Download as PDF, PPTX







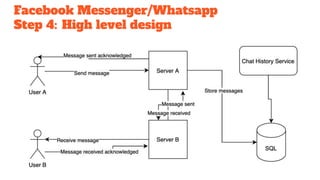
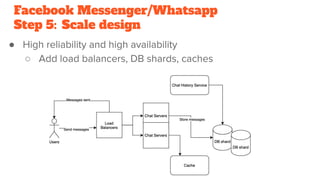

This document outlines a 5-step methodology for designing messaging platforms like Facebook Messenger and WhatsApp. Step 1 involves defining use cases, assumptions, and constraints. Step 2 involves back-of-the-envelope calculations for database design and traffic/storage estimates. Step 3 designs core components to support key use cases. Step 4 develops a high-level design. Step 5 scales the design to achieve high reliability and availability.






























































