Error Detection
• Errordetection is the most important aspect of fault tolerance
because a processor cannot tolerate a problem of which it is not
aware.
• Even if the processor cannot recover from a detected error, the
processor can still alert the user that an error has occurred and halt.
• Error detection thus provides, at the minimum, a measure of safety.
A safe processor does not do anything incorrect. Without recovery,
the processor may not be able to make forward progress, but at least
it is safe. It is far preferable for a processor to do nothing than to
silently fail and corrupt data.
3.
Error Detection (Cont)
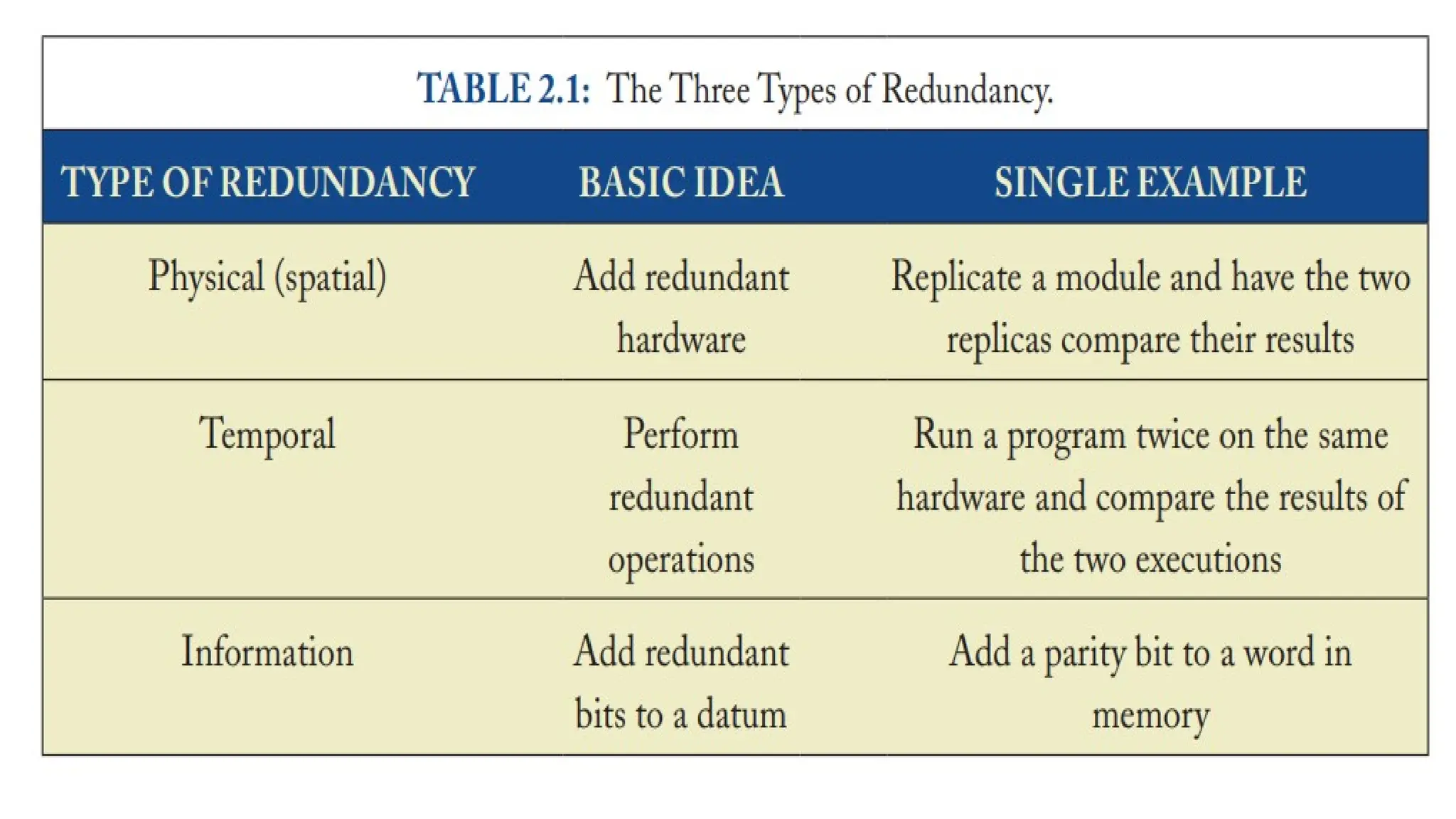
•There are some fundamental concepts in error detection
• The key to error detection is redundancy: a processor with no
redundancy fundamentally cannot detect any errors.
• The three classes of redundancy—physical (spatial), temporal, and
information
• All error detection schemes use one or more of these types of
redundancy.
5.
Physical Redundancy
• Physical(or spatial) redundancy is a commonly used approach for
providing error detection.
• The simplest form of physical redundancy is dual modular redundancy
(DMR) with a comparator.
• DMR provides excellent error detection because it detects all errors
except for errors due to design bugs, errors in the comparator, and
unlikely combinations of simultaneous errors that just so happen to
cause both modules to produce the same incorrect outputs.
6.
Temporal Redundancy
• Temporalredundancy perform an operation twice (or more times, in
theory, but we only consider two iterations here), one after the other,
and then compare the results.
• Unlike with physical redundancy, there is no extra hardware or power
cost (once again ignoring the comparator).
• Because of temporal redundancy’s steep performance cost, many
schemes use pipelining to hide the latency of the redundant
operation.
7.
Information Redundancy
• Thebasic idea behind information redundancy is to add redundant
bits to a datum to detect when it has been affected by an error.
• The key idea is to map the datawords to codewords such that the
codewords are as “far apart” from each other as possible.
• The distance between any two codewords, called the Hamming
distance (HD), is the number of bit positions in which they differ. For
example, 01110 and 11010 differ in two bit positions.
8.
Error Detection Tailoredto Specific Fault
Models
• Errors Due to Permanent Faults.
• Blome et al. developed wear-out detectors that can be placed at
strategic locations within a core. The key observation is that wear-
out of a component often manifests itself as a progressive increase
in that component’s latency. They add a small amount of hardware
to statistically assess increases in delay and thus detect the onset
of wear-out. A component with progressively increasing delay is
diagnosed as wearing out and likely to soon suffer a permanent
fault.
9.
Error Detection Tailoredto Specific Fault
Models (cont)
• Errors Due to Design Bugs.
• Errors due to design bugs are particularly problematic because a
design bug affects every shipped core.
• Unfortunately, design bugs will continue to plague shipped cores
because completely verifying the design of a complicated core is
well beyond the current state-of-the-art in verification technology.
Ideally, we would like a core to be able to detect errors due to
design bugs and, if possible, recover gracefully from these errors
10.
The End-to-End Argument
•We can apply redundancy to detect errors at many different levels in the
system—at the transistor, gate, cache block, core, and so on. A question
for a computer architect is what level or levels are appropriate.
• Saltzer et al. argued for “end-to-end” error detection in which we strive
to perform error detection at the “ends” or the highest level possible.
• Instead of adding hardware to immediately detect errors as soon as
they occur, the end-to-end argument suggests that we should wait to
detect errors until they manifest themselves as anomalous higher-level
behaviors.
11.
The End-to-End Argument(Cont)
• For example, instead of detecting that a bit flipped, we would prefer
to wait until that bit flip resulted in an erroneous instruction result or
a program crash.
• By checking at a higher level, we can reduce the hardware costs and
reduce the number of false positives (detected errors that have no
impact on the core’s behavior).
• Furthermore, we have to check at the ends anyway because only at
the ends does the system have sufficient semantic knowledge to
detect certain types of errors.
12.
The End-to-End Argument(Cont)
• Three (3) Drawbacks to Relying only on end-to-end error detection
• First, detecting a high-level error like a program crash provides little diagnostic
information. If the crash is due to a permanent fault, it would be beneficial to have
some idea of where the fault is that caused the crash, or even that the crash was due to
a physical fault and not a software bug. If only end-to-end error detection is used, then
additional diagnostic mechanisms may be necessary.
• The second drawback to relying only on high-level error detection is that it has a longer
— and potentially unbounded—error detection latency. A low-level error like a bit flip
may not result in a program crash for a long time.
• The third drawback of relying solely on end-to-end error detection is that the recovery
process itself may be more complicated. Recovering the state of a small component is
often easier than recovering a larger component or an entire system.
13.
Redundant Codes
• MostError Detection and Correction Codes systems use some form
of redundancy to check whether the received data contains errors.
This means that information additional to the basic data is sent.
• In the simplest system to visualize, the redundancy takes the form
of transmitting the information twice and comparing the two sets
of data to see that they are the same.
• Statistically, it is very unlikely that a random error will occur a
second time at the same place in the data.
• If a discrepancy is noted between the two sets of data, an error is
assumed and the data is caused to be re-transmitted. When two
sets of data agree, error-free transmission is assumed.
14.
Constant-Ratio Codes
• Afew codes have been developed which provide inherent
Error Detection and Correction Codes when used in ARQ
(automatic request for repeat) systems.
• The 2-out-of-5 code follows a pattern which results in every
code group having two 1s and three 0s.
• When the group is received, the receiver will be able to
determine that an error has occurred if the ratio of 1s to 0s
has been altered.
• If an error is detected, a NAK (do not acknowledge)
response is sent and the data word is repeated. This testing
procedure continues word for word.
15.
Parity-Check Codes
• Apopular form of Error Detection and Correction Codes employing
redundancy is the use of a parity-check bit added to each character
code group. Codes of this type are called parity-check codes.
• The parity bit is added to the end of the character code block according
to some logical process. The most common parity-check codes add the
1s in each character block code and append a 1 or 0 as required to
obtain an odd or even total, depending on the code system.
• Odd parity systems will add a 1 if addition of the 1s in the block sum is
odd. At the receiver, the block addition is accomplished with the parity
bit intact, and appropriate addition is made. If the sum provides the
wrong parity, an error during transmission will be assumed and the
data will be retransmitted.
16.
Error Correction
• Detectingerrors is clearly of little use unless methods are
available for the correction of the detected errors.
• Correction is thus an important aspect of data transmission.
• The most popular method of error correction is
retransmission of the erroneous information.
17.
Retransmission
• For Retransmissionto occur in the most expeditious manner,
some form of automatic system is needed. A system which has
been developed and is in use is called the automatic request for
repeat (ARQ), also called the positive acknowledgment/negative
acknowledgment (ACK/NAK) method.
• The request for repeat system transmits data as blocks. The parity
for each block is checked upon receipt, and if no parity discrepancy
is noted, a positive acknowledgment (ACK) is sent to the transmit
station and the next block is transmitted. If, however, a parity error
is detected, a negative acknowledgment (NAK) is made to the
transmit station which will repeat the block of data. have occurred.
18.
Retransmission (cont)
• Theparity check is again made and transmission continues
according to the result of the parity check. The value of this
kind of system stems from its ability to detect errors after a
small amount of data has been sent. If retransmission is
needed, the redundant transmission time is held to a
minimum. This is much more efficient than retransmission
of the total message if only one or two data errors
19.
Forward Error-Correcting Codes
•For transmission efficiency, error correction at the receiver
without retransmission of erroneous data is naturally
preferred, and a number of methods of accomplishing this
are available.
• Codes which permit correction of errors by the receive
station without retransmission are called forward error-
correcting codes.
• The basic requirement of such codes is that sufficient
redundancy be included in the transmitted data for error
correction to be properly accomplished by the receiver
without further input from the transmitter.
Editor's Notes
#3 Redundancy, which involves replicating software components, data, or computations to provide backup or alternative solutions in case of errors.
#5 A comparator determines whether two binary numbers are equal or if one is greater or less than the other. A comparator receives two N-bit binary numbers A and B and outputs a 1-bit comparison result.

















































![[DSC Europe 25] Vid Stimac - Policy Parsimony: Between Oversimplifying and Ov...](https://cdn.slidesharecdn.com/ss_thumbnails/eqlepagzqp2rhg3gbluh-dsc-stimac-251120-251205090438-059e7f54-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)