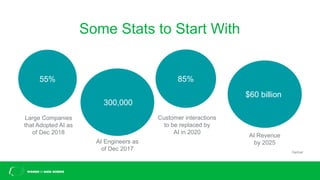
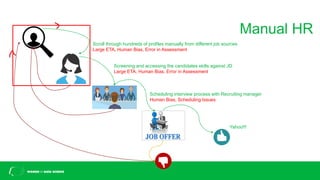
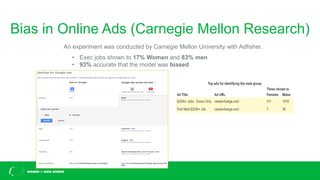
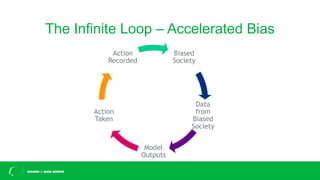
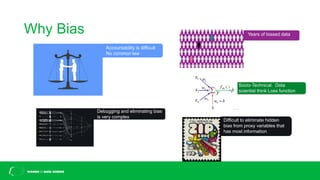
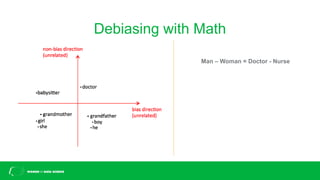
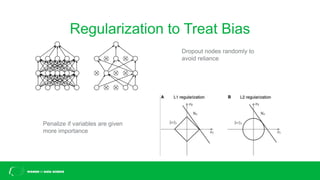
This document discusses challenges with bias in artificial intelligence systems and potential solutions. It begins by providing examples of biased AI in areas like recruitment, law enforcement, online ads, and language. Common sources of bias include biased training data, lack of diversity in data science teams, and overly relying on proxy variables. Potential solutions proposed include algorithmic accountability, improving training data diversity and representation, decoupling classifiers to achieve group fairness, debiasing models with mathematics, and introducing randomness into systems. The overall message is that eliminating bias is complex but progress can be made through approaches like these.





































































![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Ekaterina Bubenko - Behind the Curtain: How Data Roles Collab...](https://cdn.slidesharecdn.com/ss_thumbnails/anmv6x8dstqbbzchoklr-ekaterina-bubenko-behind-the-curtain-how-data-roles-collaborate-in-the-ai-era-a-260123083019-4b252ec7-thumbnail.jpg?width=640&height=640&fit=bounds)






