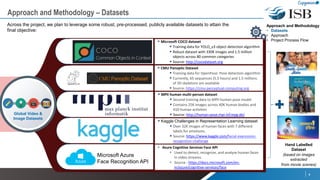
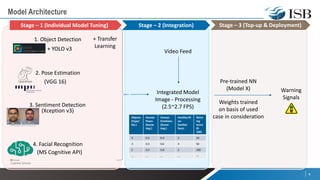
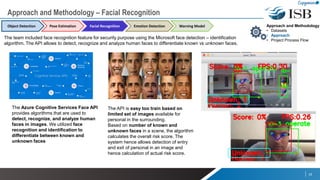
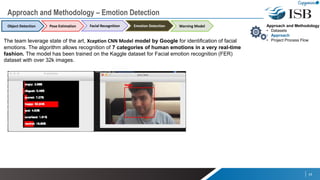
The document discusses a capstone project focusing on deep learning for video analytics, aimed at detecting and categorizing themes in video streams, particularly for use in elderly assistance. It outlines the methodology, which includes leveraging multiple pre-trained models for object detection, pose estimation, emotion detection, and facial recognition, alongside addressing challenges like data privacy and the need for labeled datasets. The project seeks to create a real-time solution capable of identifying potential risks and anomalies within video feeds.



































![[TOxAIA新竹分校] 工業4.0潛力新應用! 多模式對話機器人](https://cdn.slidesharecdn.com/ss_thumbnails/20181206004-181210031031-thumbnail.jpg?width=640&height=640&fit=bounds)

























![[DSC Europe 25] Bojan Djuricic - Predictive Design Process.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/5awdrbedqdek3gqu2ezy-4-the-predictive-design-bojan-djuricic-260120105856-6c399e9b-thumbnail.jpg?width=640&height=640&fit=bounds)














![[DSC Europe 25] Slobodan Dolinic - Smart and Intelligent Green Region.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/0bribinjsp6ghwtvsvor-2-sigre-slobodan-dolinic-260115093812-c9c10e90-thumbnail.jpg?width=640&height=640&fit=bounds)
