Downloaded 22 times








![Horovod on Hops
import horovod.tensorflow as hvd
def conv_model(feature, target, mode)
…..
def main(_):
hvd.init()
opt = hvd.DistributedOptimizer(opt)
if hvd.local_rank()==0:
hooks = [hvd.BroadcastGlobalVariablesHook(0), ..]
…..
else:
hooks = [hvd.BroadcastGlobalVariablesHook(0), ..]
…..
from hops import allreduce
allreduce.launch(spark, 'hdfs:///Projects/…/all_reduce.ipynb')
“Pure” TensorFlow code
14/33](https://image.slidesharecdn.com/logicalclocksabdeeplearningfinance-180316094953/85/End-to-End-Platform-Support-for-Distributed-Deep-Learning-in-Finance-14-320.jpg)

![Parallel Experiments on Hops
def model_fn(learning_rate, dropout):
import tensorflow as tf
from hops import tensorboard, hdfs, devices
[TensorFlow Code here]
from hops import experiment
args_dict = {'learning_rate': [0.001, 0.005, 0.01],
'dropout': [0.5, 0.6]}
experiment.launch(spark, model_fn, args_dict)
Launch TF jobs in Spark Executors
17/33
Launches 6 Spark Executors with a different Hyperparameter
combinations. Each Executor can have 1-N GPUs.](https://image.slidesharecdn.com/logicalclocksabdeeplearningfinance-180316094953/85/End-to-End-Platform-Support-for-Distributed-Deep-Learning-in-Finance-16-320.jpg)
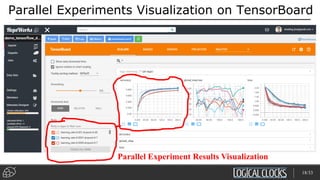


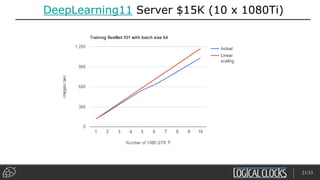
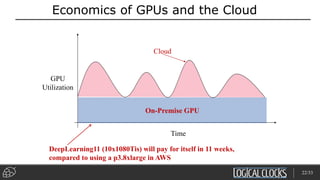


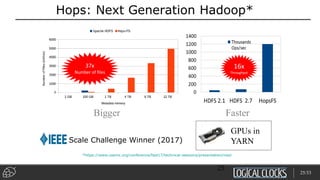
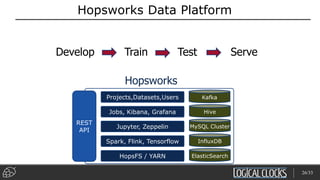
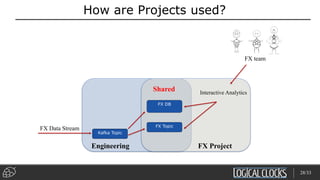
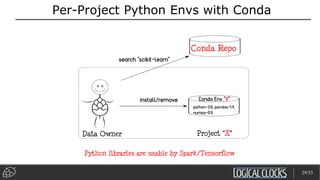
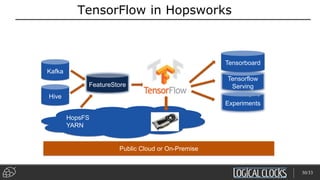
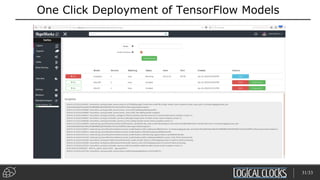

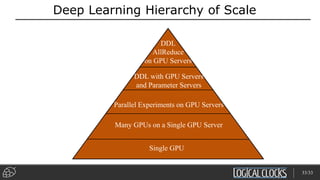



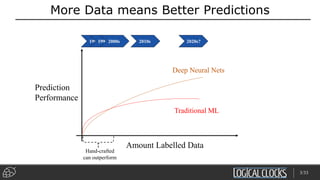
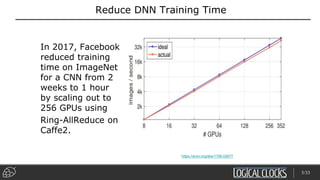
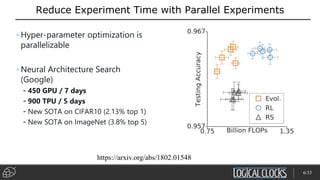
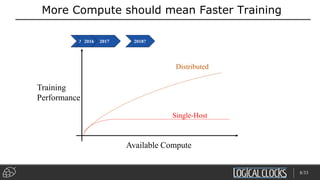
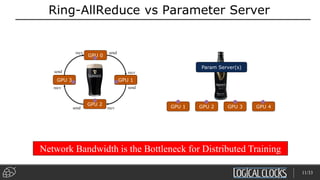
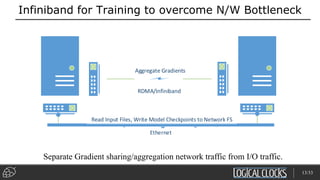
Distributed deep learning platforms can improve productivity for practitioners by enabling faster training through distributed computing. Hopsworks is a new data platform built on HopsFS that provides first-class support for Python, deep learning, machine learning, and strong data governance. It allows for distributed deep learning training and parallel experiments across GPU servers as well as secure streaming analytics using Kafka, Spark, and Flink.




























![ARVC and flecainide case report[EI] Jim.docx.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/finalarvcandflecainidecasereporteijim-230918192356-cebc27e5-thumbnail.jpg?width=640&height=640&fit=bounds)






































