The document discusses a project aimed at detecting fake news on social media using natural language processing and machine learning techniques. The authors collected and preprocessed datasets containing both fake and real news, implemented various classification models, and achieved high accuracy rates using algorithms like logistic regression and decision trees. A platform-independent web server displays the results to users, showcasing the classification of news articles as either fake or true.











![DATA COLLECTION
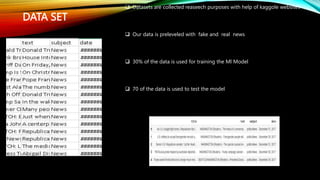
• In this paper, we used a dataset which collected from Kaggle[28].There are two dataset.
One of them includes real data, while the other ones contain fake data. True dataset
consists of 21417 data and Fake dataset consists of 23481 data.Title, text, subject, and
date are the four features present in both datasets. Text, Title and Subject which
attributes are contain qualitative data means all is textual data and Subject represent
categorical data.
DATA PREPROCESSING
• Both organized and unstructured data might be included. Unstructured data is that which does not adhere to all of the
grammar rules and may contain typos and slang. Structured data adheres to proper grammar standards. Both organized and
unstructured data do not produce the greatest outcomes. It is advisable to utilize data with a semi-structure. Data that is
partially organized but not completely unstructured is referred to as semi-structured data. It stands in between the two.We use
NLP.
• Eliminate punctuation
• Tokenization
• Stopwords
• Stemming](https://image.slidesharecdn.com/detectingfakenews20-15-3541pc-l-221223204601-5995fcc8/85/Detecting-fake-news-pptx-13-320.jpg)





































































