Downloaded 10 times
















![MG-RAST / EBI Mgnify [Rob Finn]
Nature, 02 September 2019](https://image.slidesharecdn.com/elixirukboardnov2019-191119112039/85/ELIXIR-UK-Node-presentation-to-the-ELIXIR-Board-27-320.jpg)
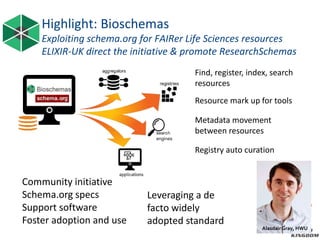
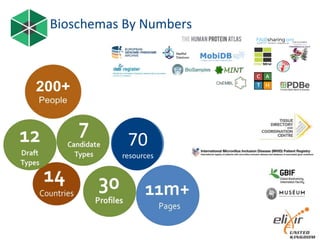


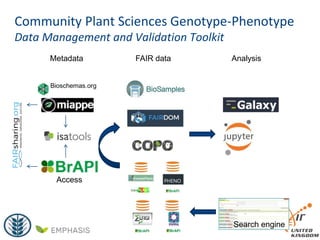
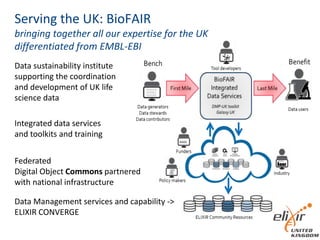
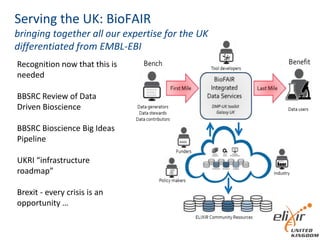



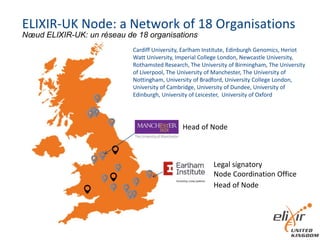
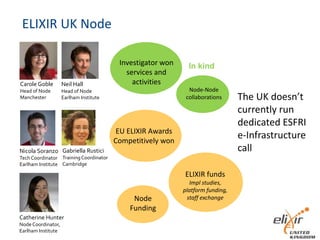
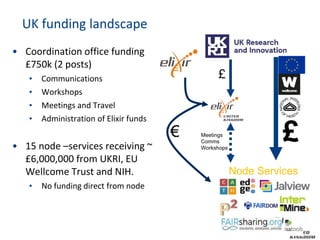
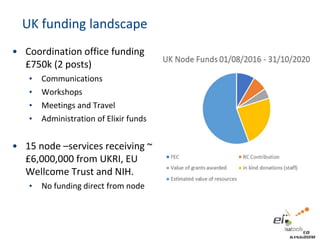
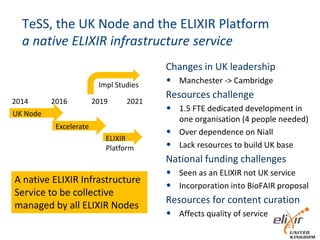
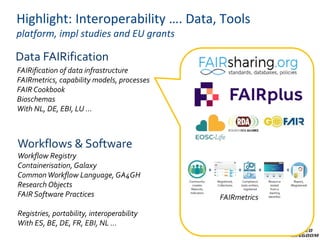
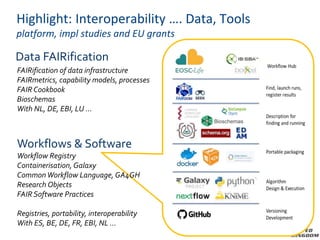
The document provides information about ELIXIR-UK, which is the UK node of ELIXIR, a European infrastructure for biological information. ELIXIR-UK is a network of 18 UK organizations and has established training programs, services, and communities. It coordinates UK participation in ELIXIR and related EU projects. ELIXIR-UK also works to establish interoperability across biological data resources and help make these resources FAIR (Findable, Accessible, Interoperable, Reusable). It is working to establish BioFAIR, a proposed new institute that would coordinate UK life science data infrastructure.














































































![谷歌留痕技术 [ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130174328-3833018c-thumbnail.jpg?width=640&height=640&fit=bounds)




