Download as PDF, PPTX





![• NIF
has
developed
a
produc>on
technology
pla]orm
for
researchers
to:
– Discover
– Share
– Analyze
– Integrate
neuroscience-‐relevant
informa>on
• Since
2008,
NIF
has
assembled
the
largest
searchable
catalog
of
neuroscience
data
and
resources
on
the
web
• Cost-‐effec>ve
and
innova>ve
strategy
for
managing
data
assets
“This
unique
data
depository
serves
as
a
model
for
other
Web
sites
to
provide
research
data.
“
-‐
Choice
Reviews
Online
NIF
is
poised
to
capitalize
on
the
new
tools
and
emphasis
on
big
data
and
open
science](https://image.slidesharecdn.com/ecsite-130818192348-phpapp01-130819091758-phpapp02/75/Neurosciences-Information-Framework-NIF-An-example-of-community-Cyberinfrastructure-for-the-Neurosciences-7-2048.jpg)


![12
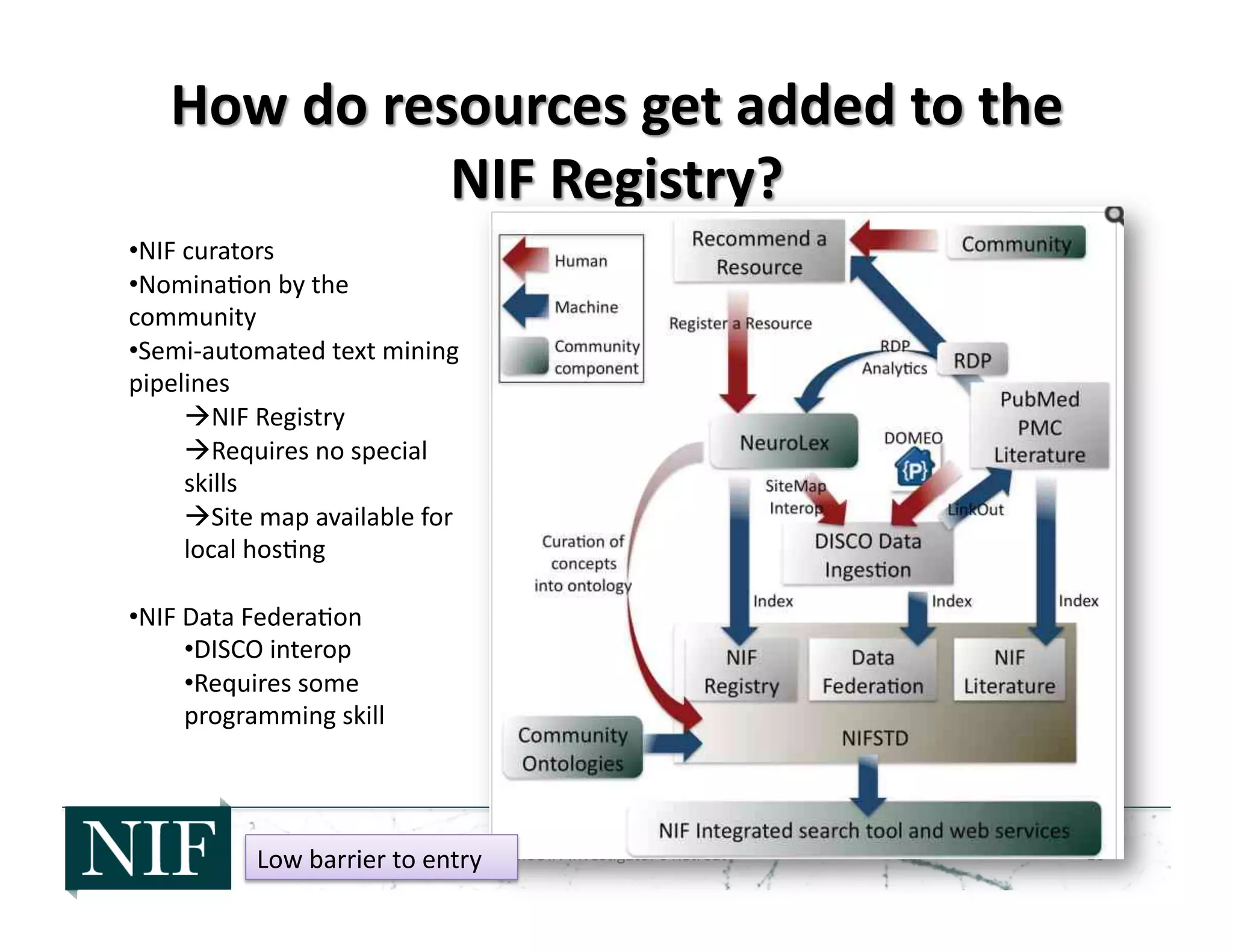
• NIF
Registry
is
hosted
on
Seman>c
Media
Wiki
pla]orm
Neurolex
– Community
can
add,
review,
edit
without
special
privileges
– Searchable
by
Google
– Integrated
with
NIF
ontologies
– Graph
structure
Seman>c
wiki:
A
wiki
with
seman>cs;
pages
are
linked
through
rela>onships](https://image.slidesharecdn.com/ecsite-130818192348-phpapp01-130819091758-phpapp02/75/Neurosciences-Information-Framework-NIF-An-example-of-community-Cyberinfrastructure-for-the-Neurosciences-12-2048.jpg)
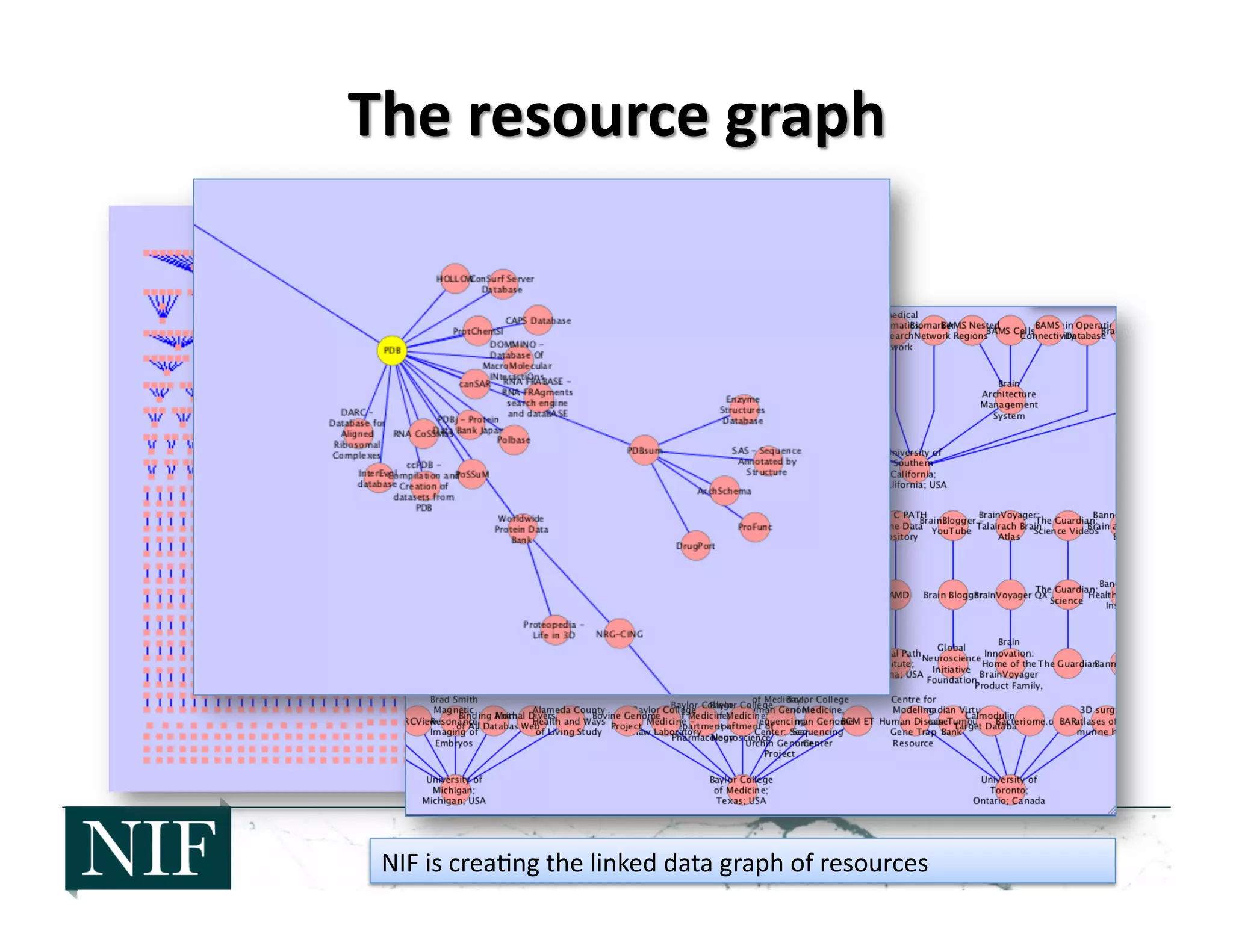
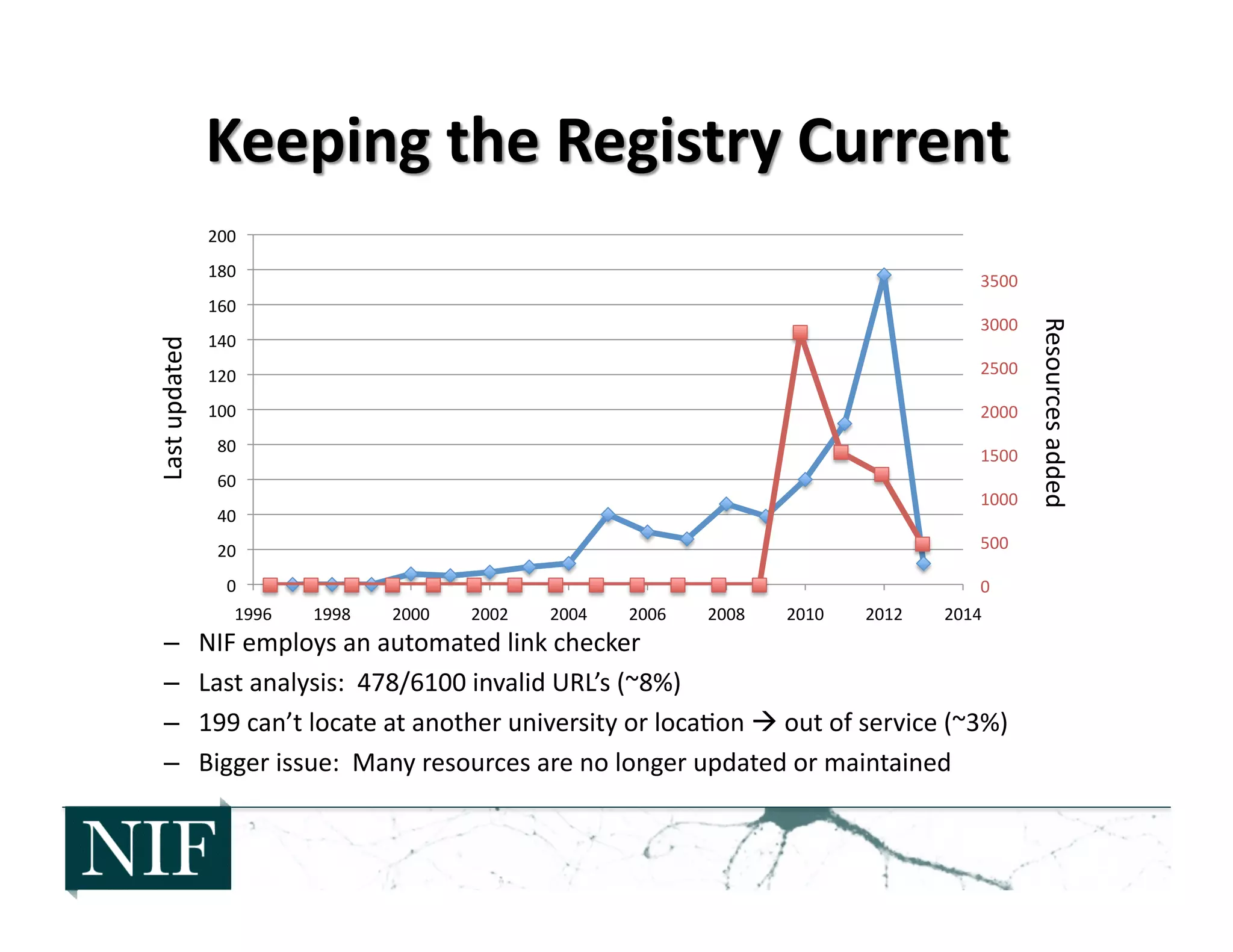

![• The
NIF
Registry
has
created
a
linked
data
graph
of
web-‐accessible
resources
• Maintained
on
a
community
wiki
pla]orm
• Provides
data
on
the
fluidity
of
the
resource
landscape
– New
resources
con>nue
to
be
created
and
found
– Rela>vely
few
disappear
altogether
– Many
more
grow
stale,
although
their
value
may
s>ll
be
significant
– Maintaining
up
to
date
cura>on
requires
frequent
upda>ng
NIF
Registry
provides
insight
into
the
state
of
digital
resources
on
the
web](https://image.slidesharecdn.com/ecsite-130818192348-phpapp01-130819091758-phpapp02/75/Neurosciences-Information-Framework-NIF-An-example-of-community-Cyberinfrastructure-for-the-Neurosciences-16-2048.jpg)


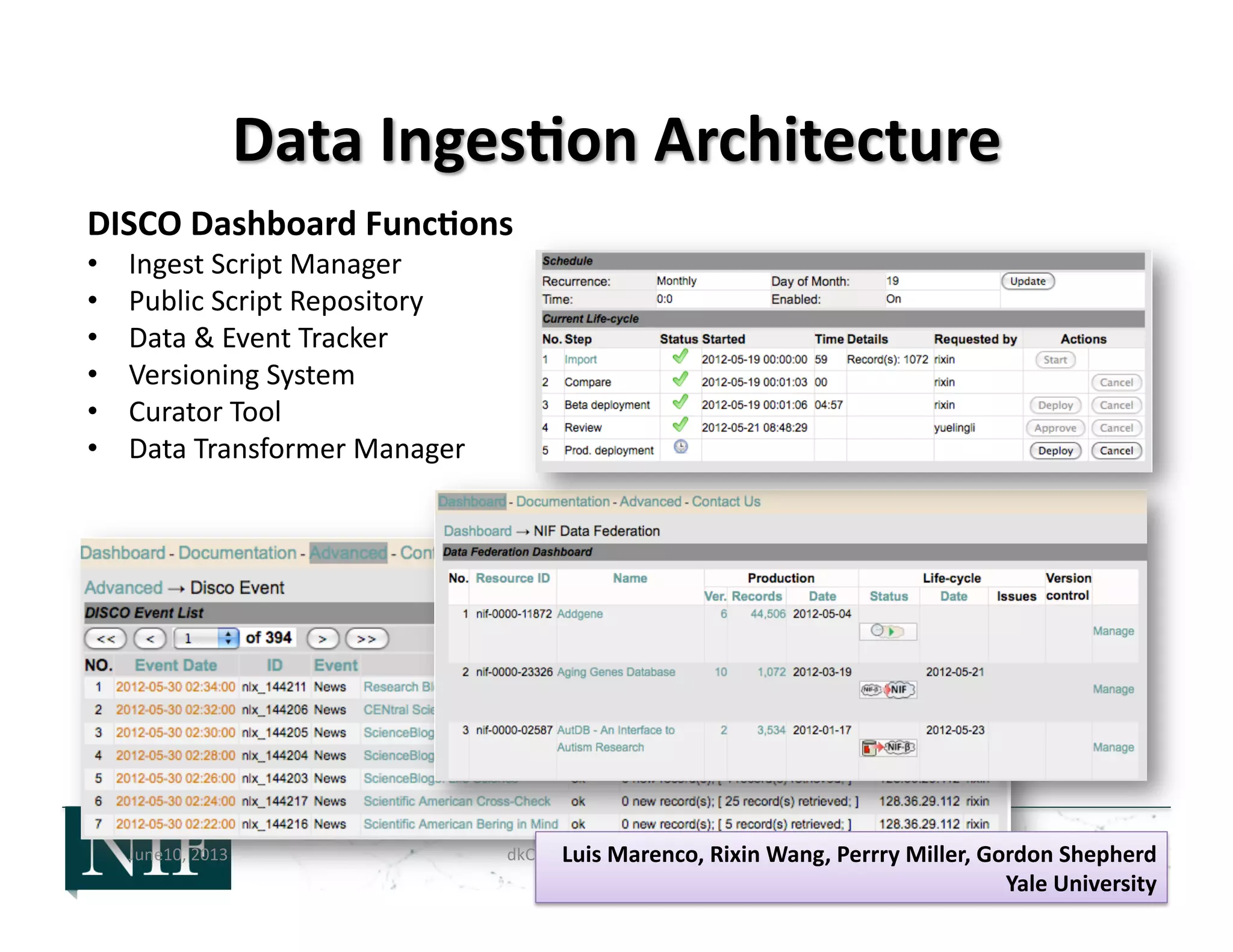
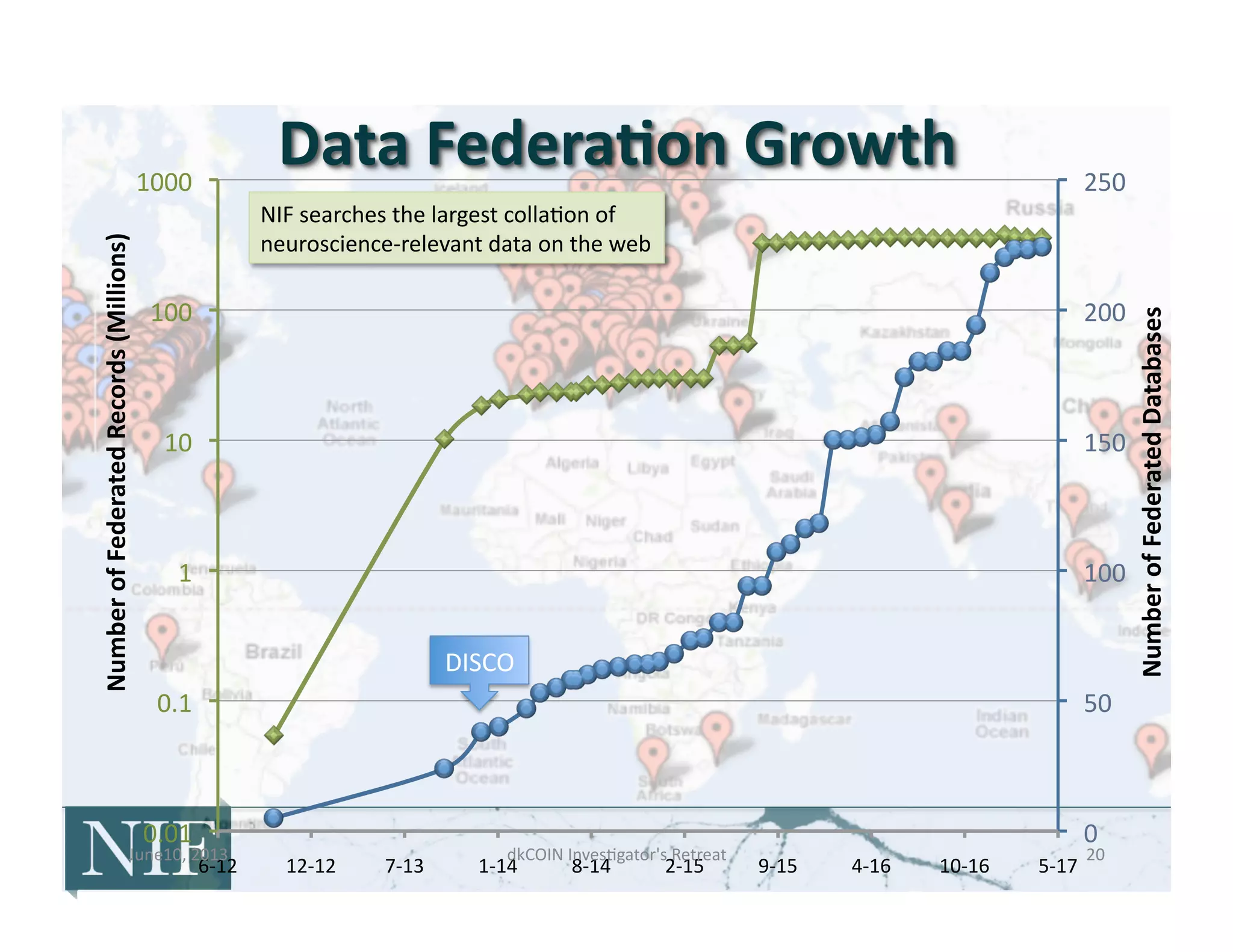
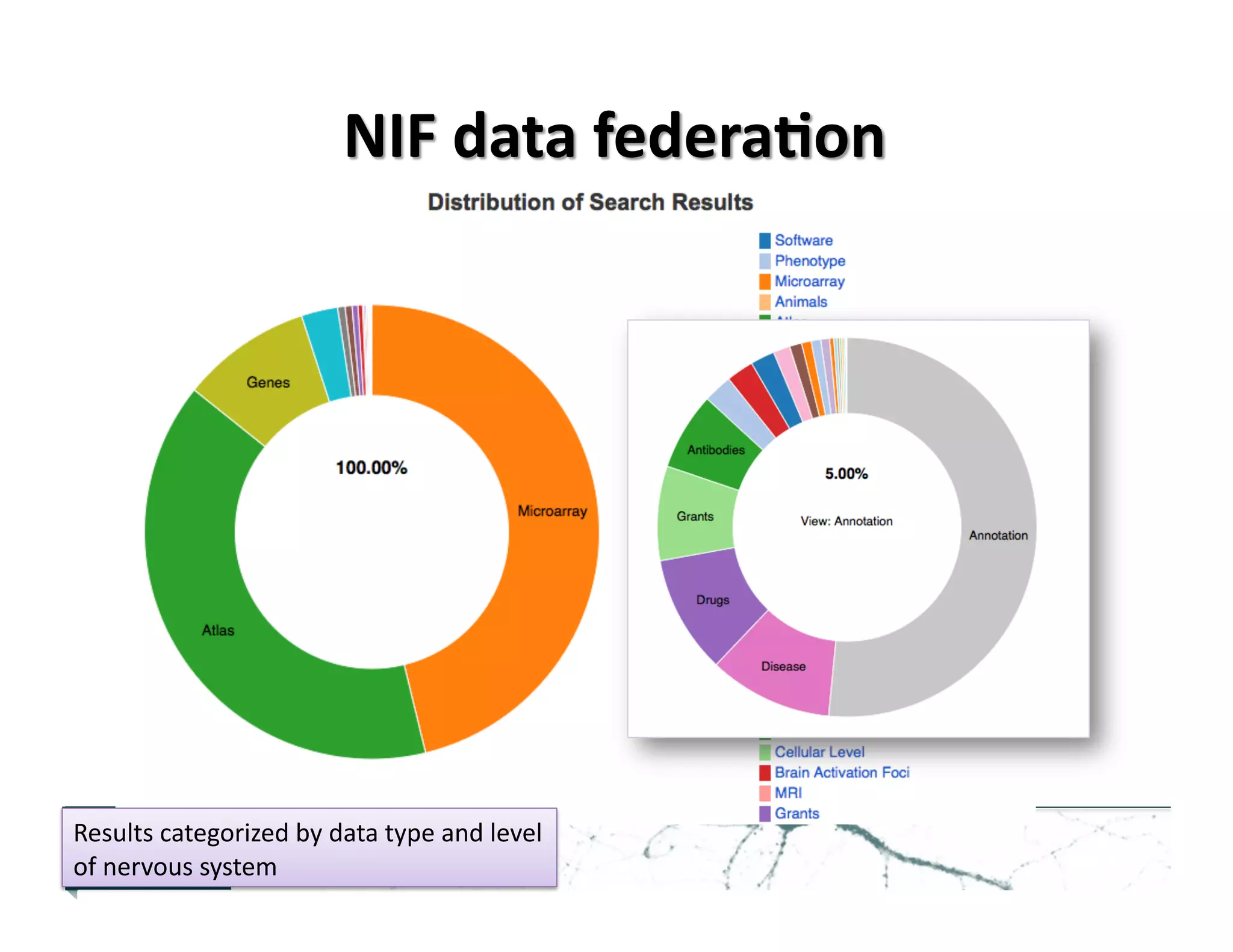
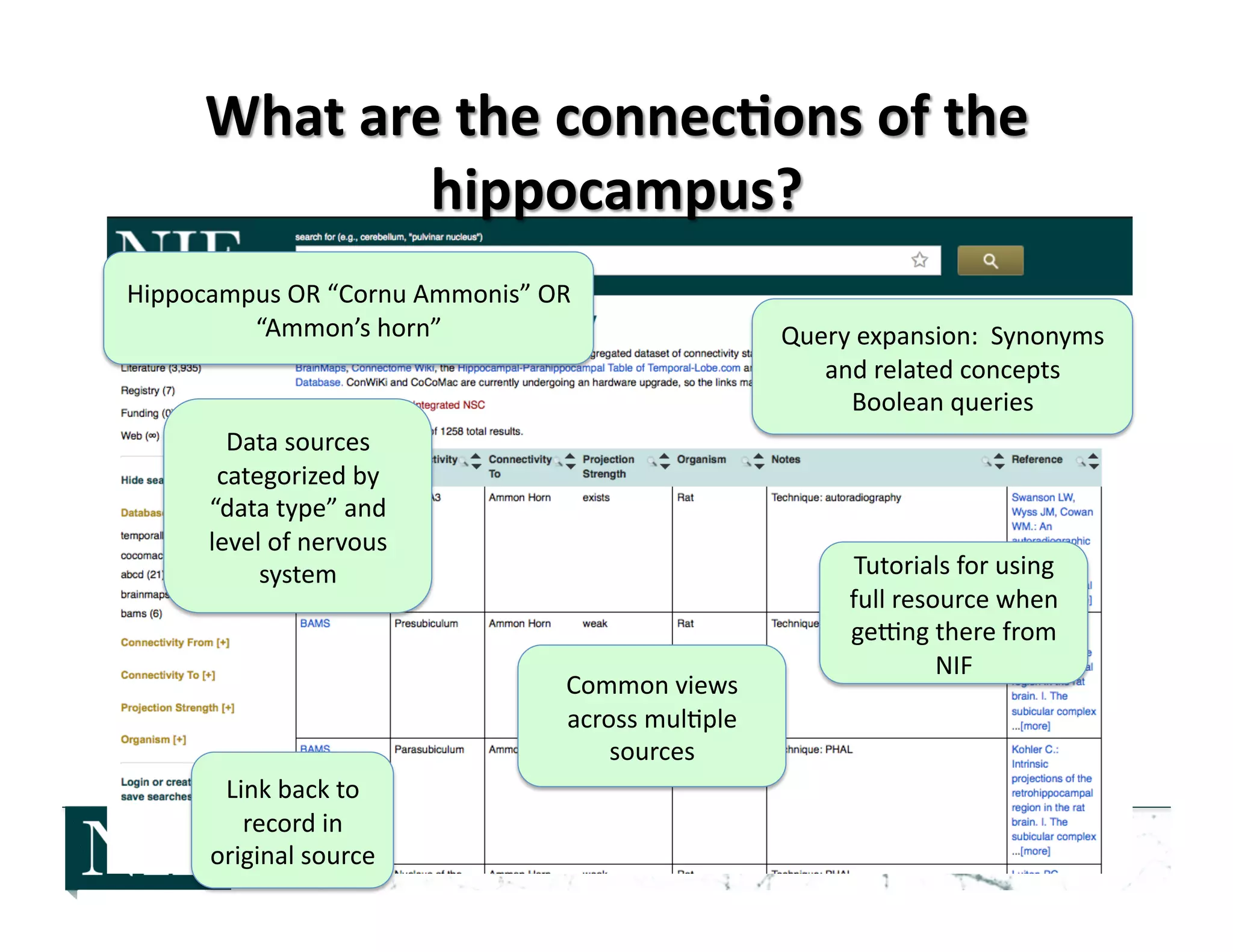
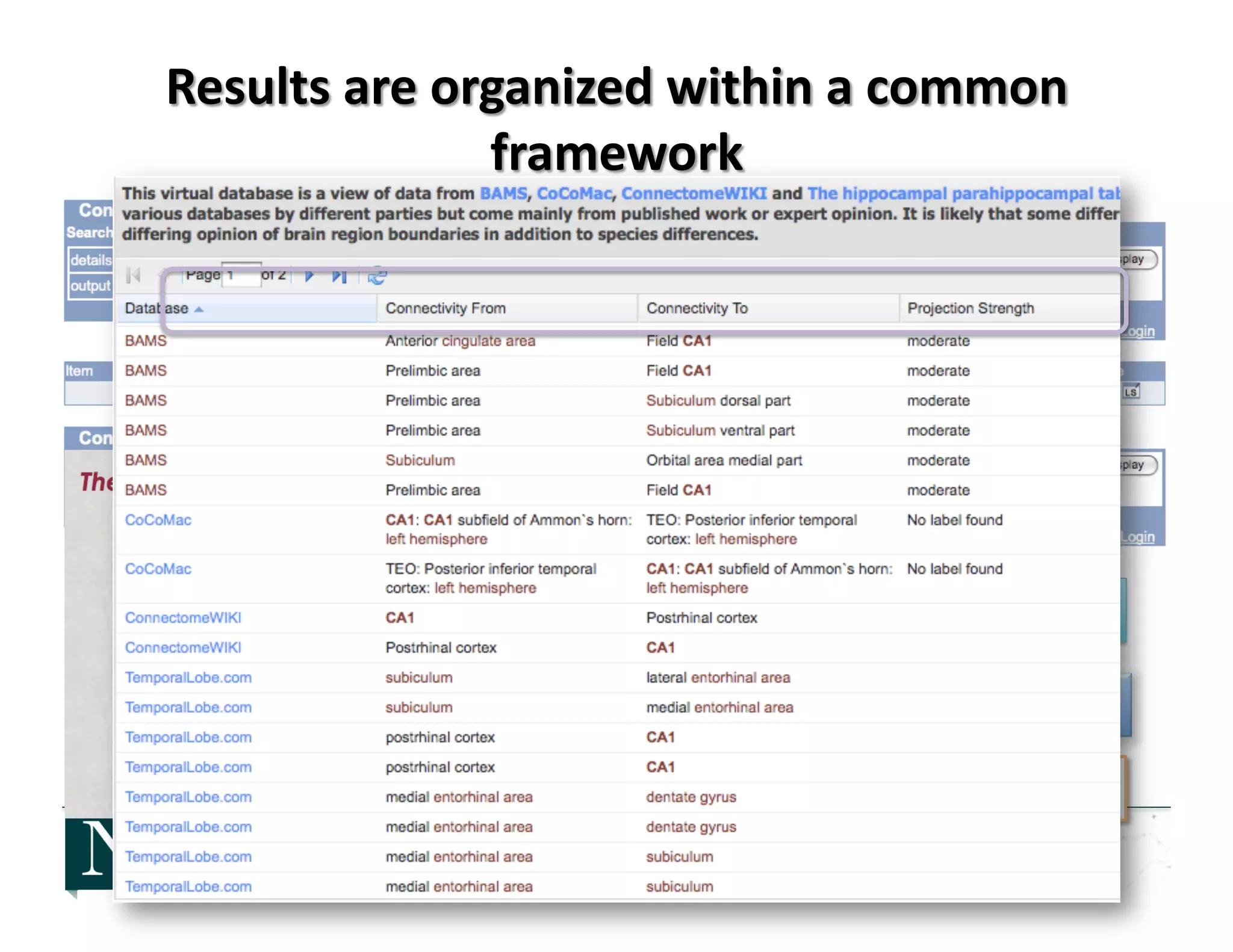



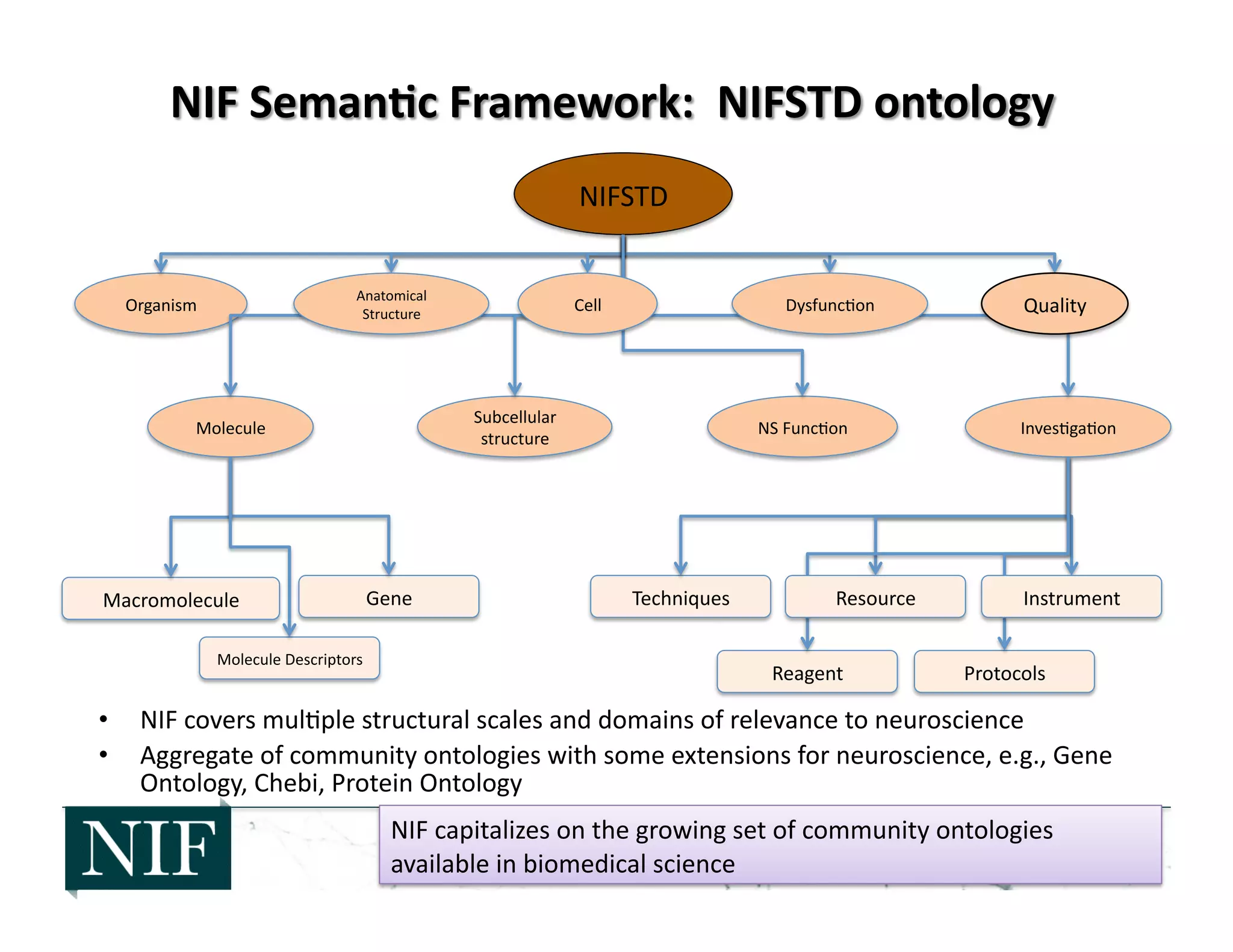
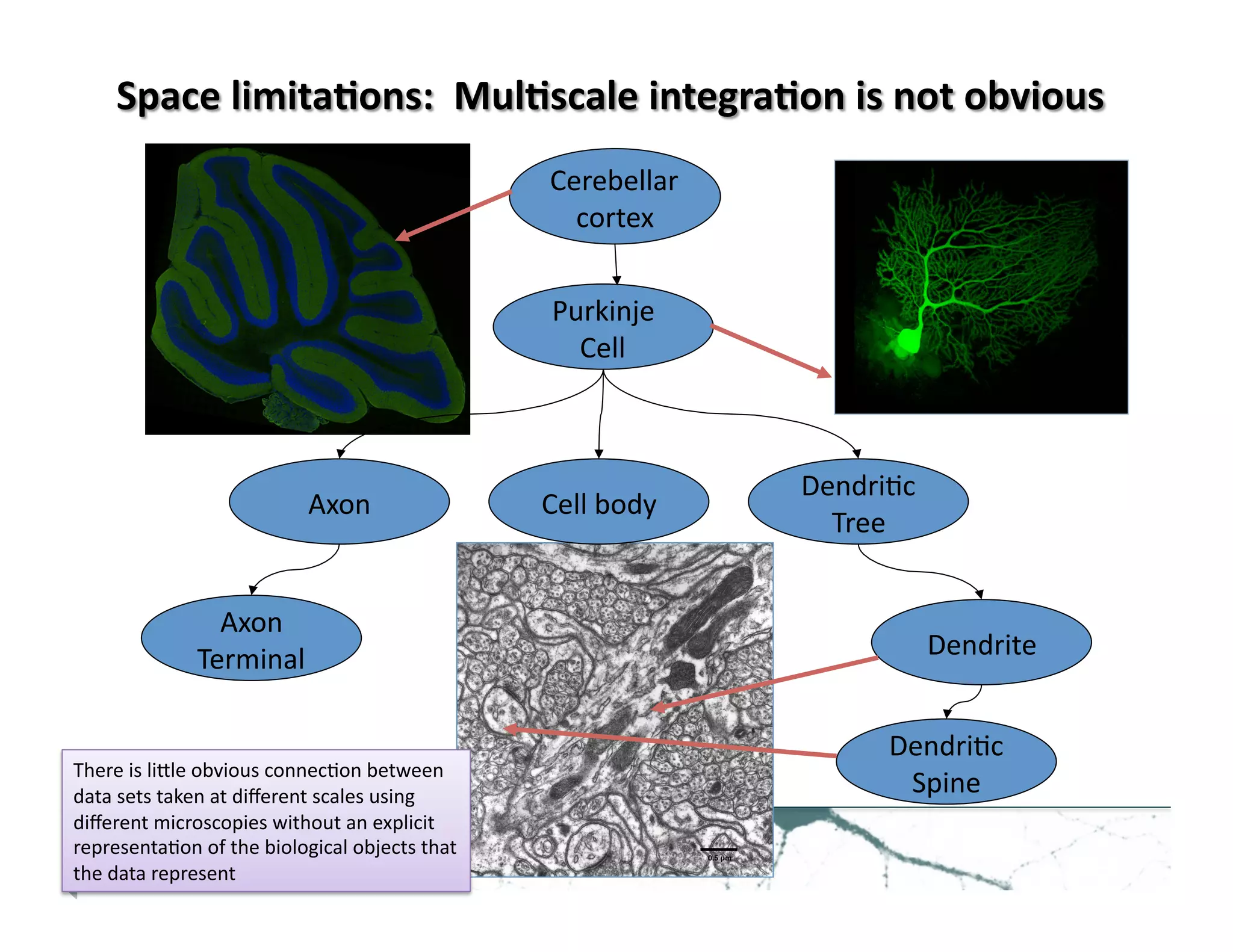


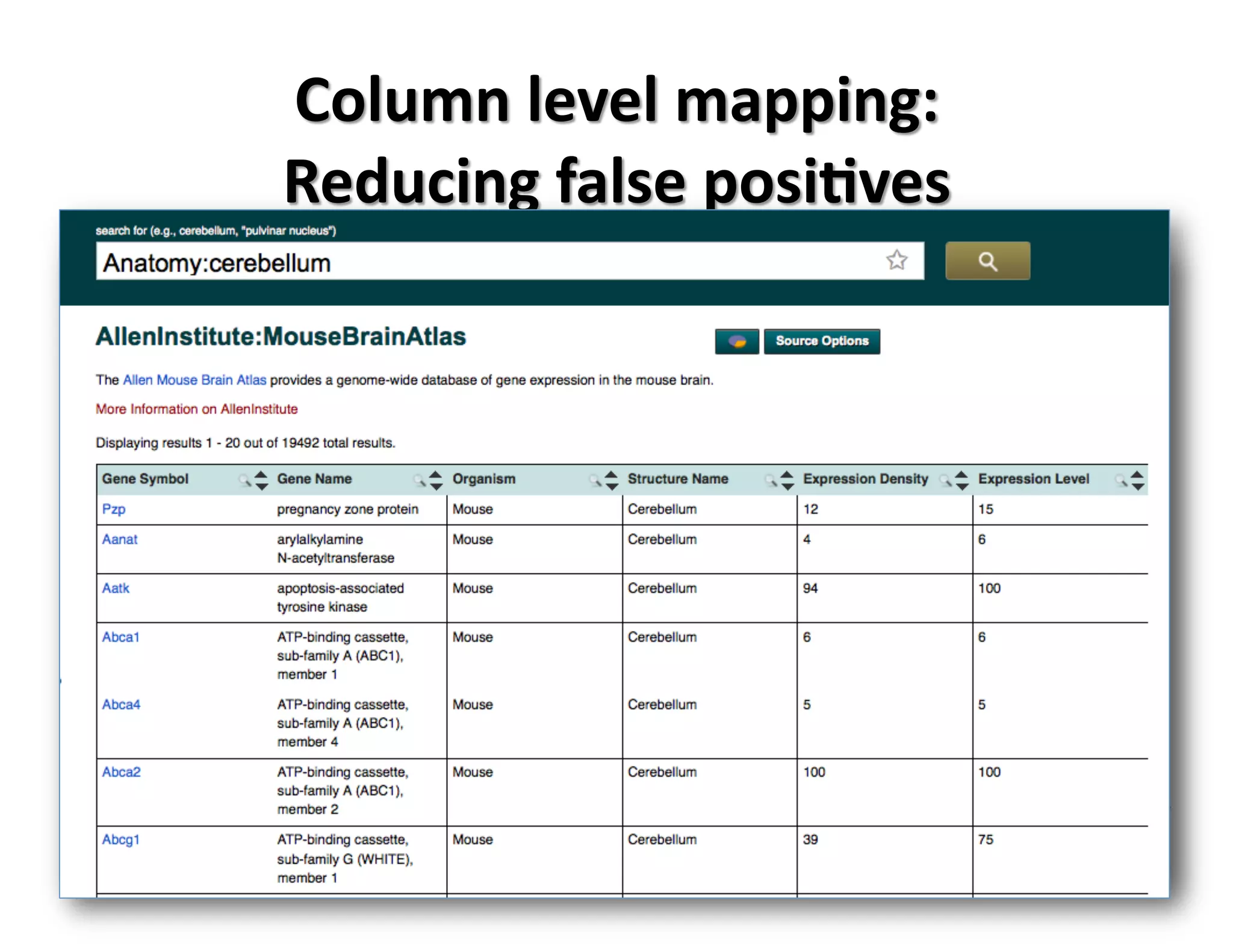




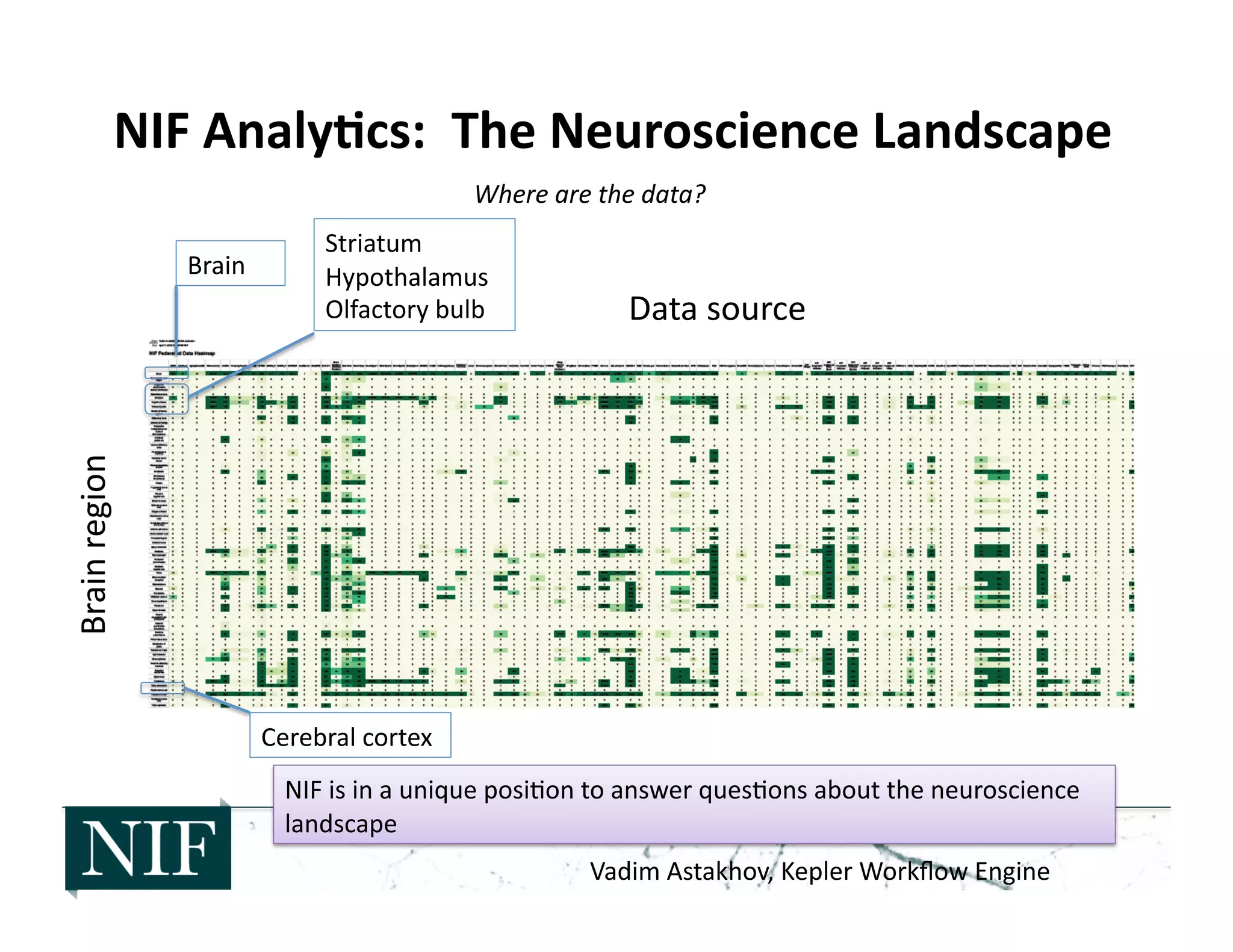


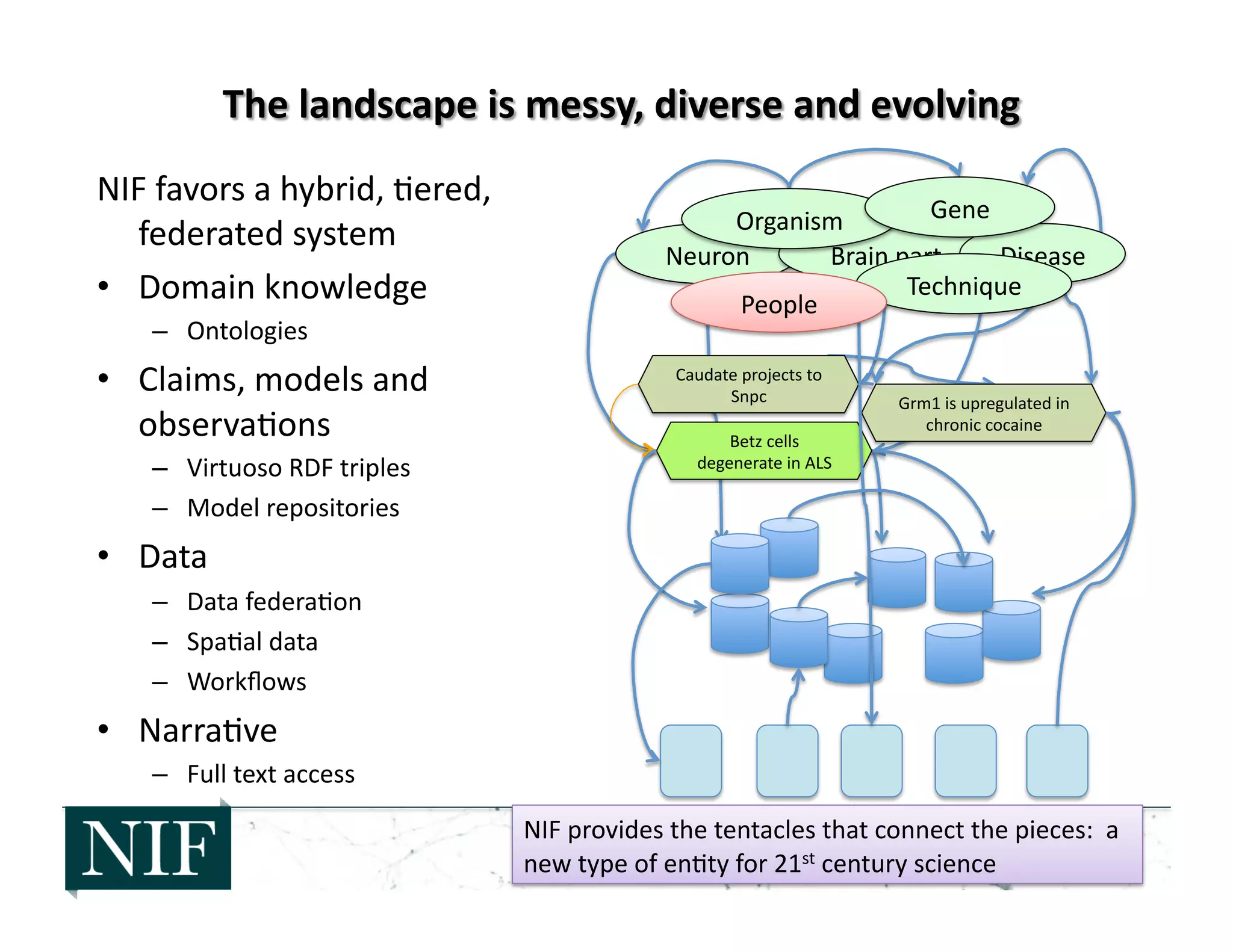
![• 2006-‐2008:
A
survey
of
what
was
out
there
• 2008-‐2009:
Strategy
for
resource
discovery
– NIF
Registry
vs
NIF
data
federa>on
– Inges>on
of
data
contained
within
different
technology
pla]orms,
e.g.,
XML
vs
rela>onal
vs
RDF
– Effec>ve
search
across
seman>cally
diverse
sources
• NIFSTD
ontologies
• 2009-‐2011:
Strategy
for
data
integra>on
– Unified
views
across
common
sources
– Mapping
of
content
to
NIF
vocabularies
• 2011-‐present:
Data
analy>cs
– Uniform
external
data
references
• 2012-‐present:
SciCrunch:
unified
biomedical
resource
services
NIF
provides
a
strategy
and
set
of
tools
applicable
to
all
domains
grappling
with
mul>ple
sources
of
diverse
data
(i.e.,
preZy
much
everything)](https://image.slidesharecdn.com/ecsite-130818192348-phpapp01-130819091758-phpapp02/75/Neurosciences-Information-Framework-NIF-An-example-of-community-Cyberinfrastructure-for-the-Neurosciences-40-2048.jpg)

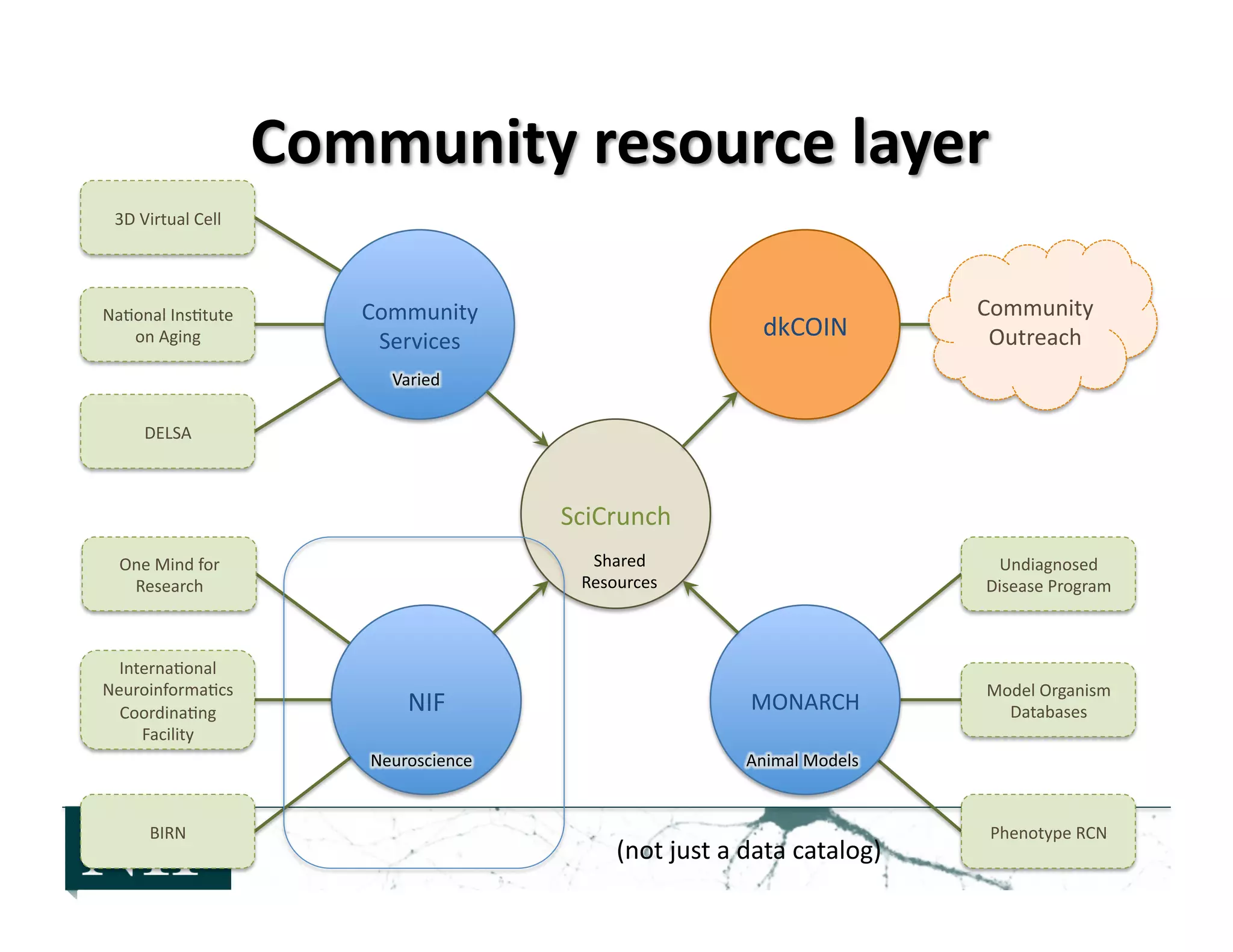

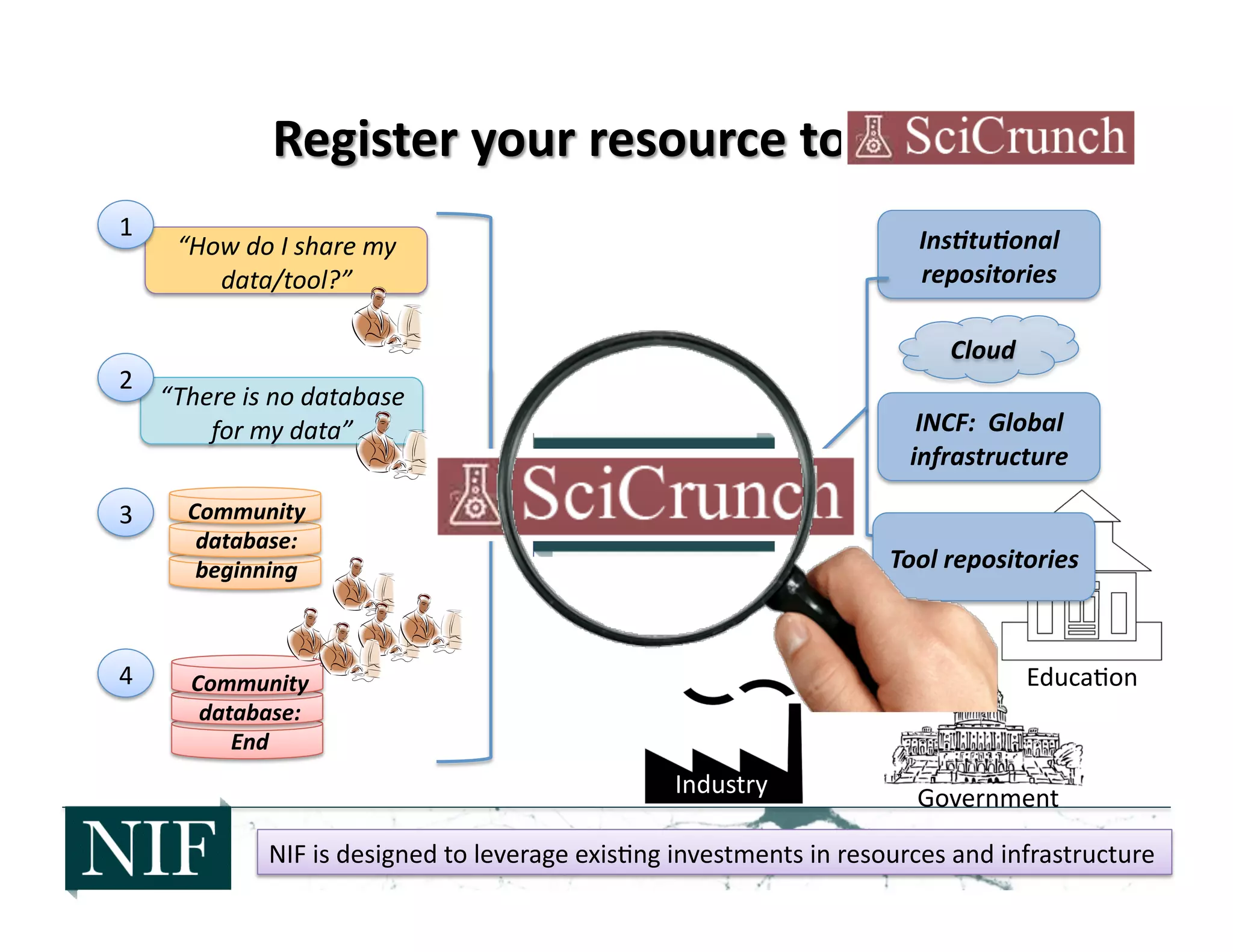




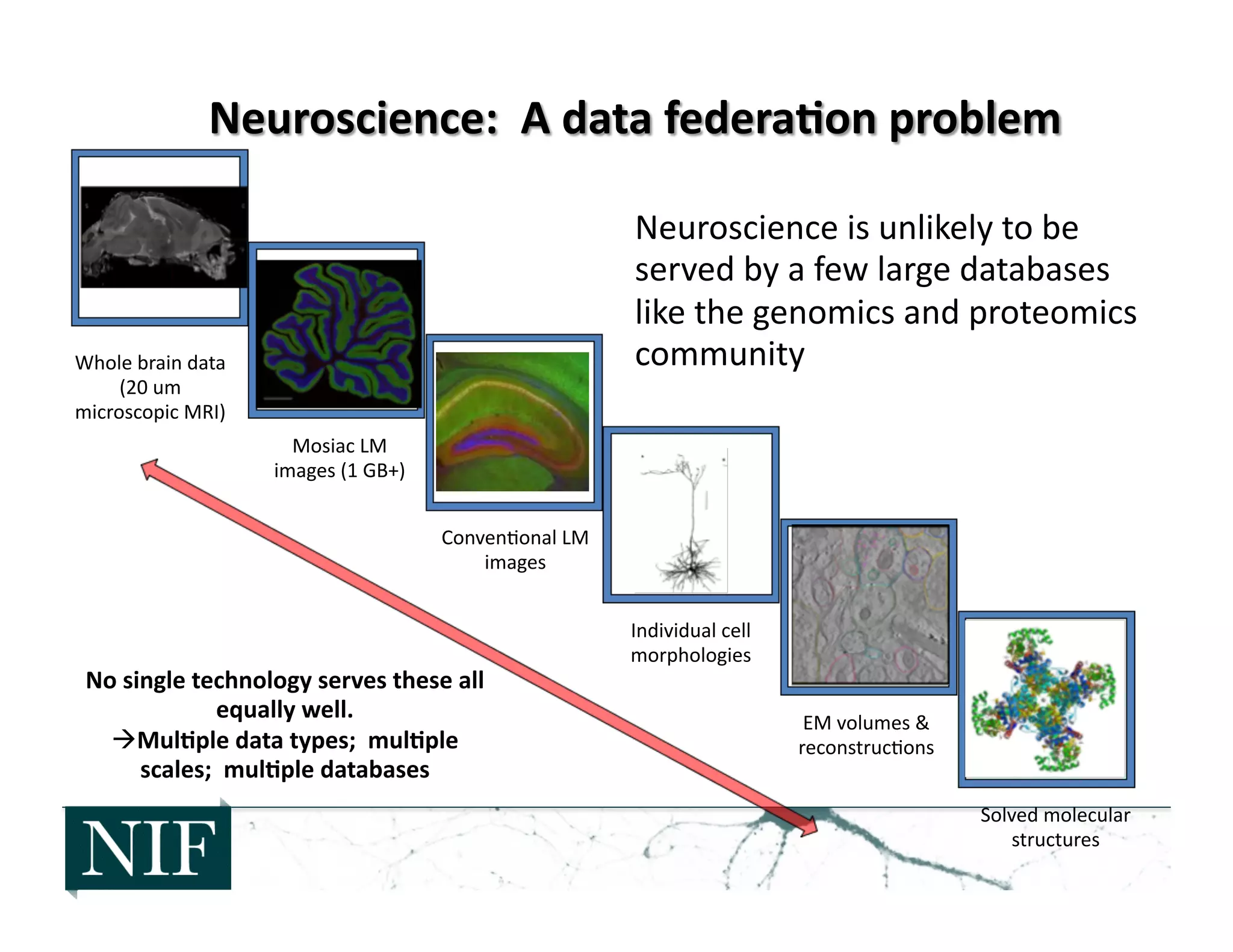
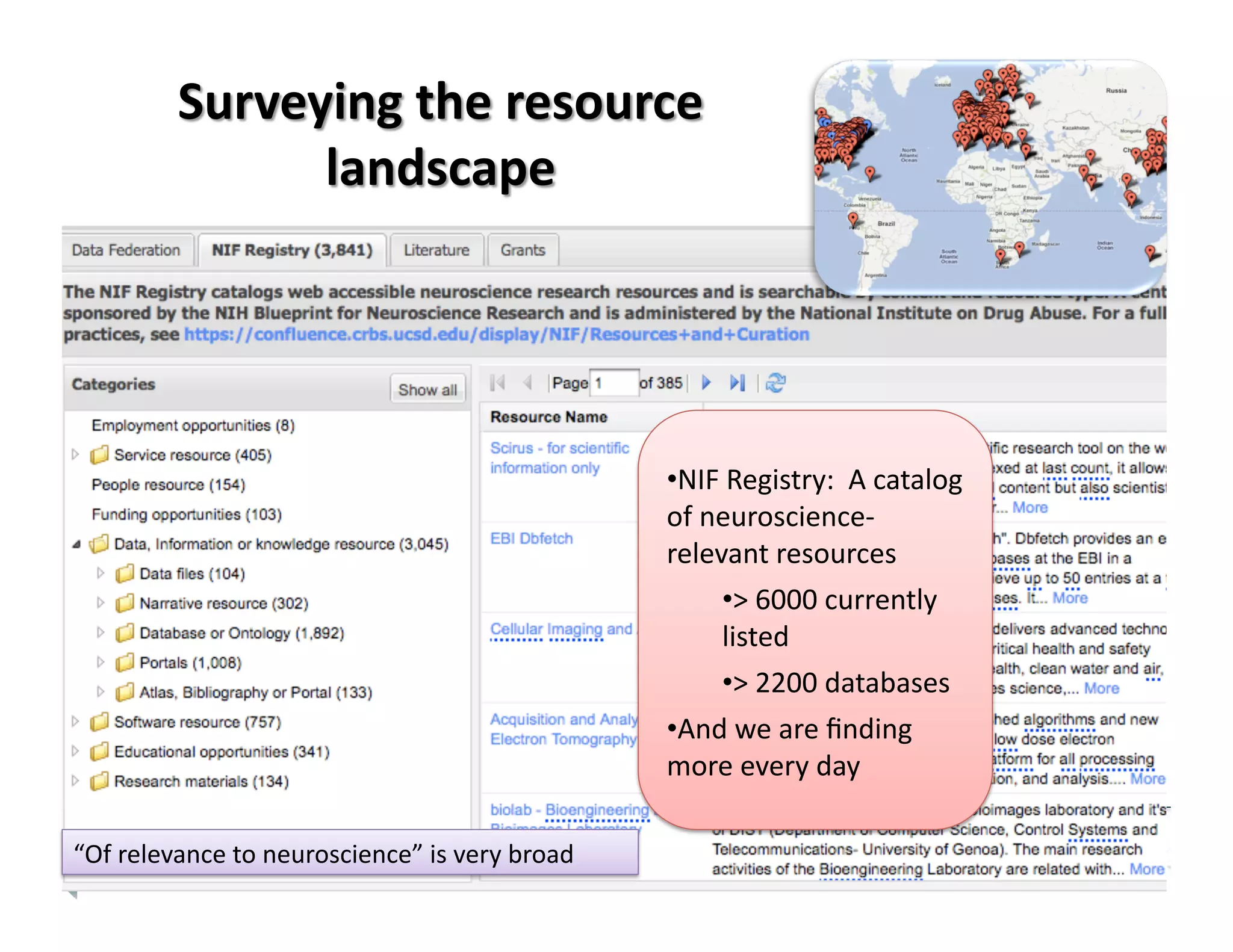
The document discusses the challenges of managing and analyzing the large amounts of neuroscience data being generated. It notes that currently, about half of researchers only store their data locally in their labs instead of in shared databases or archives. This prevents other researchers from accessing and using the data. The National Information Forum (NIF) is working to address these issues by creating a registry of neuroscience resources and developing technologies to allow researchers to discover, share, analyze and integrate data from various sources. NIF's registry currently catalogs over 6000 resources, including 2200 databases. The goal is for NIF to help the neuroscience community better exploit existing data and prepare for future increases in data.











































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)















