Download as PDF, PPTX






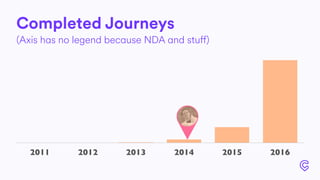
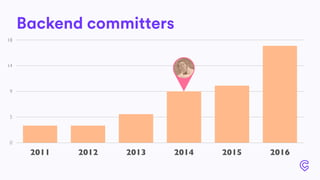

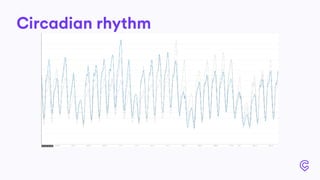


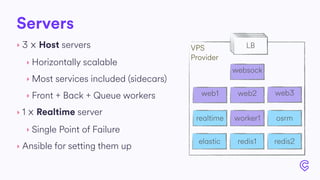









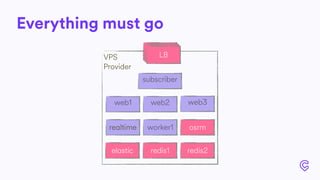



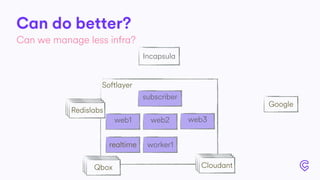


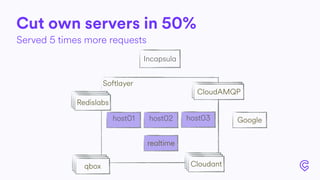















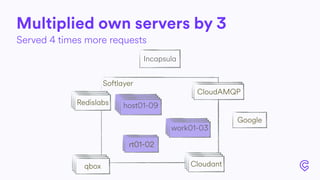














The document details the infrastructure scaling challenges faced by Cabify from 2011 to 2017, focusing on their transition from VPS to bare metal servers and various database solutions. It highlights performance issues, solutions implemented like changing database technology and load balancing strategies, and the importance of monitoring and system administration. The narrative showcases the evolution and lessons learned in handling increased loads and optimizing their service architecture over the years.












































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)










