Download to read offline


















![Open source culture: bazaar governance
E. Raymond, “The Cathedral and the Bazaar”
Linux is ‘a great babbling bazaar of differing agendas and
approaches’
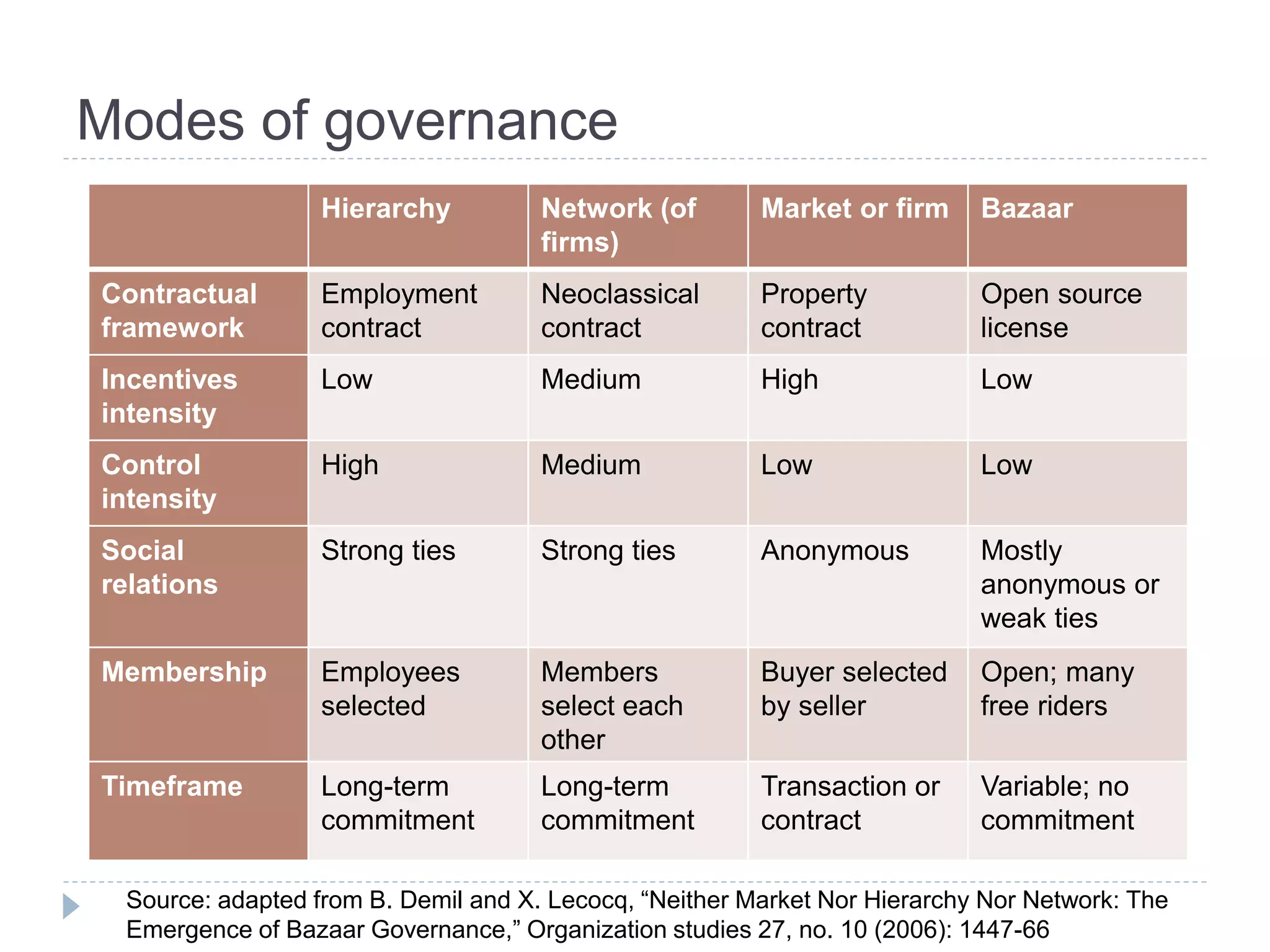
Characteristic: chaotic market, huge variations in quality
“Low levels of control and weak incentives intensity
are distinctive features of bazaar [governance],
lending a high uncertainty to governed transactions.”
Source: B. Demil and X. Lecocq, “Neither Market Nor Hierarchy Nor Network: The Emergence of Bazaar
Governance,” Organization Studies 27, no. 10 (2006): 1447-1466.](https://image.slidesharecdn.com/edwardsgovernanceandcyberinfrastructureintheearthsystemsciencesr4-140725153502-phpapp02/75/AHM-2014-Governance-and-Cyberinfrastructure-in-the-Earth-System-Sciences-25-2048.jpg)




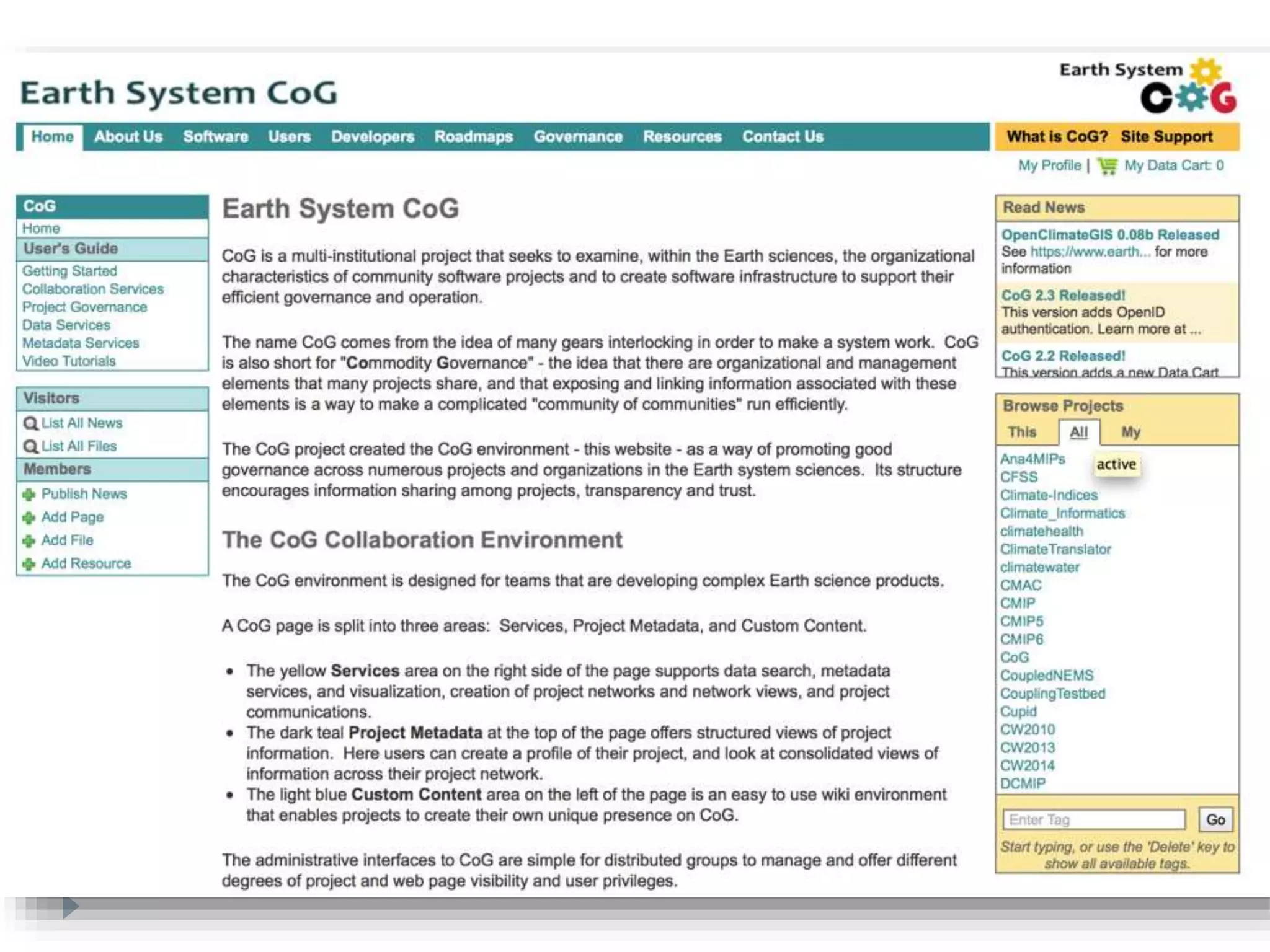









The document discusses the governance and cyberinfrastructure within the Earth system sciences, emphasizing the need for common data formats and metadata standards to improve data sharing among scientists. It explores historical and contemporary models of governance and infrastructure, contrasting centralized control with decentralized approaches, such as bazaar governance in open-source culture. The challenges of integrating diverse institutional cultures and technological standards are highlighted, along with the importance of addressing social dynamics in scientific projects to enhance collaboration and data exchange.


































































