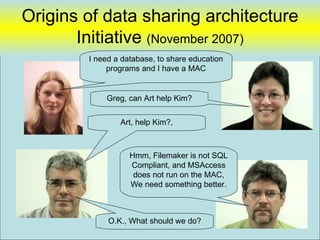

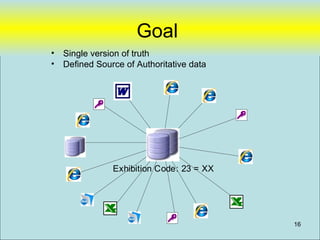
![Types of Gallery Data sharing
Word Docs One user at a time, not
Excel shared
MSAccess Isolated non-integrated database (Stand-
Filemaker alone) shared between a handful of users,
Highly customized
Departmental Systems integrated to authoritative source,
Authoritative [ Missing Gap]
Need to have customized departmentusers across departments,
shared with many systems
Data Systems customizable
Workflow (IRIS) that reference authoritative data
Raisers Edge Many users shared, expensive, little-
TMS customization
Internet Enterprise-wide and beyond. 6
Intranet](https://image.slidesharecdn.com/webdatabase-120613101117-phpapp01/85/Creating-an-RAD-Authoratative-Data-Environment-6-320.jpg)


















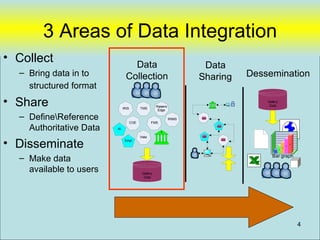
![Filemaker (My Last Straw)
From: John Blakeley [mailto:john@fbsl.co.nz]
Sent: Tue 1/8/08 2:27 PM
To: Nicewick, Arthur
Subject: RE: your post on Filemaker about ODBC conversion errors
Hi Arthur
Thanks and a happy New Year to you!
We gave up on the idea of pulling data from Filemaker using it as a linked server. In the
end we scheduled a script to run that exported data on an hourly basis. SQL would then
import it. We had to use MS scheduled tasks to open a FM file that would autostart an
export script as FM server schedule cannot run scripts that aren't web compatible.
Nothing is ever simple in Filemaker! One day...
Cheers
John Blakeley
John Blakeley Mobile: + 64 21 948037
Email: john@fbsl.co.nz
Skype: john.blakeley
Bayview
North Shore
New Zealand
36](https://image.slidesharecdn.com/webdatabase-120613101117-phpapp01/85/Creating-an-RAD-Authoratative-Data-Environment-36-320.jpg)
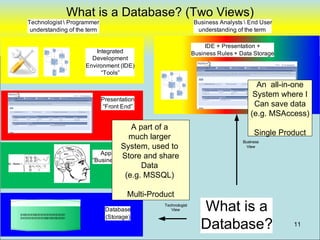
![Filemaker (My Last Straw)
From: John Blakeley [mailto:john@fbsl.co.nz]
Sent: Tue 1/8/08 2:27 PM
To: Nicewick, Arthur
Subject: RE: your post on Filemaker about ODBC conversion errors
Hi Arthur
Thanks and a happy New Year to you!
We gave up on the idea of pulling data from Filemaker using it as a linked server. In the
end we scheduled a script to run that exported data on an hourly basis. SQL would then
import it. We had to use MS scheduled tasks to open a FM file that would autostart an
export script as FM server schedule cannot run scripts that aren't web compatible.
Nothing is ever simple in Filemaker! One day...
Cheers
“We gave up on the idea of pulling data
John Blakeley
John from Filemaker using it as a linked server”
Blakeley Mobile: + 64 21 948037
Email: john@fbsl.co.nz
Skype: john.blakeley
Bayview
North Shore
New Zealand
37](https://image.slidesharecdn.com/webdatabase-120613101117-phpapp01/85/Creating-an-RAD-Authoratative-Data-Environment-37-320.jpg)
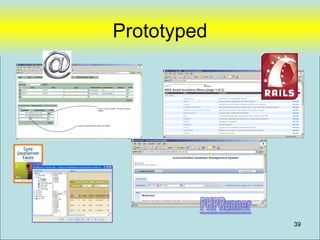








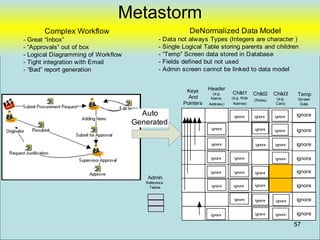
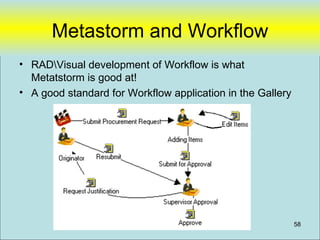
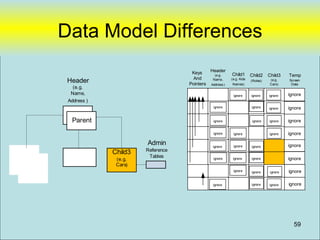
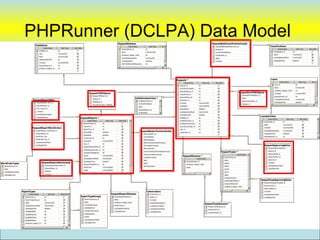
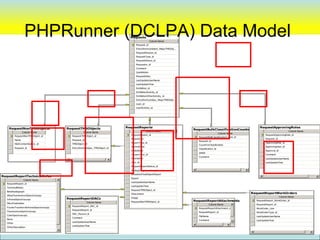
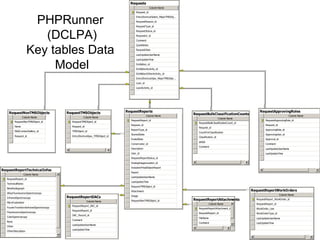
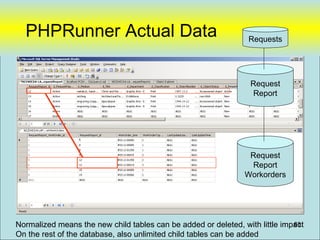
![PHPRunner
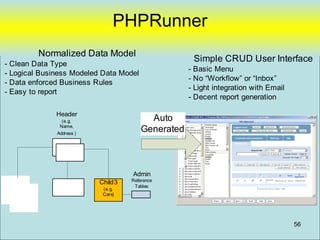
• Focus on “Data Model” in database and
not in “Application Logic”
– Example
• DCLPA – Lines of PHP code [~75 lines]
• DCLPA – Custom HTML [~86 lines]
• Tables 40 tables
• Database Stored Procedure Code [~250 lines]
Designed to be easily replaceable with new “user Interface” tool (if desired)
64](https://image.slidesharecdn.com/webdatabase-120613101117-phpapp01/85/Creating-an-RAD-Authoratative-Data-Environment-64-320.jpg)
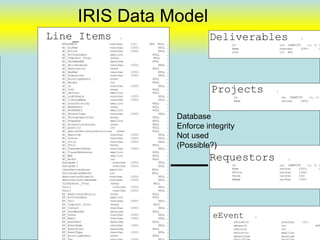
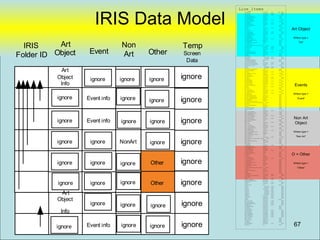











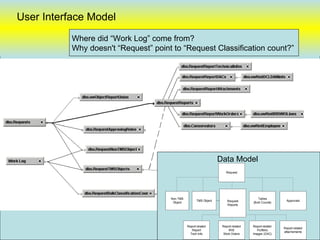
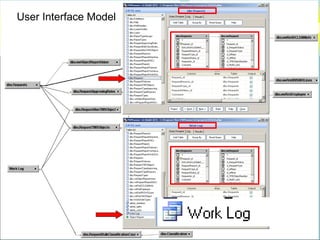
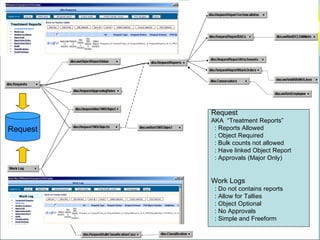
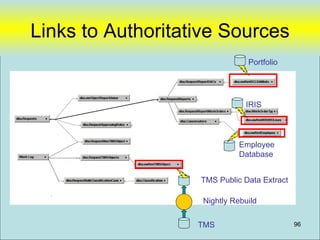
![Data Sharing “vwRmt”
Create view [dbo].[vwRmtEmployee] as
(
SELECT [ID#]
.
.
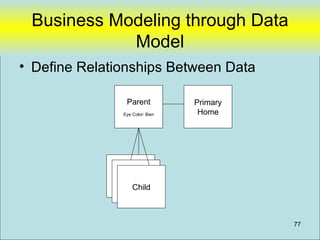
.
,[RestrictAlpha]
,[PayPlan]
,[Sponsor]
,[Super#]
from NGA-LANDESK.Employee.dbo.[T-Employees]
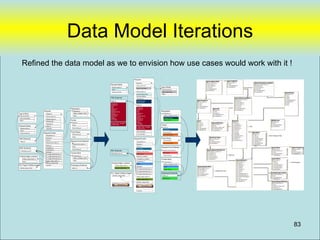
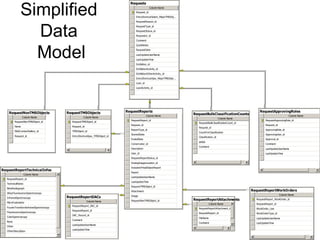
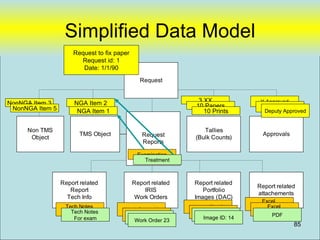
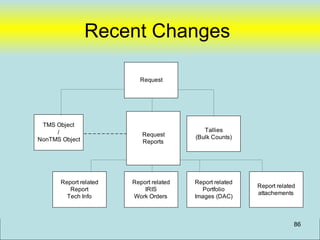
where [LastName] is not null
97](https://image.slidesharecdn.com/webdatabase-120613101117-phpapp01/85/Creating-an-RAD-Authoratative-Data-Environment-97-320.jpg)

































![Analisi di Vitalità Parte 2^ [Standards internazionali per la Conservazione]](https://cdn.slidesharecdn.com/ss_thumbnails/viabilityanalysisii-130417154636-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






















































