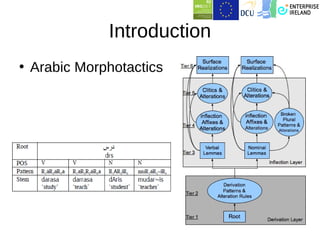
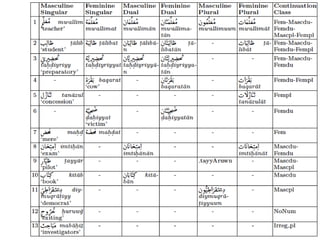
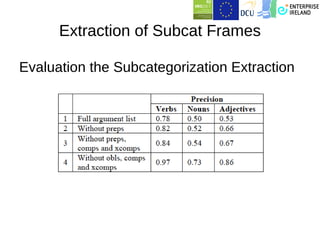
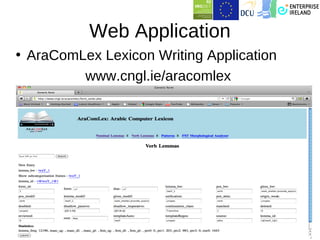
This document summarizes work on building a lexical database for Modern Standard Arabic. It describes extracting entries from corpora and annotating them with morphological and syntactic details like inflection paradigms and subcategorization frames. Machine learning was used to automatically extend the database by predicting features for new words and extracting subcategorization frames from treebanks. A web application was also created for lexicography work. The work has produced several open-source Arabic language resources.