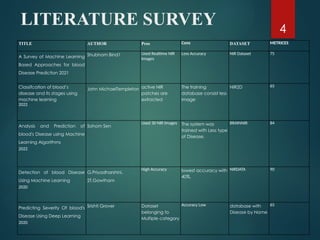
Infosys is an Indian multinational technology company that offers business consulting, information technology, and outsourcing services. Founded in 1981, it is headquartered in Bengaluru and is one of the largest IT companies in India. Infosys is a global leader in next-generation digital services and consulting, enabling clients in over 50 countries to navigate their digital transformation.
Here's a more detailed look:
Services:
Infosys provides a wide range of services including digital transformation, cloud computing, AI and machine learning, data analytics, and cybersecurity.
Global Presence:
With over 317,000 employees, Infosys has a presence in more than 56 countries and serves clients across various industries.
Key Milestones:
Infosys was the first Indian IT company to be listed on NASDAQ. In 2021, it became the fourth Indian company to achieve a market capitalization of US$100 billion.
Focus on Innovation:
Infosys is known for its innovative approach to technology solutions and its commitment to ethical business practices.
Digital Transformation:
The company plays a significant role in helping businesses undergo digital transformation by leveraging AI-powered core systems and agile digital technologies.
Environmental Sustainability:
Infosys also focuses on environmental sustainability, managing energy, water, and waste across its global operations.
Infosys is an Indian multinational technology company that offers business consulting, information technology, and outsourcing services. Founded in 1981, it is headquartered in Bengaluru and is one of the largest IT companies in India. Infosys is a global leader in next-generation digital services and consulting, enabling clients in over 50 countries to navigate their digital transformation.
Here's a more detailed look:
Services:
Infosys provides a wide range of services including digital transformation, cloud computing, AI and machine learning, data analytics, and cybersecurity.
Global Presence:
With over 317,000 employees, Infosys has a presence in more than 56 countries and serves clients across various industries.
Key Milestones:
Infosys was the first Indian IT company to be listed on NASDAQ. In 2021, it became the fourth Indian company to achieve a market capitalization of US$100 billion.
Focus on Innovation:
Infosys is known for its innovative approach to technology solutions and its commitment to ethical business practices.
Digital Transformation:
The company plays a significant role in helping businesses undergo digital transformation by leveraging AI-powered core systems and agile digital technologies.
Environmental Sustainability:
Infosys also focuses on environmental sustainability, managing energy, water, and waste across its global operations.
Infosys is an Indian multinational technology company that offers business consulting, information technology, and outsourcing services. Founded in 1981, it is headquartered in Bengaluru and is one of the largest IT companies in




















![REFERENCE
[1] S. Anita, P. Nagarajan, G. A. Sairam, P. Ganesh, and G. Deepakkumar,
“Fake Job Detection and Analysis Using Machine Learning and Deep Learning
Algorithms,” Rev. GEINTECGESTAO Inov. E Tecnol., vol. 11, no. 2, pp. 642–650,
2021.
[2] B. Alghamdi and F. Alharby, “An intelligent model for online recruitment
fraud detection,” J. Inf. Secur., vol. 10, no. 03, p. 155, 2019.
[3] “Report | Cyber.gov.au.” https://www.cyber.gov.au/acsc/report
(accessed Jun. 19, 2021).
[4] A. Pagotto, “Text Classification with Noisy Class Labels.” Carleton University,
2020. [5] “Employment Scam Aegean Dataset.”
http://emscad.samos.aegean.gr/ (accessed Jun. 19, 2021).
[6] S. Vidros, C. Kolias, G. Kambourakis, and L. Akoglu, “Automatic detection of
online recruitment frauds: Characteristics, methods, and a public dataset,”
Futur. Internet, vol. 9, no. 1, p. 6, 2017.](https://image.slidesharecdn.com/fakejobdetectionppt-250630143533-f85c3b86/85/Fake-Job-Detection-PPT-pptx-using-python-26-320.jpg)
















































