Downloaded 226 times






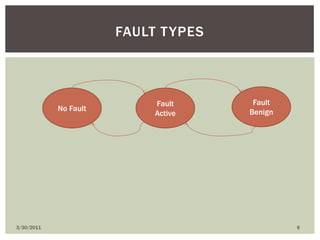




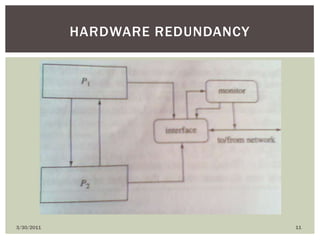

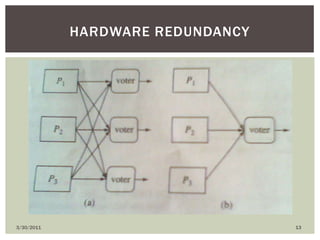

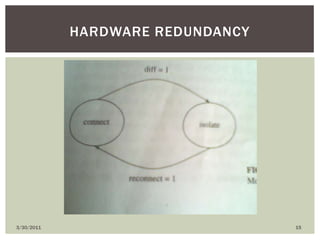




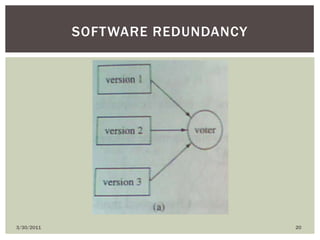
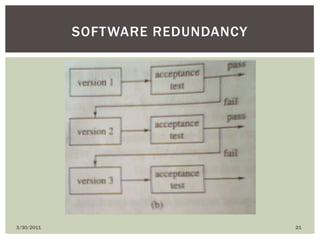



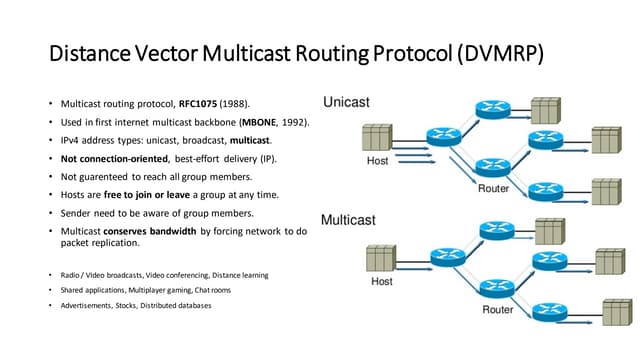
The document discusses various types of faults, errors, and fault tolerance techniques. It defines hardware faults as physical defects in components, and software faults as bugs that cause programs to fail. Errors are the manifestations of faults. Fault tolerance techniques include hardware redundancy using additional components, software redundancy using multiple versions, and time redundancy rerunning tasks. The document provides detailed descriptions and examples of various redundancy approaches.